Vector search and keyword search solve different retrieval problems. Vector search, also called dense retrieval, is useful when a query and a document use different words but have similar meaning. Keyword search, often implemented with sparse retrieval methods such as BM25, is useful when exact terms, names, codes, phrases, or technical vocabulary matter. Hybrid search combines both approaches so an AI database can retrieve results that are semantically related while still respecting exact-word precision.
This guide explains how vector search and keyword search work, why dense and sparse retrieval behave differently, where each method is strong or weak, and why hybrid search is often the most practical default for retrieval-augmented generation, documentation search, enterprise knowledge search, and other AI database use cases.
What Keyword Search Does Well
Keyword search looks for lexical overlap between the words in a query and the words in stored content. In a traditional full-text search system, the database builds an inverted index that maps terms to the documents or chunks where those terms appear. When a user searches for a phrase, the system can quickly find content that contains those words and rank the matches using a relevance formula such as BM25.
BM25 is a common sparse retrieval method because it rewards documents that contain important query terms while accounting for term frequency and document length. In plain language, it asks whether the searched words appear, how distinctive those words are across the collection, and whether the match is unusually concentrated in a given document or chunk.
Why It Is Called Sparse Retrieval
Keyword search is often described as sparse retrieval because each document can be represented as a very large vector with one possible dimension for each term in the vocabulary. Most documents use only a tiny fraction of all possible terms, so most values are empty or zero. The representation is sparse because it focuses on the words that actually appear.
Strengths of Keyword Search
- Exact-term precision: Keyword search is excellent when the query contains a product code, error message, legal clause, function name, ticket ID, medical term, or other phrase where the exact text matters.
- Transparency: It is usually easier to explain why a keyword result appeared because the matching terms are visible in the document.
- Efficient filtering and ranking: Inverted indexes are mature, fast, and well understood for large text collections.
- Strong handling of rare terms: Distinctive words and identifiers can carry high relevance because they appear in relatively few documents.
Weaknesses of Keyword Search
The main weakness of keyword search is that it depends heavily on shared vocabulary. If the user searches for “account recovery” but the most useful document says “reset user credentials,” a keyword system may miss the document or rank it too low. Keyword search can also struggle with synonyms, paraphrases, ambiguous wording, and questions that describe a concept without using the terms that appear in the source material.
Keyword search gives strong control over exact language, but that control comes with a tradeoff: it can be too literal. The next question is what happens when the user knows what they mean but does not know the exact words used in the database. That is where vector search becomes useful.
What Vector Search Does Well
Vector search retrieves content by comparing the meaning of a query to the meaning of stored documents or chunks. Instead of relying only on visible word overlap, an embedding model converts text into dense numerical vectors. Texts with similar meaning are placed near each other in vector space, so a query can match relevant content even when the wording differs.
For example, a user might search for “how to stop customers from leaving” while the best document discusses “reducing churn.” A vector search system can often connect those two ideas because the embedding model has learned that the phrases are semantically related. This makes vector search especially useful for natural-language questions, conceptual search, recommendations, and retrieval-augmented generation workflows where users ask in everyday language.
Why It Is Called Dense Retrieval
Vector search is commonly called dense retrieval because each embedding is a compact vector where most dimensions contain meaningful numeric values. Unlike sparse keyword vectors, dense vectors do not map directly to individual words. They encode patterns of meaning learned by the embedding model, which is why they can capture similarity between different phrases.
Strengths of Vector Search
- Semantic matching: Vector search can find related content even when the query and document use different words.
- Better handling of natural language: It works well for longer, conversational, or question-like queries because it searches for meaning rather than exact term overlap alone.
- Useful retrieval for RAG: It can surface passages that answer a user question even when the passage is phrased differently from the question.
- Flexible similarity search: The same general method can support text, images, code, audio, or multimodal retrieval when the right embeddings are available.
Weaknesses of Vector Search
Vector search is not always precise enough for exact-term queries. If a user searches for “ERR-8492,” “Section 12.4,” “acetaminophen,” or a specific database column name, semantic similarity may retrieve content that feels related but does not contain the exact term. This can be frustrating in technical, legal, medical, financial, and operational contexts where a single term can change the meaning of the result.
Vector search can also be harder to debug. A result may appear because the embedding model judged it semantically close, but the reason is not always obvious from the words on the page. Dense retrieval quality also depends on the embedding model, the chunking strategy, the distance metric, and the shape of the source data.
