Vector databases help large language model applications find the right information before the model generates an answer. They store embeddings, search for similar meanings, filter results by metadata, and return context that an LLM can use for retrieval-augmented generation, agent memory, recommendations, support tools, and knowledge assistants. The key distinction is that an embedding model turns content into vectors for search, while an LLM uses retrieved context to reason, write, summarize, or take the next step in a workflow.
This guide explains where vector databases fit in the LLM stack, how vector search powers modern AI applications, and why embedding models and LLMs should be understood as separate components. By the end, readers should understand the core architecture, the main tradeoffs, and the questions to ask when designing retrieval for LLM-powered systems.
Where Vector Databases Fit in the LLM Stack
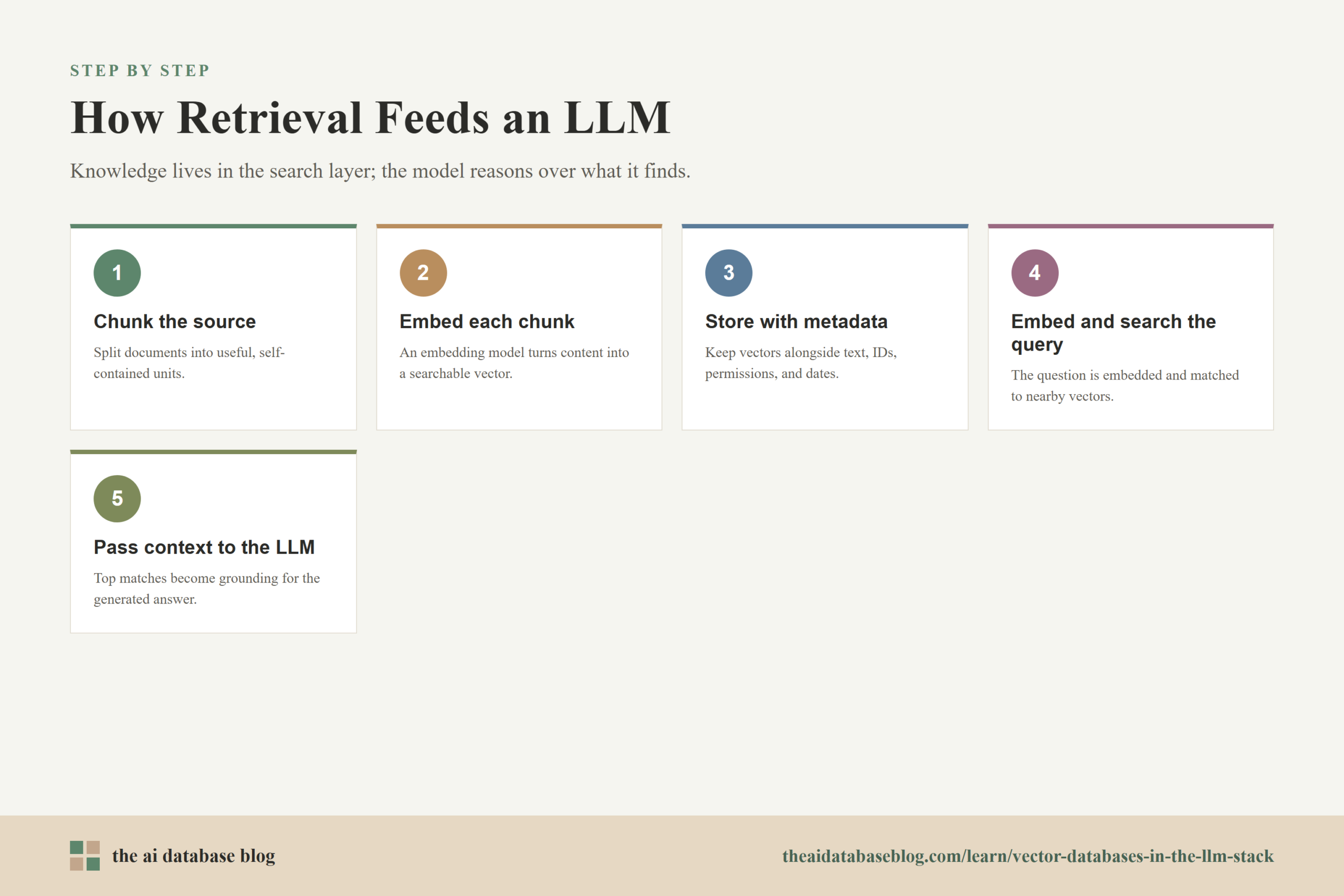
An LLM stack usually has more than one model and more than one data system. The language model is the most visible part because it produces the final response, but the quality of that response often depends on what happens before generation begins. A vector database sits in the retrieval layer, where it stores searchable representations of documents, records, messages, product information, code snippets, support tickets, or other knowledge that the application may need later.
