HNSW tuning is about balancing graph quality, search breadth, and resource cost. The M parameter controls how many graph connections each vector can keep, efConstruction controls how carefully the graph is built, and ef controls how broadly the graph is searched at query time. Higher values usually improve recall, but they can increase latency, memory use, index build time, or insert cost depending on which parameter is changed.
This guide explains what each parameter does, how it affects recall, latency, memory, and build time, and how to tune HNSW for practical AI database workloads such as semantic search, retrieval-augmented generation, recommendations, and filtered vector search. By the end, you should be able to choose sensible starting values, run a controlled tuning sweep, and understand what to adjust when search quality or performance is not where it needs to be.
Why HNSW Tuning Matters
Hierarchical Navigable Small World, usually shortened to HNSW, is a graph-based approximate nearest neighbor index. Instead of comparing a query vector to every vector in the database, HNSW builds a navigable graph where nearby vectors are connected. At query time, the index enters the graph at an upper layer, moves toward promising neighborhoods, and then searches more carefully near the bottom layer where most vectors live.
This is why HNSW is widely used in AI databases. It can return high-quality nearest neighbor results with much lower latency than exact brute-force search, especially when collections contain many vectors. The tradeoff is that the results are approximate. If the graph is too sparse or the query search is too narrow, the search can stop near good neighbors without finding the best ones.
The three parameters covered here determine most of that tradeoff. M and efConstruction influence the shape and quality of the index itself. ef, sometimes called efSearch in some systems, controls the breadth of each query search. A useful tuning process separates these two stages: first build a graph that is good enough for your data, then tune query-time breadth until recall and latency meet your application target.
Once you understand that split between index construction and query execution, the parameters become easier to reason about. The next step is to look at each one directly and connect it to the operational effects that matter in production.
What M Controls
M controls the maximum number of graph connections that each vector can keep per layer. Some systems expose the same idea under a different name, such as maxConnections. The exact implementation details can vary, but the practical meaning is consistent: a higher M gives each node more neighbors, creating a denser graph with more possible routes during search.
A denser graph usually improves recall because the search has more paths to follow. This is especially important for datasets with high intrinsic dimensionality, uneven clusters, multilingual embeddings, mixed document types, or many near-duplicates. In those cases, a sparse graph may not preserve enough useful connections between neighborhoods, so the search can miss relevant vectors even when ef is increased.
The cost is memory and construction work. Every additional connection has to be stored, and the index has to evaluate and maintain more graph links while vectors are inserted. As a result, increasing M tends to increase memory usage and build time. It may also raise query latency because the search has more candidate links to inspect, although the effect on latency is usually workload-dependent and often smaller than the effect of increasing ef.
How M Affects Recall, Latency, Memory, and Build Time
- Recall: Higher
Musually improves recall by making the graph more connected. It is often most helpful when default settings plateau below the recall target even after increasing query-timeef. - Latency: Higher
Mcan increase query work because each visited node has more outgoing links. In some cases, better graph connectivity can reduce wasted search, but teams should still measure latency instead of assuming it will improve. - Memory: Higher
Mincreases index memory because more graph edges must be stored. This is the clearest and most predictable cost of raisingM. - Build time: Higher
Musually increases build time and insert cost because the index must search for, select, and maintain more connections for each vector.
Because M changes the structure of the graph, it is not the first parameter to adjust for every problem. If recall is slightly low and latency has room, query-time ef is usually the cheaper experiment. If recall remains poor at high ef, the graph itself may need to be rebuilt with a higher M or a higher efConstruction.
What efConstruction Controls
efConstruction controls how broad the neighbor search is while the HNSW graph is being built. When a new vector is inserted into the graph, the algorithm searches for candidate neighbors and decides which connections to keep. A higher efConstruction means the index considers a larger candidate set during this construction step, which usually produces a better graph.
This parameter is about build quality rather than query breadth. A low value can build faster, but it may connect nodes to less useful neighbors. A higher value gives the construction process more chances to find good links, which can improve recall later. However, the benefits usually show diminishing returns: after the graph is already well connected for the dataset, raising efConstruction further may add build cost without a meaningful quality improvement.
