Vector compression and quantization reduce the storage and memory footprint of AI database indexes by storing lower-precision versions of embeddings for search. Instead of keeping every vector dimension as a 32-bit floating-point value in the active index, the system can represent vectors with smaller numeric formats, compact codes, or binary values. This saves memory and can improve cache behavior, but it also introduces approximation, which means recall can drop unless the system retrieves extra candidates and re-scores them with full-precision vectors kept on disk.
This guide explains vector compression from the storage layer upward. It covers why embeddings become expensive to store, how quantization changes the representation of vectors, what happens to recall when precision is reduced, and how re-scoring with original vectors can recover better final rankings. By the end, you should understand how to reason about the memory-vs-recall trade-off when designing or tuning an AI database for large-scale retrieval.
Why Vector Storage Becomes Expensive
Vector search systems store embeddings, which are numeric representations of text, images, code, audio, products, or other data. Each embedding usually contains hundreds or thousands of dimensions, and each dimension is commonly stored as a floating-point number. A single vector is not large by itself, but vector databases are often built for millions, tens of millions, or hundreds of millions of objects. At that scale, the size of the vectors can dominate memory planning.
For example, a 768-dimensional embedding stored as 32-bit floating-point values uses 4 bytes per dimension. That means the raw vector alone needs 3,072 bytes before counting object metadata, index graph links, payload storage, deleted-record overhead, replication, or caching. Multiply that by 100 million objects and the raw vectors alone require hundreds of gigabytes. If the index is designed to keep vectors in memory for low-latency search, this becomes a direct infrastructure cost.
The storage problem is not only about disk capacity. Vector search is often limited by memory bandwidth, cache efficiency, and the amount of working data that can stay close to the CPU or accelerator during search. Smaller vector representations can make more candidates fit in memory, reduce data movement, and make each distance calculation cheaper. This is why compression is usually discussed as both a storage optimization and a performance optimization.
Once the storage cost is clear, the next question is what can safely be compressed. The answer is usually not the object itself or the meaning of the embedding, but the numeric representation used by the search index.
How Quantization Reduces Footprint at the Storage Layer
Quantization reduces footprint by replacing high-precision vector values with lower-precision representations. A full-precision vector might store every dimension as a 32-bit floating-point value. A quantized index might store each dimension as a 16-bit float, an 8-bit integer, a 1-bit binary value, or a compact code created by grouping dimensions into segments. The purpose is to keep enough information for approximate nearest-neighbor search while using far fewer bytes.