The basic flow starts with source data. That data is split into useful units, often called chunks, and each chunk is passed through an embedding model. The embedding model converts the text or other content into a vector, which is a list of numbers that captures semantic patterns. The vector database stores that vector alongside the original text, document identifiers, timestamps, permissions, categories, and other metadata that can help the system retrieve the right content later.
When a user asks a question, the application embeds the query with a compatible embedding model and searches the vector database for nearby vectors. The closest matches are treated as likely relevant context. The application can then pass those retrieved passages into the LLM, usually with instructions about how to answer, cite, summarize, compare, or reason from the provided information.
This structure matters because the LLM does not need to memorize every private document or recent update. Instead, the system can keep knowledge in a searchable retrieval layer and use the LLM as the reasoning and generation layer. That separation is one of the main reasons vector databases became important infrastructure for LLM applications.
How Vector Search Powers LLM Applications
Vector search powers LLM applications by matching meaning rather than only matching exact words. Traditional keyword search is strong when users know the right terms, product names, or document titles. Vector search is useful when users describe an idea in natural language, use different wording from the source material, or ask a question that needs semantically related context rather than exact phrase overlap.
For example, a support assistant may receive a question such as, “Why is my invoice total different from the estimate?” The relevant policy document may never use that exact sentence. It may talk about usage-based billing, proration, credits, taxes, or plan changes. Vector search can help retrieve conceptually related passages even when the words are not identical.
In an LLM application, retrieval is not just a search feature. It shapes what the model sees. If retrieval returns strong evidence, the LLM has a better chance of producing a grounded answer. If retrieval returns weak, stale, or irrelevant context, the model may produce a confident but poorly supported response. This is why retrieval quality is often one of the main bottlenecks in production LLM systems.
Common LLM Application Patterns That Use Vector Search
Vector search appears in many patterns that look different at the user interface level but share a similar retrieval foundation. The details vary by application, but the same basic question keeps returning: what information should the model see before it answers or acts?
- Question answering: The system retrieves relevant documentation, policies, or knowledge base passages before generating an answer.
- Document analysis: The system finds related sections across long files so the LLM can summarize, compare, or extract information without reading every token at once.
- Search and discovery: The system uses natural language queries to find products, media, cases, records, or internal knowledge that may not share exact keywords with the query.
- Personalization: The system retrieves user preferences, historical interactions, or relevant prior context when the application needs memory.
- Agent workflows: The system retrieves task instructions, examples, tool outputs, prior attempts, or environment facts that help an agent choose the next action.
Once vector search is understood as a context-selection layer, the next important question is which model is responsible for creating that searchable context. This is where many beginners mix up embedding models and LLMs, even though they serve different purposes in the stack.
Embedding Models Are Not the Same as LLMs
An embedding model and an LLM can both be based on machine learning, and both may process natural language, but they are used for different jobs. An embedding model converts input into a vector so that similar meanings can be compared mathematically. An LLM generates or transforms language based on a prompt and context. In a retrieval system, the embedding model helps find information, while the LLM helps use that information.
The distinction is practical, not just academic. If the embedding model does a poor job representing the domain, retrieval may miss the right evidence even if the LLM is strong. If the LLM is weak at following instructions or synthesizing retrieved context, the system may still produce poor answers even when retrieval succeeds. Good LLM applications treat retrieval and generation as separate parts that each need design, testing, and monitoring.