Unlike M, efConstruction usually does not increase the final number of stored graph links by itself. It mostly changes how much work is done to choose those links. That means its most direct costs are index build time and insert speed. Memory during construction can still matter because larger candidate lists and larger in-memory graph builds require more working memory, but the long-term index size is primarily driven by vector storage, graph connections, and compression choices.
How efConstruction Affects Recall, Latency, Memory, and Build Time
- Recall: Higher
efConstructioncan improve recall by creating better graph connections. The effect is strongest when the original graph was underbuilt. - Latency: It does not directly widen query search, but a better graph can sometimes reach good neighbors with less query effort. The practical latency effect should be measured with your real queries.
- Memory: It does not usually increase stored graph edges unless paired with a higher
M. It can still increase temporary build-time memory pressure. - Build time: Higher
efConstructionincreases build time and insert cost because each vector insertion evaluates more candidates.
The relationship between M and efConstruction matters. If M allows many connections but efConstruction is too low, the builder may not find enough strong candidates to use those connections well. A practical rule is to keep efConstruction at least several times larger than M, then test whether higher values improve recall enough to justify slower indexing.
What ef Controls
ef controls the size of the dynamic candidate list used during search. Some systems call this efSearch. It is the most important query-time HNSW tuning knob because it can usually be changed without rebuilding the index. A higher ef tells the search to keep exploring more candidates before returning the nearest neighbors.
The effect is direct: increasing ef usually improves recall and decreases throughput because each query does more graph traversal and distance computation. Lowering ef reduces latency and CPU work, but it increases the chance that the search stops too early. For user-facing search, this can mean relevant documents are missing from the top results. For retrieval-augmented generation, it can mean the language model receives incomplete or weaker context.
One useful property of ef is that it can often vary by query type. A fast autocomplete flow might use a lower value because low latency matters more than perfect recall. A legal, medical, compliance, or internal research workflow might use a higher value because missing the best evidence is more costly. Batch jobs can often use even higher values because latency is less visible to the user.
How ef Affects Recall, Latency, Memory, and Build Time
- Recall: Higher
efusually improves recall by allowing the search to inspect more candidates before returning results. - Latency: Higher
efincreases query latency and CPU work. This is usually the most visible cost of raising it. - Memory: Higher
efuses more temporary per-query working memory for candidate tracking, but it does not usually increase persistent index size. - Build time: Query-time
efdoes not affect build time because it is used during search, not index construction.
Because ef is adjustable at query time in many systems, it is often the safest first tuning lever. But it cannot fix every graph problem. If recall remains low even at high ef, the issue is probably the index structure, the embedding model, filtering behavior, data distribution, or evaluation method rather than the search breadth alone.
How the Parameters Work Together
The easiest way to tune HNSW is to treat M and efConstruction as build-time quality controls and ef as the runtime quality control. Build-time parameters decide how much useful structure exists in the graph. Runtime ef decides how much of that structure each query is allowed to explore.
These parameters are connected, but they are not interchangeable. Raising ef can compensate for a graph that is slightly sparse, but it may not fully recover from a graph with poor connections. Raising efConstruction can improve graph quality, but it will not reduce latency if queries still need a very high ef to meet recall targets. Raising M can improve the graph’s navigability, but it increases memory for every stored vector.
A practical tuning workflow starts with a baseline, measures recall against an exact search sample, and then changes one variable at a time. The goal is not to maximize every parameter. The goal is to find the lowest-cost configuration that reaches the recall target at the latency and memory budget your application can support.
Typical Direction of Each Tradeoff
| Parameter | Primary Control | Higher Value Usually Improves | Main Cost |
|---|---|---|---|
M | Graph connectivity | Recall and graph navigability | Memory, build time, and sometimes query latency |
efConstruction | Build-time candidate breadth | Graph quality and recall | Build time, insert speed, and temporary build resources |
ef | Query-time candidate breadth | Recall | Query latency, CPU work, and temporary per-query memory |
The table shows the direction of the tradeoffs, but it does not replace measurement. HNSW behavior depends on vector dimensions, data distribution, distance metric, filters, hardware, concurrency, and the target number of results. That is why a good tuning process needs a repeatable evaluation set rather than a single anecdotal query.
Practical Tuning Workflow
A reliable HNSW tuning process begins with an evaluation set. Select representative queries, compute the exact nearest neighbors for a sample of the corpus, and compare approximate HNSW results against that exact baseline. Measure recall at the same result depth your application uses, such as recall@10 or recall@20, and record p50, p95, and p99 latency rather than only average latency.
