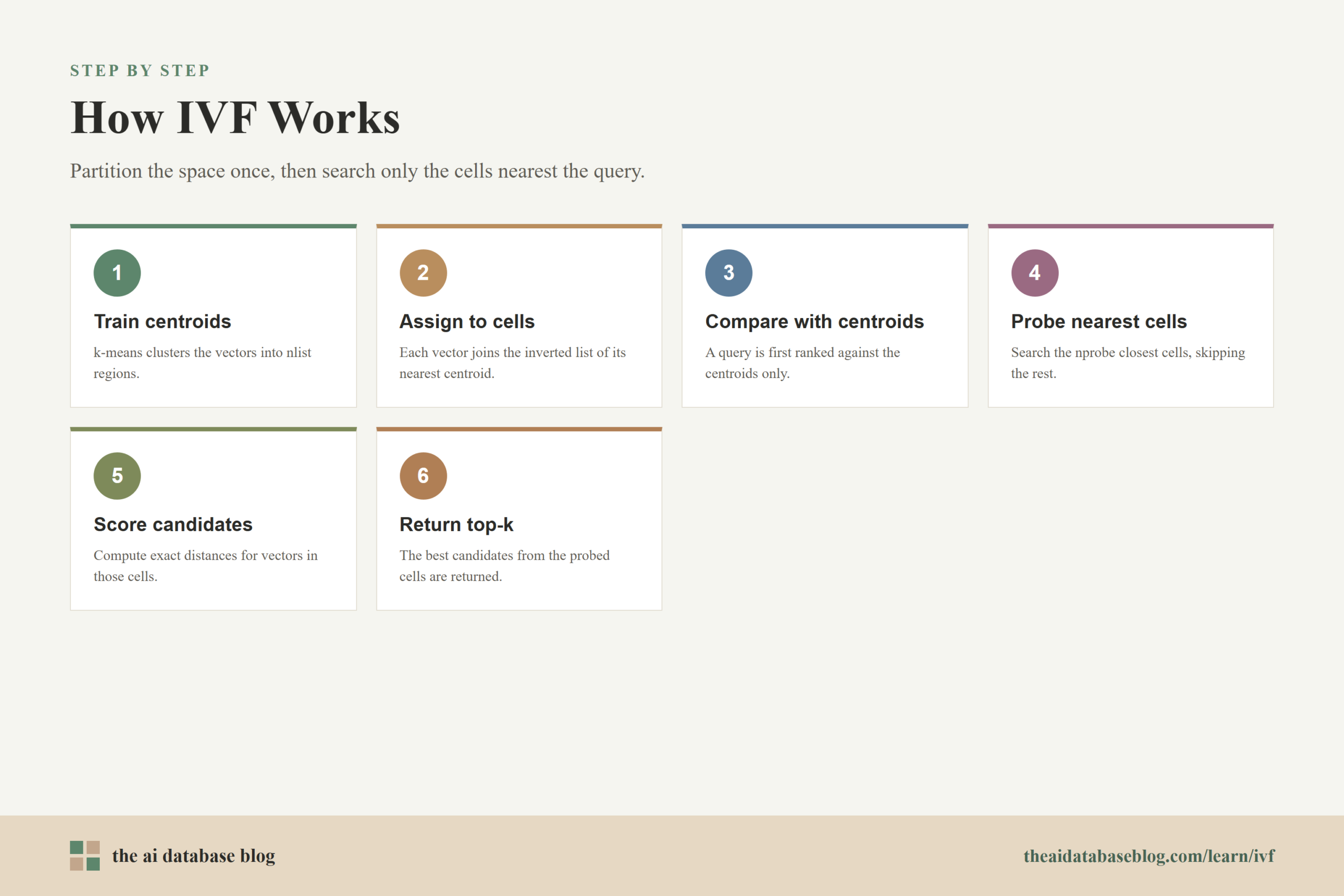
IVF, or Inverted File Index, is a vector search indexing method that speeds up nearest-neighbor search by dividing an embedding space into clusters and searching only the most relevant clusters at query time. It usually uses k-means clustering to create centroid-based regions, often described as Voronoi cells, then assigns each stored vector to the closest centroid. During search, the system finds the nearest centroids to the query and scans only the vectors in the selected cells. The main tuning tradeoff is between nlist, the number of clusters, and nprobe, the number of clusters searched per query.