What the Embedding Model Does
The embedding model is responsible for turning text, images, code, or other supported content into vectors. These vectors are not meant to be read by humans. They are meant to preserve enough semantic structure that the database can compare one item with another. When a query vector is close to a document vector, the system treats that document as a possible match.
Embedding quality depends on the model, the domain, the language, the content type, and the way the content is chunked. A general-purpose embedding model may work well for broad knowledge retrieval, while a more specialized model may work better for code, legal documents, biomedical text, multilingual content, or product catalogs. The right choice depends on what the application must retrieve accurately.
What the LLM Does
The LLM receives the user request, instructions, and retrieved context. It may answer a question, write a summary, generate a comparison, decide whether more retrieval is needed, call a tool, or ask a clarifying question. The LLM is the component that turns retrieved information into a useful response or action.
Because LLMs can generate fluent language even when context is incomplete, they should not be treated as a replacement for retrieval. A strong LLM can improve synthesis, but it cannot reliably answer from private or changing information unless that information is made available at generation time. The vector database helps provide that information in a controlled and repeatable way.
Why the Distinction Matters for System Design
Understanding the difference helps teams debug problems more effectively. If the system retrieves the wrong passages, the issue may involve chunking, embeddings, indexing, filtering, or ranking. If the system retrieves the right passages but gives a poor answer, the issue may involve prompt design, context formatting, reasoning, instruction following, or output evaluation.
This distinction also affects cost and performance. Embedding models are often used during ingestion and query time. LLMs are usually used during generation and can be more expensive per request. A well-designed stack avoids sending unnecessary context to the LLM by using retrieval, filtering, and ranking to keep the prompt focused.
After the model roles are clear, the next step is understanding what the vector database itself must do well. It is not only a place to store vectors; it also affects latency, relevance, access control, freshness, and the overall reliability of the retrieval layer.
What a Vector Database Does Beyond Storing Vectors
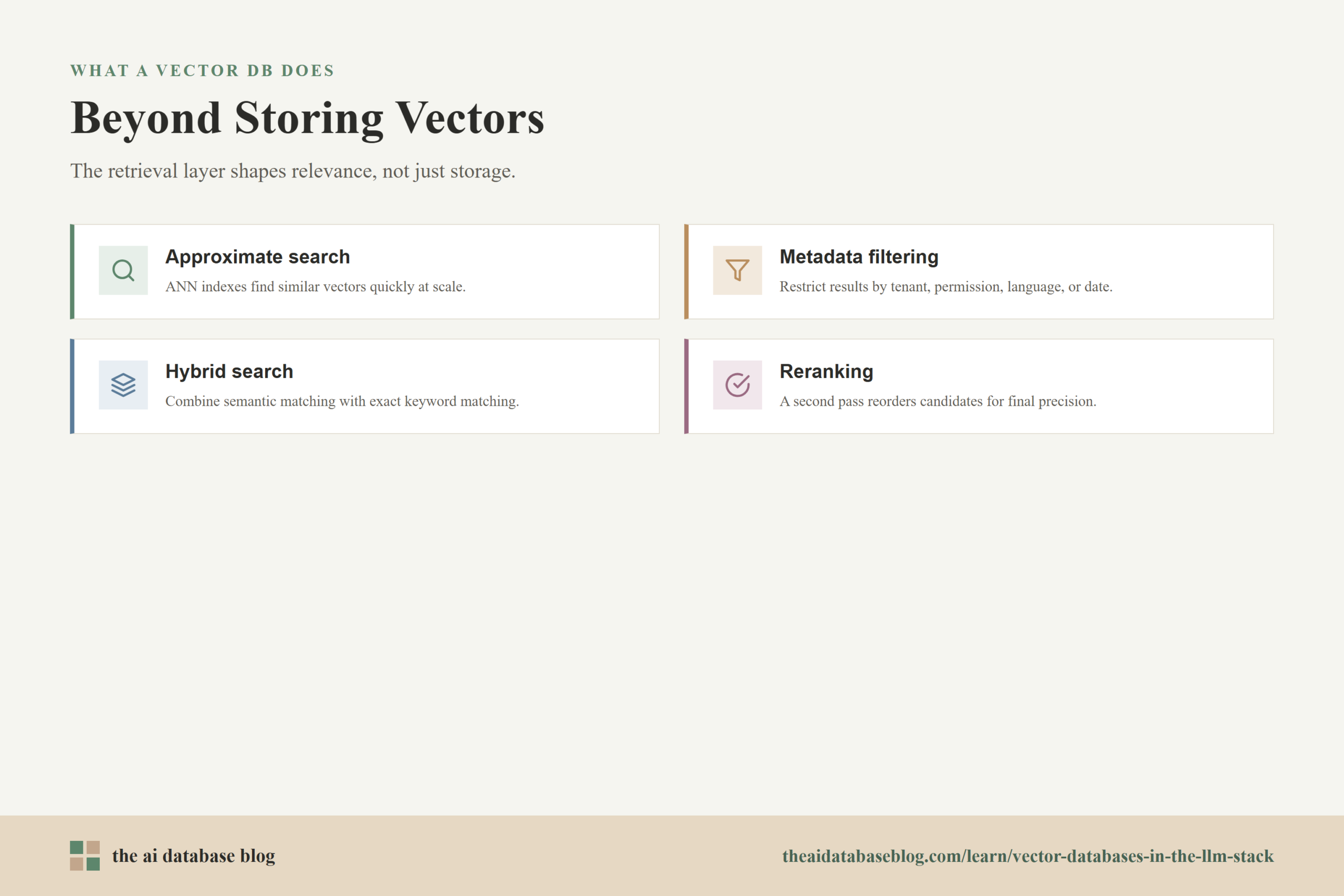
A vector database stores embeddings, but its real value comes from making those embeddings usable in applications. It needs to ingest data, index vectors, search quickly, apply metadata filters, return the original content, and support updates as knowledge changes. In production, these operational details often matter as much as the search algorithm itself.