The simplest way to think about quantization is rounding. If a full-precision value can represent many tiny differences, a lower-precision value represents fewer possible states. The compressed version is cheaper to store and compare, but it is no longer an exact copy. In vector search, that small numeric change can alter distance calculations, especially when many candidates are close together in the embedding space.
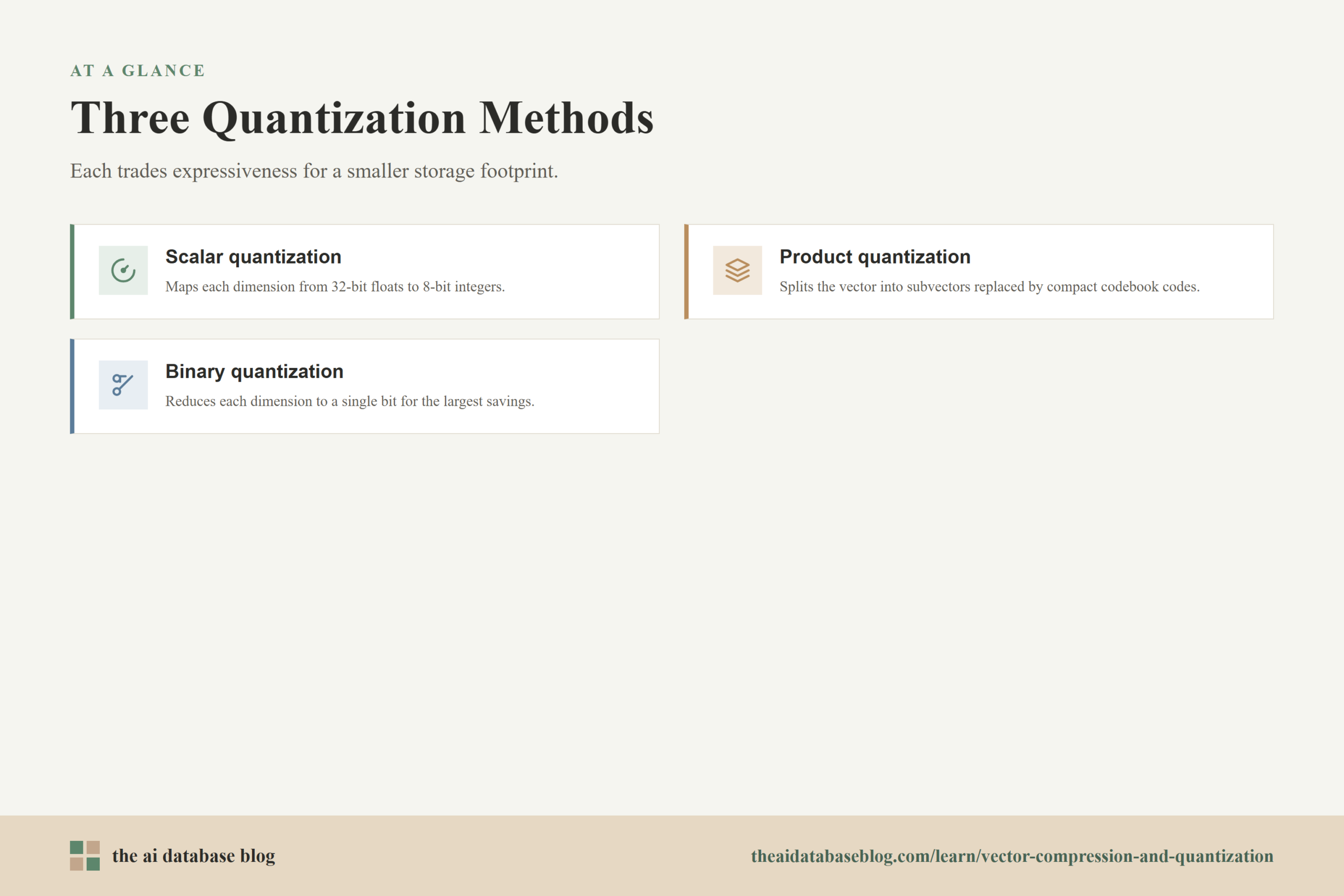
Scalar Quantization
Scalar quantization compresses each vector dimension independently. A common pattern is to map 32-bit floating-point values into 8-bit integer values. Because an 8-bit value takes 1 byte instead of 4 bytes, the vector portion of the index can be much smaller. This approach is relatively direct and often works well when the vector distribution is stable enough that each dimension can be mapped into a smaller range without losing too much useful information.
The storage-layer benefit is easy to understand: fewer bytes per dimension means more vectors can fit in memory. The practical question is whether the compressed distances still preserve the neighborhood relationships that matter for the application. If the top candidates are still close to the true nearest neighbors, scalar quantization can be a strong default option for large collections.
Product Quantization
Product quantization compresses a vector by splitting it into smaller subvectors, often called segments or subspaces, and replacing each segment with a compact code. Instead of storing every original dimension, the system learns representative patterns for each segment and stores identifiers for the closest learned pattern. This can produce much stronger compression than simply lowering the precision of every dimension.
From a storage view, product quantization changes the vector from a long array of floating-point numbers into a short sequence of codebook references. The codebooks themselves take some storage, but they are shared across many vectors, so the per-vector footprint can fall sharply. The trade-off is that product quantization usually requires training, tuning, and careful evaluation because the number of segments affects both memory use and recall.
Binary Quantization
Binary quantization compresses vector values into one-bit representations. This can create very large memory savings because each dimension can be represented as a single bit rather than a multi-byte number. It can also make comparisons very fast because binary operations are efficient.
The cost is that binary representations are much less expressive than full-precision vectors. They can work well for some datasets and embedding models, especially when the system can retrieve a larger candidate pool and refine the final ranking later. They can also perform poorly when small differences between vectors are important. Binary quantization is therefore best treated as a high-compression option that needs workload-specific testing.
These methods differ in how aggressively they compress vectors, but they share the same basic storage idea: keep a cheaper representation in the active search path, then decide how much precision is needed to return trustworthy results.