Vector search solves many cases where keyword search is too literal, but it introduces a different risk: it can be too approximate. To understand why neither method is enough by itself, it helps to look closely at the vocabulary-mismatch problem and the exact-term precision problem.
The Vocabulary-Mismatch Problem
The vocabulary-mismatch problem happens when the user and the document describe the same idea with different words. This is one of the oldest problems in information retrieval, and it becomes especially visible in AI applications because users often search conversationally. They may ask for a concept, symptom, goal, or task without knowing the official terminology used in the indexed content.
For example, a support user might search for “why did my payment fail?” while the internal article uses the phrase “card authorization declined.” A keyword search engine may miss or under-rank the article if the query terms do not overlap strongly with the document terms. A dense vector search engine is more likely to retrieve it because the two phrases describe a similar situation.
Vocabulary mismatch is one of the strongest arguments for vector search. It helps retrieval systems understand intent, not just wording. This is especially valuable when content is written by experts but searched by non-experts, or when different teams use different language for the same process.
Still, semantic flexibility is not the same as correctness. If a query contains a precise term, the system should not ignore it just because another passage has a related meaning. The other side of the retrieval problem is exact-term precision.
The Exact-Term Precision Problem
The exact-term precision problem appears when the literal words in the query are not optional. In many search experiences, a user includes a specific term because that term is the target. They may be searching for a named regulation, an error string, a software class, a drug name, an invoice number, or a part identifier. In those cases, a result that is semantically similar but missing the exact term may be less useful than a narrower keyword match.
Keyword search is strong here because exact terms directly affect the score. Rare terms can be especially important because they sharply narrow the candidate set. If only three chunks contain a specific error code, those chunks should usually receive strong consideration, even if a dense embedding model finds other passages that discuss similar errors in general language.
Dense retrieval can sometimes preserve exact terms through the embedding, but it is not designed to be a reliable exact-match mechanism. Embeddings compress text into meaning-oriented vectors, so rare strings, identifiers, numbers, and symbolic tokens may lose some of their retrieval force. That does not make vector search weak; it means vector search is solving a different problem.
Once the difference is clear, the practical conclusion follows naturally. Keyword search protects exact language. Vector search expands beyond exact language. Real AI database workloads usually need both.
Dense vs Sparse Retrieval: The Practical Difference
Dense and sparse retrieval are not just two names for the same search behavior. They use different representations, indexes, scoring methods, and failure modes. Sparse retrieval usually depends on term-based signals, while dense retrieval depends on learned semantic representations. Understanding that distinction helps teams choose the right retrieval strategy instead of assuming one method is universally better.
How Sparse Retrieval Thinks About Relevance
Sparse retrieval asks whether important query terms appear in a document and how strongly those terms should contribute to ranking. It tends to reward exact overlap, rare terms, and concentrated matches. This makes it strong for queries where the wording itself carries meaning.
How Dense Retrieval Thinks About Relevance
Dense retrieval asks whether the query and document are close in an embedding space. It tends to reward semantic similarity, paraphrase matching, and conceptual closeness. This makes it strong for queries where the user expresses intent rather than exact terminology.
Why The Tradeoff Matters
The important point is that dense retrieval and sparse retrieval make different kinds of mistakes. Sparse retrieval may miss a relevant passage because it uses different words. Dense retrieval may include a passage because it feels semantically related even though it lacks a required exact term. A good retrieval design accounts for both error patterns.
This is why the best retrieval system is often not the one that picks a single winner between keyword and vector search. In many AI database use cases, the stronger design is to run both retrieval paths and combine their evidence.
Why Hybrid Search Combines Both
Hybrid search combines keyword retrieval and vector retrieval so the system can use both lexical and semantic signals. A common pattern is to run a sparse search such as BM25 and a dense vector search in parallel, then merge the candidate results with a fusion method. The final ranking can reward documents that match the exact words, documents that match the meaning, or documents that do both.
This matters because real queries are mixed. A user may ask, “How do I fix ERR-8492 during password reset?” The phrase “password reset” is semantic and could match articles about account recovery, credential updates, or login troubleshooting. But “ERR-8492” is exact and should not be treated as just another approximate concept. Hybrid search lets the system preserve both signals.
Common Hybrid Search Patterns
- Score fusion: The system normalizes keyword and vector scores, then combines them into one ranking.
- Rank fusion: The system combines ranked lists from different retrieval methods, often using a method such as reciprocal rank fusion.
- Candidate generation plus reranking: The system retrieves a broader set of candidates from keyword and vector search, then uses a reranker to sort the most promising results.