Most vector databases use approximate nearest neighbor search to find similar vectors efficiently at scale. Exact comparison across every vector can become too slow as datasets grow. Approximate indexes trade a small amount of exactness for much faster retrieval. That tradeoff is usually acceptable when the system can rerank results, retrieve a larger candidate set, or combine vector search with other signals.
Metadata Filtering
Metadata filtering lets an application narrow the search space before or during retrieval. A query may need to search only documents from a specific customer account, only records the user is allowed to see, only content in a certain language, or only files updated after a certain date. Without metadata filtering, vector similarity alone can return content that is semantically relevant but operationally wrong.
Filtering is especially important for enterprise and multi-tenant systems. A support agent, internal assistant, or customer-facing chatbot may need strict permission boundaries. The retrieval layer should help enforce those boundaries instead of relying only on the LLM to ignore content it should not use.
Hybrid Search
Hybrid search combines vector search with keyword or lexical search. This is useful because semantic similarity and exact term matching solve different problems. Vector search can find conceptually related material, while keyword search can preserve precision for names, part numbers, error codes, regulation IDs, product SKUs, and other exact strings.
Many strong retrieval systems use hybrid search because user queries are mixed. Some are conceptual, some are exact, and many contain both. A query like “refund policy for enterprise plan cancellation after 30 days” may benefit from semantic matching around refund rules and exact matching around plan names or time windows.
Reranking
Reranking is a second-stage relevance step. The system first retrieves a set of candidate results, then uses another model or scoring method to reorder them based on a more careful comparison between the query and each candidate. Reranking can improve precision when the first retrieval pass returns many plausible but uneven results.
Reranking is not a cure for poor data preparation, but it can help when the corpus is large, the query is nuanced, or the top vector matches are semantically close but not equally useful. It is often part of a mature retrieval pipeline because the first nearest-neighbor search is optimized for speed, while reranking is optimized for final relevance.
These retrieval capabilities become most visible in RAG, where the purpose of search is not simply to display results but to feed grounded context into a language model. That makes RAG the natural next topic in the learning path.