The Memory-vs-Recall Trade-off
The central trade-off in vector quantization is that lower memory use usually comes with some loss of recall. Recall measures whether the search system finds the true relevant neighbors that an exact full-precision search would have found. When the index uses compressed vectors, distance calculations are approximate, so some candidates may move slightly up or down in ranking. If a relevant result is pushed too far down or never enters the candidate set, recall falls.
This does not mean quantization is unsafe. It means compression should be tuned against the actual retrieval goal. Many AI applications do not require a perfect mathematical nearest-neighbor list. They need a useful candidate set for question answering, semantic search, recommendation, deduplication, or classification. A small recall drop may be acceptable if it reduces memory enough to make the system affordable and fast. In other workloads, such as compliance search or high-stakes support retrieval, even small misses may matter.
Several factors shape the trade-off. Higher-dimensional vectors may tolerate some compression because they contain redundant information, but they can also make approximation errors harder to reason about. Datasets with many near-duplicate or tightly clustered items may be more sensitive because small distance changes can reorder many candidates. The choice of similarity metric, index type, metadata filters, and top-k size can also change how visible quantization loss becomes.
Why Total Memory Savings May Be Smaller Than Raw Compression
It is important to separate raw vector compression from total index memory reduction. If a vector changes from 32-bit floats to 8-bit integers, the vector values themselves are four times smaller. But the full index may also include graph connections, posting lists, metadata references, object identifiers, deleted-entry handling, caches, and other structures. Those parts may not shrink when the vector values are quantized.
This is why a 4x reduction in vector bytes does not always produce a 4x reduction in total memory. The improvement is still valuable, but capacity planning should measure the complete index, not only the vector array. For graph-based indexes, graph links can be a major part of memory use. For systems with heavy metadata filtering, filter structures and payload access patterns can also affect the real footprint.
How Compression Can Affect Latency
Quantization can improve latency because smaller vectors reduce memory bandwidth pressure and may speed up distance calculations. More compressed data can fit in cache, and the search engine can scan or traverse candidates with less data movement. In large retrieval systems, memory movement is often as important as arithmetic cost.
However, latency can also increase if the system compensates for compression by searching more candidates, performing extra refinement, or reading full-precision vectors from disk. The correct question is not whether quantization is always faster, but whether the whole query path becomes faster at the recall target the application requires.
Because quantization changes both storage and ranking behavior, the next practical question is how systems recover accuracy without giving up the memory savings. That is where over-fetching and re-scoring become important.
Re-scoring with Full-Precision Vectors Kept on Disk
Re-scoring is a second-pass ranking step that uses the original full-precision vectors to refine results after the compressed index has found likely candidates. The active index searches with quantized vectors because they are smaller and cheaper. Then, instead of trusting the approximate compressed distances completely, the system fetches the original vectors for a limited candidate set and recalculates exact or higher-precision distances. The final top results are ranked using the more accurate distances.
This pattern is useful because the system does not need to keep every full-precision vector in memory during search. It can keep compressed vectors in the active index and keep original vectors in the main data store, on disk, or in a colder storage tier. At query time, it only reads full-precision vectors for the candidates that survived the first pass. This preserves most of the storage benefit while improving final ranking quality.