Start with conservative defaults from your AI database or vector search library. Many systems use values around M = 16, efConstruction = 64 to 200, and ef = 40 to 100, but defaults vary. The exact numbers matter less than the method: hold the index fixed, sweep query-time ef, and observe where recall starts to flatten.
If recall reaches the target with acceptable latency, keep the lower ef value that meets the target with some safety margin. If recall is too low even when ef is high, rebuild a test index with a higher efConstruction. If recall still plateaus below target or the dataset is complex, test a higher M. Each rebuild should be evaluated with the same query set so the tradeoff is visible.
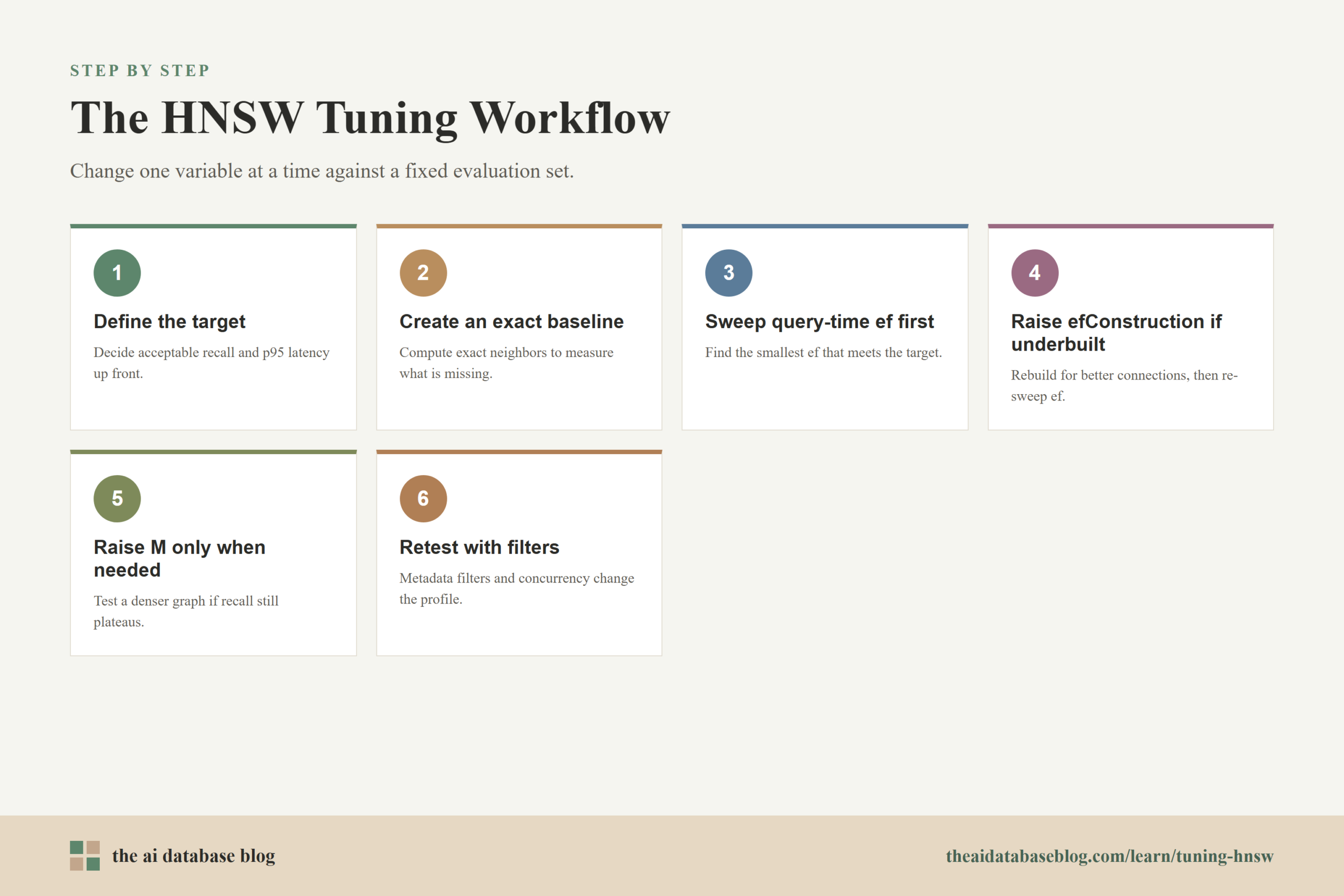
Step-by-Step Tuning Process
- Define the target. Decide what recall and latency are acceptable. For example, a RAG system might target recall@10 above 0.95 with p95 vector search latency under 100 milliseconds.