Roadmap Article: RAG and the Retrieval Layer
The first follow-up topic should explain retrieval-augmented generation as the core pattern that connects vector databases to LLM outputs. RAG is the architecture most readers need to understand before they can reason clearly about advanced retrieval, agent memory, or evaluation. It answers a simple but powerful question: how can an LLM use external knowledge without retraining the model every time knowledge changes?
A strong RAG article should begin with the end-to-end flow: ingest content, chunk it, embed it, store it, retrieve it, assemble context, generate an answer, and optionally cite sources. It should explain that RAG is not a single product or one fixed pipeline. It is a design pattern with many choices that affect relevance, latency, cost, and trust.
Questions the RAG Article Should Answer
- What problem does RAG solve compared with relying only on the LLM’s training data?
- How do chunking, embeddings, vector search, metadata filters, and prompt construction work together?
- When should a system use vector search, keyword search, hybrid search, or reranking?
- How can teams reduce hallucinations without claiming that RAG eliminates them completely?
- What should teams monitor when a RAG system starts serving real users?
The RAG layer establishes how an application retrieves knowledge for a single user request. Once that foundation is in place, readers can understand why agents need retrieval too, but often in a more dynamic and iterative way.
Roadmap Article: Agents and Retrieval Memory
The second follow-up topic should explain how vector databases support agentic systems. An agent is not just a chatbot that answers once. It may plan, call tools, inspect results, revise its plan, and continue across multiple steps. That makes retrieval more than a one-time context lookup. It can become working memory, long-term memory, tool memory, or a way to retrieve examples from previous tasks.
In agent systems, vector search can retrieve instructions, prior decisions, user preferences, successful task trajectories, failed attempts, code snippets, policy constraints, and external knowledge. The challenge is that agents often need to decide when to search, what to search for, whether the result is sufficient, and whether another retrieval step is needed. Retrieval becomes part of the agent’s reasoning loop rather than a fixed preprocessing step.
Questions the Agents Article Should Answer
- How is retrieval for agents different from retrieval for a single RAG answer?
- What kinds of memory can be stored in a vector database?
- How can agents retrieve examples, tool outputs, instructions, or prior experiences?
- What risks appear when an agent retrieves outdated, irrelevant, or permission-sensitive memory?
- How should teams decide what an agent is allowed to remember and reuse?
Agent retrieval raises a harder quality question than ordinary search: how do teams know whether the system found the right information and used it correctly? That question leads directly to evaluation, because retrieval systems cannot be improved reliably if their behavior is not measured.
Roadmap Article: Evaluating Vector Search and RAG Quality
The third follow-up topic should focus on evaluation because LLM applications are difficult to improve by intuition alone. A system can look good in a demo and still fail on edge cases, ambiguous queries, stale content, permission boundaries, or domain-specific language. Evaluation gives teams a way to measure whether retrieval is finding the right context and whether the LLM is using that context faithfully.
Evaluation should separate retrieval quality from answer quality. Retrieval quality asks whether the system found the right evidence. Answer quality asks whether the LLM used that evidence correctly, avoided unsupported claims, followed instructions, and produced a useful response. If these are measured together only as a single score, teams may struggle to identify which part of the stack needs improvement.
Retrieval Metrics to Explain
A practical evaluation article should introduce metrics such as recall at k, precision at k, mean reciprocal rank, context relevance, and latency. These metrics help teams understand whether relevant content appears in the retrieved set, how high it appears, and whether the search pipeline is fast enough for the user experience.
It should also explain that metrics require a test set. Teams need representative questions, expected supporting documents, and examples of difficult cases. Without test data, evaluation can drift into anecdotal checking, where teams remember the impressive examples and miss the failures.
Answer Metrics to Explain
Answer evaluation should cover groundedness, faithfulness, completeness, instruction following, and usefulness. A retrieved passage may contain the correct answer, but the LLM may still omit an important condition or overstate what the source says. That is why answer evaluation must inspect both the final response and the evidence available to the model.