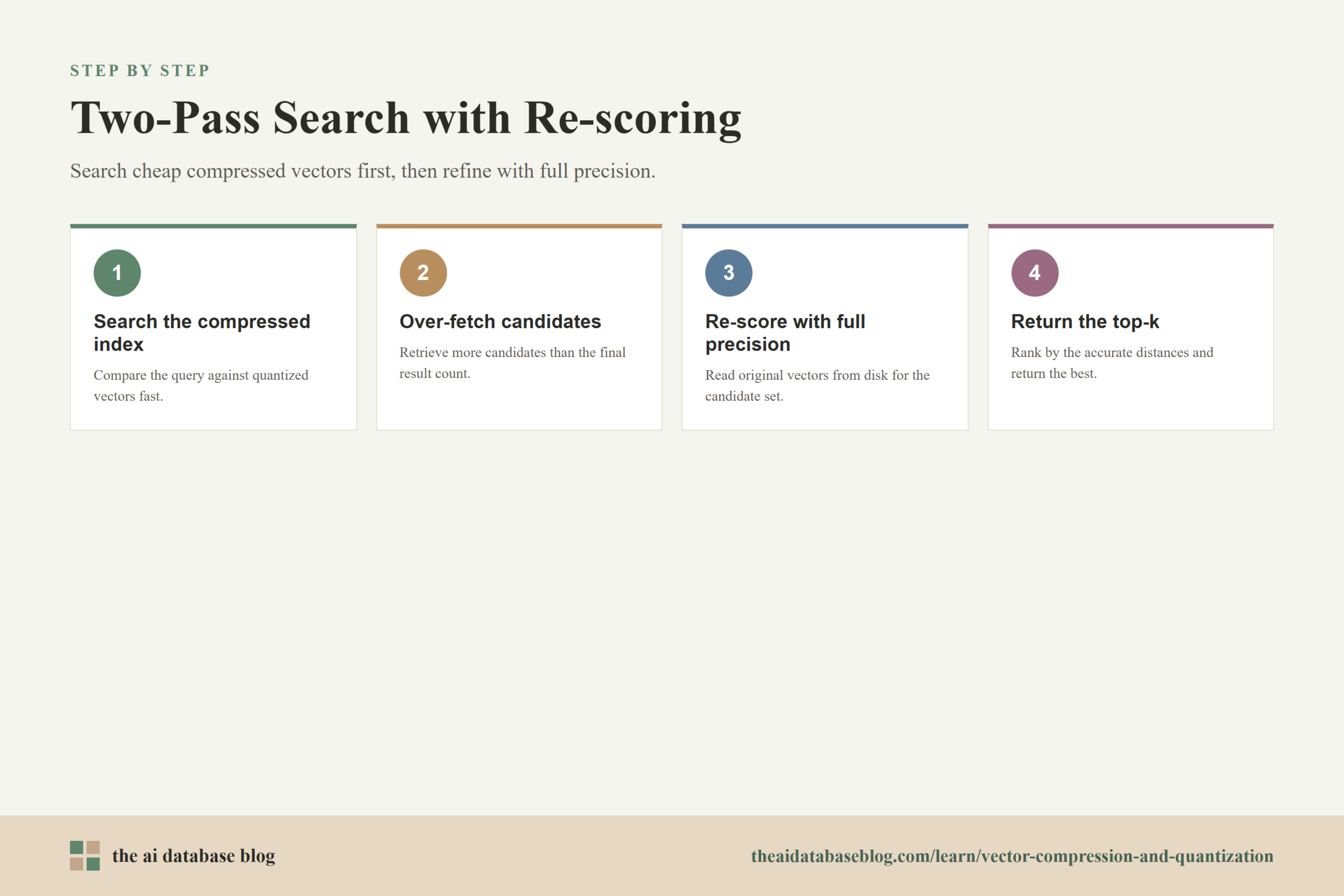
How the Two-Pass Search Works
A typical compressed search flow has four steps. First, the query vector is compared against the quantized index. Second, the system retrieves more candidates than the user ultimately requested. Third, the system loads the full-precision vectors for those candidates from storage. Fourth, it recalculates distances and returns the top-k results after re-ranking.
If the user asks for 10 results, the system might initially retrieve 50, 100, or more candidates from the compressed index. This is often called over-fetching, oversampling, or using a larger candidate pool. The reason is simple: if compression causes a few true neighbors to appear slightly lower in the approximate ranking, retrieving extra candidates gives them a chance to enter the second pass. Re-scoring can only fix candidates that were retrieved in the first place.
Why Full-Precision Vectors Are Still Stored
Keeping full-precision vectors on disk serves several purposes. It allows re-scoring, supports rebuilding or changing the index later, and preserves the original embedding data for future retrieval configurations. If the system only stored compressed vectors, it would be harder to recover accuracy, change quantization settings, or compare compressed search against an exact baseline.
There is a storage cost to keeping both compressed and full-precision representations. The compressed representation reduces memory and active index cost, while the original representation remains available in durable storage. This is often a good trade because disk storage is usually cheaper than memory, and the system only reads a small number of full vectors per query during re-scoring.
When Re-scoring Helps Most
Re-scoring helps most when the compressed index can find a good candidate set but the approximate ordering is not reliable enough by itself. In that case, the first pass handles broad recall, and the second pass improves precision in the final ranking. This is especially useful for retrieval-augmented generation, where the final few chunks passed to a language model matter more than the exact ordering of every possible neighbor.
Re-scoring is less useful if the first pass misses the right candidates entirely. If the quantization is too aggressive, the candidate pool is too small, or the index parameters are poorly tuned, the true neighbors may never reach the re-scoring stage. In those cases, increasing the candidate pool, using a less aggressive quantization setting, or tuning the underlying index may be necessary.