- Create an exact baseline. For a sample of vectors and queries, compare against exact nearest neighbor search so you know what the approximate index is missing.
- Sweep query-time ef first. Test values such as 40, 80, 120, 200, and 400 while keeping the same index. Choose the smallest value that meets recall and latency goals.
- Increase efConstruction if the graph seems underbuilt. Rebuild with a higher construction value and repeat the
efsweep. Watch build time and insert speed carefully. - Increase M only when needed. If recall still plateaus below target, test a denser graph such as moving from
M = 16toM = 24orM = 32. Measure memory before considering the setting viable. - Retest with filters and real concurrency. Metadata filtering, multi-tenant filters, and high query concurrency can change the effective recall and latency profile.
This workflow also helps avoid overtuning. Very high settings can look attractive in an isolated recall test, but they may be too expensive once ingestion, memory pressure, filtering, and concurrent user traffic are included. The best configuration is the one that holds up under realistic operating conditions.
Examples of HNSW Tuning Choices
Examples make the tradeoffs easier to see, but they should be treated as starting points rather than universal recommendations. Different systems use different defaults and names, and a setting that works for one embedding model or corpus size may not work for another. Use these examples to reason about tuning direction, then validate with your own benchmark.
Example 1: Fast Semantic Search With Moderate Recall Needs
Suppose an application searches product descriptions or help center articles where users expect fast results and the system can tolerate occasionally missing a near-duplicate. A reasonable starting point might be a moderate graph, such as M = 16, efConstruction = 100 to 200, and a query-time ef around 50 to 100.
If recall is acceptable, the team should avoid raising M because that would increase memory across the full index. If users complain about weak results, the first experiment should be increasing ef. If that helps but latency becomes too high, the next experiment is building a better graph with a higher efConstruction so the same recall might be reached with a lower query-time ef.
Example 2: High-Recall RAG Retrieval
For a retrieval-augmented generation system over internal knowledge, recall often matters more. Missing the best policy, contract clause, support note, or incident record can produce a weaker answer even if the language model behaves correctly. In this case, the team might test M = 24 or M = 32, pair it with efConstruction = 200 to 400, and sweep ef from 100 upward.
The main question is where recall stops improving. If recall@10 improves sharply from ef = 80 to ef = 160 but barely changes after ef = 300, the higher values may not be worth the latency. If recall remains low even at high ef, the team should inspect chunking, embeddings, metadata filters, and graph build settings instead of only increasing query search breadth.
Example 3: Memory-Constrained Deployment
In a memory-constrained deployment, M becomes the parameter to treat most carefully because it increases stored graph connections. The team might start with M = 12 or M = 16 and avoid moving higher unless the recall gain is clearly worth the memory cost. Query-time ef can then be tuned to recover as much recall as possible within the latency budget.
If recall is still too low, raising efConstruction may be cheaper than raising M because it can improve connection quality without necessarily increasing persistent graph size. If that is not enough, the better answer may be compression, sharding strategy changes, smaller embeddings, or a different retrieval architecture rather than forcing a dense HNSW graph into too little memory.
These examples point to a broader lesson: HNSW tuning is rarely just a search problem. It is also a capacity planning problem. The right values depend on how much recall the application actually needs, how much latency users will tolerate, how often the index changes, and how much memory the system can reserve for vector search.
Common Tuning Mistakes
Most HNSW tuning mistakes come from changing parameters without a clear measurement target. Because the knobs interact, it is easy to increase several values at once and end up with a slower, more expensive index without knowing which change helped. A disciplined process keeps the baseline stable, changes one parameter at a time, and records recall, latency, build time, and memory together.
Only Measuring Latency
Low latency is not useful if the index consistently misses important neighbors. Always measure recall against an exact baseline or a strong labeled evaluation set. This is especially important for RAG systems, where the generated answer can hide retrieval failures until users inspect the supporting context.