Human review remains important, especially for high-stakes or domain-specific use cases. Automated evaluation can help scale testing and catch regressions, but it should be calibrated against human judgment. The goal is not to replace review entirely; it is to make quality visible enough that teams can improve the system deliberately.
With the roadmap in place, the final piece is to connect these topics back to architectural choices. Vector databases are important, but they work best when they are treated as one part of a broader retrieval system rather than as a magic accuracy layer.
Practical Architecture Guidance
Designing a vector database layer starts with the application goal. A customer support assistant, legal research tool, product search experience, code assistant, and agent memory system all need retrieval, but they do not need the same data model or evaluation process. The best architecture depends on the corpus, freshness requirements, permissions, query patterns, latency targets, and tolerance for mistakes.
Teams should begin by defining what the system must retrieve and why. If the application needs answers from long documents, chunking and citation quality may matter most. If it searches product inventory, metadata filters and exact identifiers may matter as much as semantic similarity. If it supports agents, memory lifecycle and permission boundaries become central design concerns.
Start With the Retrieval Unit
The retrieval unit is the piece of content the system stores and returns. It may be a paragraph, section, table row, support ticket, documentation page, product description, message, code function, or image description. If the unit is too small, the LLM may receive fragments without enough context. If it is too large, retrieval may become noisy and expensive because the model receives more text than it needs.
Good retrieval units usually preserve meaning, source traceability, and enough surrounding context to be useful. They should also carry metadata that helps the system filter and explain results. This is where data modeling and retrieval quality meet.
Use Hybrid Retrieval When Exact Terms Matter
Vector search is strong for meaning, but many real applications still depend on exact terms. Error codes, customer IDs, product SKUs, legal citations, file names, and technical identifiers may not behave well as pure semantic concepts. Hybrid retrieval helps cover both natural language meaning and exact matching.
The practical question is not whether vector search or keyword search is universally better. The better question is which signals the application needs for the query types it actually receives. Many production systems benefit from combining both.
Evaluate Before Scaling Complexity
It is tempting to add more components when retrieval feels weak: larger models, more chunks, more indexes, more prompts, more agents, and more rerankers. Some of those additions may help, but they can also make the system harder to reason about. Evaluation should come early enough that teams know which change improves which failure mode.
A simple test set can reveal whether problems come from missing data, poor chunking, weak embeddings, insufficient filters, bad ranking, or answer generation. That clarity helps teams make targeted improvements instead of repeatedly changing the whole stack.
FAQs
1. What is a vector database in an LLM stack?
A vector database is the retrieval layer that stores embeddings and searches for semantically similar content. In an LLM stack, it helps the application find relevant context before the language model generates an answer or takes an action.
2. Does a vector database replace an LLM?
No. A vector database retrieves information, while an LLM generates or reasons from information. They work together in many AI applications, but they solve different problems.
3. Is an embedding model the same thing as an LLM?
No. An embedding model converts content into vectors for search and comparison. An LLM generates text, summarizes information, follows instructions, or performs reasoning based on a prompt and context.
4. Why do RAG systems use vector databases?
RAG systems use vector databases to retrieve external knowledge that may not be in the LLM’s training data. This helps the model answer using current, private, or domain-specific information supplied at generation time.
5. When is hybrid search better than vector search alone?
Hybrid search is often better when queries include exact terms such as product codes, names, dates, error messages, or legal references. It combines semantic matching with keyword matching so the system can handle both meaning and exact wording.
6. How should teams evaluate vector search in LLM applications?
Teams should evaluate whether retrieval returns the right evidence and whether the LLM uses that evidence correctly. Useful checks include recall, ranking quality, context relevance, latency, groundedness, completeness, and human review for representative test questions.
Takeaway
Vector databases are a central part of the LLM stack because they help applications retrieve the right context before generation begins. Readers should now understand how vector search powers LLM applications, why embedding models and LLMs play different roles, and how the topic expands into RAG design, agent memory, and evaluation. This guidance is most useful for builders, technical writers, product teams, and data practitioners who need to explain or design AI systems that answer from private, changing, or domain-specific knowledge, such as a support assistant that retrieves policy documents before generating a customer-facing response.
Watch this video to learn more