- Query-adaptive weighting: The system gives more weight to keyword search for short, exact, or identifier-heavy queries and more weight to vector search for broad natural-language questions.
Why Hybrid Search Is Useful For RAG
Retrieval-augmented generation depends on sending the right context to a language model. If retrieval misses the best passage, the generated answer may be incomplete or wrong even if the model itself is capable. Hybrid search improves the odds that the retrieved context includes both semantically relevant passages and exact matches for critical terms.
Hybrid search is not a cure for every retrieval problem. Chunking, metadata filters, query rewriting, reranking, permissions, freshness, and evaluation all still matter. But hybrid search gives an AI database a broader retrieval base, which is especially useful when the content includes a mix of natural language, technical terms, names, numbers, and structured references.
After understanding why hybrid search works, the next practical question is when each approach should be preferred. The answer depends on the query type, the content type, and the cost of missing either semantic meaning or exact wording.

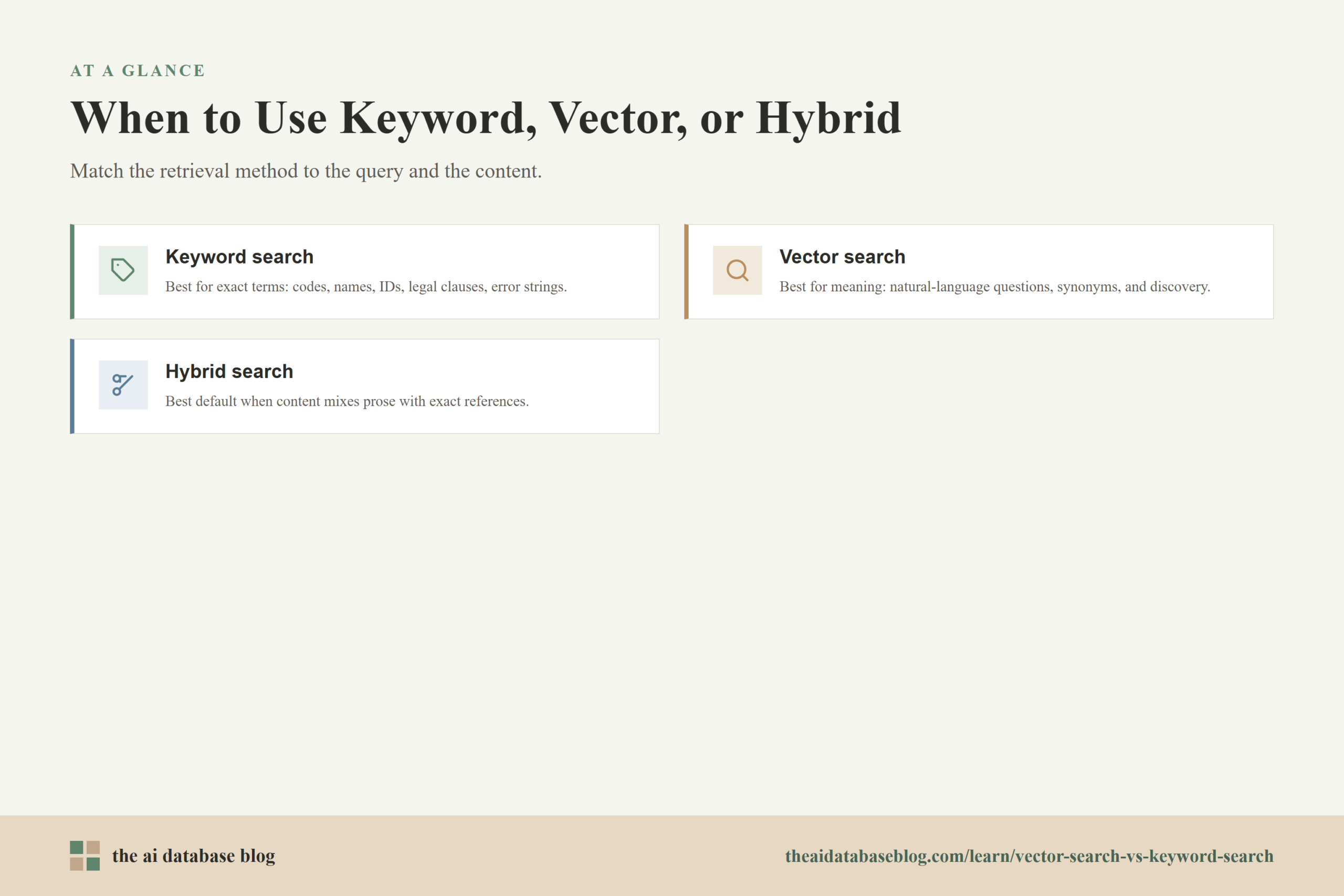
When To Use Keyword, Vector, Or Hybrid Search
The right retrieval method depends on what users are searching for and what kind of content is stored in the AI database. A simple consumer FAQ may benefit from vector search because users ask varied natural-language questions. A legal archive, codebase, or incident database may need keyword search because exact terminology is essential. Many real systems sit between those extremes, which is why hybrid search is often the most balanced starting point.