Only Measuring Recall
High recall is not free. A configuration that looks excellent in an offline notebook may be too slow under production concurrency or too memory-heavy for the deployment. Track p95 and p99 latency, not just average latency, because long-tail query behavior often determines user experience.
Raising M Too Early
Raising M can be effective, but it is also one of the most expensive changes because it increases graph memory. Try query-time ef first, then efConstruction, and raise M when the graph appears structurally too sparse for the dataset.
Ignoring Filters
Metadata filters can reduce the number of usable candidates after vector search. If a query searches broadly and then filters results down to a narrow category, the effective recall may be lower than expected. Filtered workloads often need higher query breadth, better filter-aware indexing strategies, or partitioning by high-value filter fields.
Avoiding these mistakes makes tuning less mysterious. The parameters are still workload-specific, but the process becomes repeatable: decide what good looks like, measure the current index, change one thing, and compare the full tradeoff.
Practical Starting Points
There is no universal HNSW configuration, but practical starting points can reduce the search space. For many general-purpose semantic search workloads, begin with the database or library default, then run an ef sweep before rebuilding the index. If defaults are not available, M = 16, a construction value around 100 to 200, and a query-time ef around 50 to 100 are reasonable first experiments for many medium-sized corpora.
For high-recall workloads, test a higher construction value and a wider ef sweep early. For difficult datasets, consider testing M = 24 or M = 32, but only after measuring the memory impact. For low-latency workloads, keep ef as low as possible while meeting minimum quality requirements, and use the smallest M that does not create unacceptable recall loss.
For frequently updated indexes, build-time and insert-time costs matter more. A very high efConstruction may be acceptable for a mostly static corpus that is rebuilt overnight, but painful for a system that continuously ingests new documents. If the workload is write-heavy, measure insertion throughput and compaction or maintenance behavior as part of the tuning process.
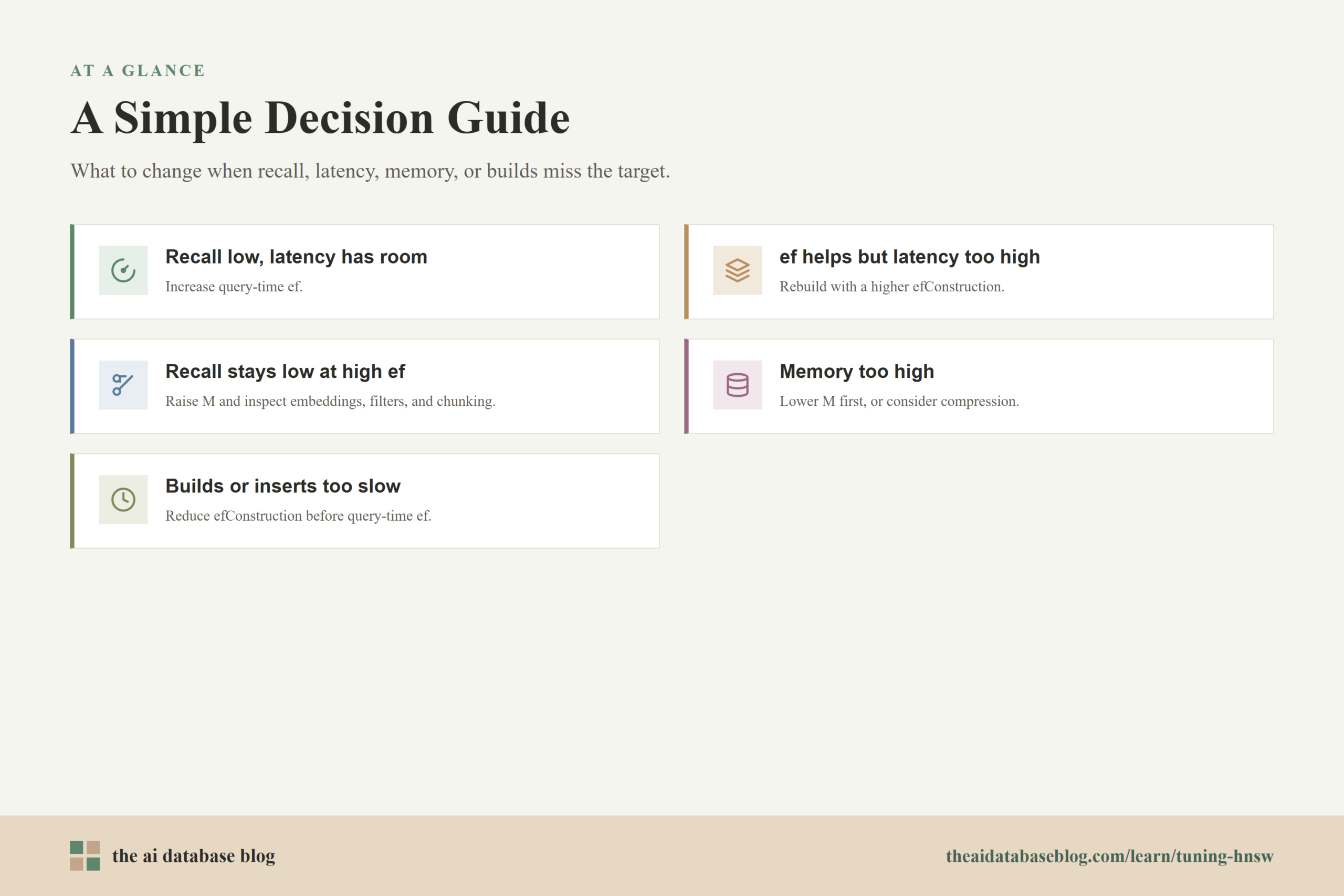
A Simple Decision Guide
- If recall is low but latency has room, increase query-time
ef. - If recall improves with higher
efbut latency becomes too high, try rebuilding with higherefConstruction. - If recall stays low even at high
ef, test a higherMand inspect data quality, embeddings, filters, and chunking. - If memory is too high, lower
Mfirst or consider compression and architecture changes. - If builds or inserts are too slow, reduce
efConstructionbefore reducing query-timeef.