Re-scoring gives compressed vector search a practical safety valve, but it is not free. The storage design still has to account for disk reads, candidate pool size, and the cost of exact distance calculations.
How to Tune Quantization from a Storage Perspective
Good quantization tuning starts with a target, not with a compression setting. The target should describe the minimum acceptable recall, the latency range, the memory budget, and the query patterns that matter in production. Without those constraints, it is easy to over-compress and lose relevance, or under-compress and spend more on memory than the workload requires.
The safest approach is to establish a full-precision baseline first. Run representative queries against an uncompressed or high-precision setup, record the expected nearest neighbors, and measure the quality of downstream behavior. Then test compressed configurations against that baseline. This makes the trade-off visible instead of relying on generic assumptions about a quantization method.
Start with Moderate Compression
For many workloads, moderate compression is a better starting point than the most aggressive option. Lowering precision from 32-bit values to 16-bit or 8-bit representations can reduce memory pressure while preserving much of the original neighborhood structure. This is often easier to tune than jumping directly to binary compression or highly compact product quantization.
Moderate compression is especially useful when the application has mixed needs: many queries, strict latency expectations, and a relevance target that cannot be allowed to drift too far. Once the moderate setting is measured, more aggressive compression can be tested with a clear understanding of what is gained and what is lost.
Increase the Candidate Pool Before Judging Recall
A compressed index may look weak if it returns only the exact number of requested results from the first pass. Over-fetching gives the system more room to correct approximate ranking errors. If re-scoring is enabled, candidate pool size becomes one of the most important tuning controls because it determines how many full-precision comparisons are available in the second pass.
The candidate pool should not be increased blindly. Larger pools can improve recall, but they also require more distance calculations and more full-vector reads. A practical test should measure recall, median latency, tail latency, and throughput at several candidate pool sizes. The goal is to find the smallest pool that reliably reaches the quality target.
Measure Disk Read Behavior
When full-precision vectors are kept on disk, re-scoring turns some searches into storage reads. That does not have to be a problem, because only a limited candidate set is read. But the cost depends on storage latency, cache hit rate, concurrency, vector size, and whether candidates are physically clustered or scattered.
For production systems, it is important to test re-scoring under realistic query volume. A configuration that works well for single-query benchmarks may behave differently when many users search at once. If the system reads too many full vectors per query, tail latency can rise even though average latency looks fine. Storage-aware benchmarking should include warm-cache and cold-cache scenarios when the workload depends on disk-resident vectors.
After the basic tuning loop is in place, the final design decision is where quantization fits in the broader retrieval architecture. It is rarely the only relevance control; it usually works alongside indexing, filtering, and ranking choices.
Where Quantization Fits in AI Database Architecture
Quantization is best understood as one layer in a retrieval system, not as the whole retrieval strategy. It changes how vectors are represented in the index, but it does not replace good data modeling, metadata filtering, embedding quality, index tuning, or evaluation. A compressed index can make large-scale search affordable, but it still needs a retrieval pipeline that sends the right candidates to the application.
In retrieval-augmented generation, for example, quantized vector search may be used to find a broad set of semantically similar chunks. Metadata filters may restrict results to the right tenant, document type, language, date range, or access level. Re-scoring with full-precision vectors may refine the nearest-neighbor ranking. A later ranking step may then prioritize diversity, freshness, authority, or answer usefulness before the final context is sent to the model.
This layered view matters because storage optimization should not be confused with relevance optimization. Quantization can reduce cost and preserve strong recall when tuned well, but it cannot fix poor chunking, stale embeddings, weak metadata, or an evaluation set that does not reflect real user questions. The storage layer makes retrieval scalable; the full architecture makes it reliable.
Best-Fit Use Cases
Quantization is most useful when the vector collection is large enough that full-precision in-memory storage becomes expensive or impractical. It is also useful when query throughput is high, memory bandwidth is a bottleneck, or the system needs to serve large indexes on limited hardware. In these cases, compressed vectors can keep the active search path smaller and more efficient.
It may be less important for small datasets, low-query-volume prototypes, or applications where every query can afford exact search over full-precision vectors. In those cases, the added tuning complexity may not be worth it. The storage view should always begin with the actual scale and quality target, not with the assumption that every vector index needs compression.