Use Keyword Search When Exact Wording Matters
Keyword search is a strong choice for known-item lookup, documentation terms, error messages, names, numbers, IDs, legal clauses, product SKUs, and other exact tokens. It is also useful when users expect visible term highlighting and explainable matches.
Use Vector Search When Meaning Matters More Than Wording
Vector search is a strong choice for semantic discovery, question answering, recommendations, support content, and knowledge bases where users may not know the official language. It is especially helpful when the system needs to connect intent to content written in different words.
Use Hybrid Search When Both Matter
Hybrid search is a strong default for AI database applications that serve varied queries. It is useful when the content contains a blend of natural language and exact references, such as developer documentation, customer support knowledge bases, research collections, internal policies, product catalogs, and RAG systems.
Choosing a retrieval method is not only a design decision; it is also an evaluation decision. Teams should test retrieval quality with real queries and inspect where each method fails. That evaluation usually reveals whether the system needs more semantic recall, more exact precision, stronger filters, better chunking, or a reranking step.
How To Evaluate Retrieval Quality
Retrieval quality should be measured with representative queries, not assumptions about which search method should win. A useful evaluation set includes short exact queries, broad natural-language questions, synonym-heavy queries, identifier-heavy queries, and ambiguous queries. The goal is to see which method retrieves the content a user actually needs.
Common retrieval metrics include recall at a fixed result count, precision at a fixed result count, mean reciprocal rank, and human relevance judgments. For RAG applications, teams should also inspect whether the retrieved passages provide enough context for a correct answer. A passage can be topically related but still insufficient for generation if it lacks the specific fact, instruction, or constraint needed by the user.
Evaluation often shows that the best setup is not a single retrieval method but a pipeline. A practical pipeline may use metadata filters to restrict the search space, hybrid retrieval to gather candidates, reranking to improve order, and feedback loops to tune weights or chunking. The exact design should reflect the content and the user tasks rather than a generic preference for one retrieval style.
FAQs
1. Is vector search better than keyword search?
Vector search is better for semantic similarity, but it is not always better overall. Keyword search is often better for exact terms, identifiers, names, and precise phrases. The stronger choice depends on the query and the content.
2. What is the difference between dense and sparse retrieval?
Dense retrieval uses compact embeddings where most dimensions contain learned meaning signals. Sparse retrieval uses large term-based representations where most dimensions are empty and the active dimensions usually correspond to words or learned lexical features.
3. Why does keyword search struggle with vocabulary mismatch?
Keyword search struggles with vocabulary mismatch because it relies on word overlap. If the query says “cancel subscription” and the document says “terminate membership,” a purely lexical system may not recognize that the two phrases refer to a similar intent.
4. Why does vector search sometimes miss exact terms?
Vector search can miss exact terms because embeddings compress text into semantic representations. That compression is useful for matching meaning, but rare strings, codes, numbers, and specialized terms may not always dominate the similarity score.
5. What is hybrid search in an AI database?
Hybrid search is a retrieval approach that combines keyword search and vector search. It usually retrieves candidates through both sparse and dense methods, then merges or reranks the results so the final list reflects both exact wording and semantic meaning.
6. Do all RAG systems need hybrid search?
Not all RAG systems need hybrid search, but many benefit from it. If users ask natural-language questions and also search for exact terms, hybrid search usually gives a more reliable retrieval base than either keyword search or vector search alone.
Takeaway
Vector search and keyword search are complementary retrieval methods, not interchangeable replacements. Keyword search is strongest when exact words, rare terms, and visible lexical matches matter, while vector search is strongest when the user and the content express the same idea in different language. Hybrid search combines dense and sparse retrieval so AI database applications can handle both semantic discovery and exact-term precision, making it especially useful for RAG, documentation search, support knowledge bases, and other systems where users need accurate context from varied queries.
Watch this video to learn more