These rules work best when paired with a benchmark that reflects real usage. The same collection can need different settings for interactive search, background enrichment, compliance review, and agentic retrieval because each workflow has a different tolerance for missed neighbors and latency.
FAQs
1. Is ef the same as efSearch?
In many systems, yes. ef and efSearch both refer to the query-time candidate list size used during HNSW search. Some databases use ef, while libraries or other databases use efSearch. The practical meaning is the same: higher values search more broadly and usually improve recall at the cost of latency.
2. Should I tune M or ef first?
Tune query-time ef first in most cases because it can often be changed without rebuilding the index. If increasing ef reaches the recall target within the latency budget, you do not need to change the graph. Tune M when recall plateaus below target or the graph appears too sparse for the dataset.
3. Does efConstruction affect query latency?
efConstruction does not directly make each query search more candidates. Its direct effect is on graph construction quality and build time. However, a better graph can sometimes help queries find good neighbors with a lower ef, so it can indirectly improve the recall-latency tradeoff.
4. Why does increasing M use more memory?
M increases the number of graph connections each vector can store. Those connections are part of the persistent HNSW index, so a higher value adds memory overhead across the collection. The memory increase becomes more important as the number of vectors grows.
5. What is a good ef value for RAG?
There is no single best value, but RAG systems often benefit from a higher ef than casual semantic search because missing relevant context can reduce answer quality. A practical approach is to sweep values such as 80, 120, 200, and 400, then choose the smallest value that meets the target recall and latency for your retrieval depth.
6. Can higher HNSW settings fix poor embeddings?
Only partly. Higher M, efConstruction, and ef can help the index find nearest neighbors more reliably, but they cannot make unrelated vectors semantically meaningful. If exact nearest neighbor results are also poor, the problem is likely the embedding model, chunking strategy, metadata, or source data rather than HNSW tuning.
Takeaway
HNSW tuning works best when you separate build-time graph quality from query-time search breadth. M controls graph connectivity and has the strongest persistent memory impact, efConstruction controls how carefully the graph is built and mainly affects build time, and ef controls query-time search breadth and mainly affects recall and latency. This guidance is most useful for teams building AI database workloads such as semantic search, RAG, recommendations, and filtered retrieval, where the right configuration is the one that reaches the needed recall at an acceptable latency, memory footprint, and indexing cost.
Watch this video to learn more