Operational Risks to Watch
The biggest operational risk is assuming that a compressed index will behave like a full-precision index without measurement. Quantization can change ranking behavior in subtle ways. It may affect some query types more than others, especially rare concepts, short queries, multilingual data, dense near-duplicate clusters, or filtered searches where the candidate pool is already narrow.
Another risk is ignoring how compression settings interact with index parameters. In graph-based indexes, search breadth and graph construction choices can affect recall alongside quantization. In partitioned indexes, the number of partitions searched can interact with compressed distance estimates. In filtered search, metadata constraints can reduce the available candidates before re-scoring has a chance to help. These interactions are why production tuning should evaluate the whole query path.
With those risks in mind, quantization becomes much easier to evaluate: it is a controlled storage optimization with measurable quality effects, not a mysterious shortcut.
Practical Example: Compressed Index, Full-Precision Re-scoring
Imagine an AI database that stores 50 million support-document chunks. Each chunk has a 768-dimensional embedding. Keeping every vector in full precision inside the active index would require a large memory footprint before accounting for graph links, metadata, and replication. The team wants to reduce memory use while still returning high-quality results for support questions.
A practical design might keep an 8-bit quantized representation in the vector index and keep the original 32-bit vectors in durable storage. When a user asks a question, the system searches the compressed index for a larger candidate set, such as the top 100 candidates. It then loads the original vectors for those candidates, recalculates distances against the query vector, and returns the best 10 after re-scoring.
This design reduces the active memory footprint because the search index no longer needs full-precision vectors for every object. It also protects result quality because the final ranking uses the original vectors. The team still needs to benchmark candidate pool size, latency, and recall, but the architecture gives them a clear way to balance memory savings against relevance.
The example shows the main storage principle: compression is most useful when it reduces the always-on cost of the index, while full-precision data remains available for the smaller number of comparisons that matter most.
FAQs
1. What is vector quantization in an AI database?
Vector quantization is a compression technique that stores vector embeddings in a lower-precision or more compact form. Instead of keeping every dimension as a full 32-bit floating-point number in the active index, the database can use smaller numeric values, binary values, or compact codes. This reduces memory use and can make search more efficient, but it also makes distance calculations approximate.
2. Does quantization reduce disk storage or only memory usage?
It can affect both, depending on how the database stores its index and original vectors. The compressed representation usually reduces the footprint of the active vector index, which is often kept in memory or memory-mapped storage. Many systems still keep the original full-precision vectors on disk for re-scoring, rebuilding, or comparison, so total durable storage may include both compressed and full-precision data.
3. Why can quantization reduce recall?
Quantization reduces recall because compressed vectors do not preserve every numeric detail from the original embeddings. Since nearest-neighbor search depends on distance calculations, small approximation errors can change which candidates appear closest to the query. If a true neighbor is pushed outside the candidate set, the system may fail to return it.
4. How does re-scoring improve compressed vector search?
Re-scoring improves compressed search by using the compressed index only for the first candidate search, then recalculating distances with the original full-precision vectors for a smaller candidate set. This lets the system keep most of the memory savings from compression while using more accurate distances for the final ranking.
5. Is more aggressive compression always better for large datasets?
No. More aggressive compression can reduce memory further, but it can also lower recall, increase the need for over-fetching, or add re-scoring cost. The best setting depends on the dataset, embedding model, index type, query patterns, and acceptable quality loss. Large datasets benefit from compression, but the right level should be chosen through benchmarking.
6. When should full-precision vectors be kept on disk?
Full-precision vectors should be kept on disk when the system needs accurate re-scoring, future index rebuilding, or the ability to compare compressed search against a high-precision baseline. This is common in production AI database systems because durable storage is usually cheaper than memory, and only a limited number of full vectors need to be read during each re-scoring pass.
Takeaway
Vector compression and quantization reduce the active storage and memory cost of AI database search by replacing full-precision embeddings with smaller representations in the index. The trade-off is that compressed distances are approximate, so recall can drop if the system retrieves too few candidates or compresses too aggressively. Re-scoring with full-precision vectors kept on disk helps recover accuracy by using compressed vectors for fast candidate discovery and original vectors for final ranking. This guidance is most useful for teams building large-scale semantic search, retrieval-augmented generation, recommendation, or knowledge retrieval systems where memory cost, latency, and result quality all need to be balanced carefully.