This guide explains how IVF works from index building through query execution. You will learn how k-means creates the coarse structure, how vectors are assigned to centroids, why searching only the nearest nprobe cells can be much faster than exhaustive search, and how to think about the nlist and nprobe tradeoff when building AI database systems for semantic search, recommendation, retrieval-augmented generation, and other embedding-based applications.
What IVF Means in Vector Search
An Inverted File Index is an approximate nearest-neighbor index for vector data. The word “inverted” comes from an idea used in classic information retrieval: instead of scanning every record directly, the system keeps lists that point to candidate records. In text search, an inverted index maps terms to documents. In vector search, IVF maps coarse vector regions to the vectors that fall inside them.
The basic goal is simple. If a database stores millions or billions of embeddings, comparing a query vector against every stored vector can be expensive. A flat search can be accurate because it checks everything, but it may be too slow or too costly for many production workloads. IVF reduces the search space by first deciding which parts of the vector space are most likely to contain close matches.
IVF is called approximate because it may skip some vectors that could have been relevant. If the true nearest neighbor falls inside a cluster that was not searched, the system will miss it. The benefit is that the query can inspect a much smaller candidate set, which often gives a useful balance between latency, throughput, memory use, and recall.
Once the high-level idea is clear, the next question is how the vector space gets divided in the first place. That is where k-means clustering and centroids become central to IVF.
How K-Means Creates Voronoi Cells
IVF usually begins by training a coarse quantizer over a sample of the vectors. In practical terms, this often means running k-means clustering. K-means chooses a fixed number of centroids, then repeatedly adjusts those centroids so that each one represents a cluster of nearby vectors. The number of centroids is commonly controlled by the parameter called nlist.
Each centroid acts like the center of a region in the embedding space. If every point in the space is assigned to the nearest centroid, the result is a set of regions known as Voronoi cells. A Voronoi cell contains all points that are closer to one centroid than to any other centroid. In IVF, these cells become the coarse search partitions.
This structure is useful because embeddings that are close to the same centroid are likely to be roughly related in vector space. The centroid does not need to perfectly describe every vector in its cell. It only needs to provide a fast first step that narrows the search from the entire dataset to a smaller set of candidate lists.
For example, imagine a database of product description embeddings. K-means might place one centroid near outdoor equipment, another near kitchen tools, another near office supplies, and many more throughout the space. These labels are only for human intuition; the index itself usually works only with vectors and distances. Still, the idea helps explain why searching a few nearby cells can often find useful results without checking every item.
K-means gives IVF its map of the vector space, but the index is not complete until stored vectors are attached to that map. The next step is assigning each vector to the centroid that best represents its coarse location.
Assigning Vectors to Centroids
After the centroids are trained, the index assigns each database vector to its nearest centroid according to the chosen distance or similarity metric. For Euclidean distance, the closest centroid is the one with the smallest distance. For cosine-style search, implementations often normalize vectors or use an equivalent distance approach so that the assignment is consistent with the search objective.
Each centroid owns an inverted list. When a vector is assigned to a centroid, the vector’s identifier and often its vector data or compressed representation are stored in that centroid’s list. The index becomes a collection of lists: one list per centroid, with each list containing the vectors that belong to that coarse region.
This assignment is what makes IVF different from a flat index. A flat index treats the dataset as one large searchable pool. An IVF index breaks the pool into many smaller pools. At query time, the system can choose which pools to search and which pools to ignore.
The quality of these assignments matters. If the clusters are badly balanced, some lists may become too large while others stay small. Large lists can make searches slower because probing one large cell may still require many comparisons. Poorly placed centroids can also hurt recall because related vectors may be split across cells in ways that are difficult to recover unless nprobe is increased.
Once vectors are organized into inverted lists, IVF can perform its main trick: it searches near the query’s coarse location first, then compares the query only with candidates from selected lists.
How IVF Searches the nprobe Nearest Cells
When a query vector arrives, IVF does not immediately compare it with every stored vector. It first compares the query with the centroids. This centroid search is much smaller than a full vector search because the number of centroids is usually far lower than the number of stored vectors. The system ranks the centroids by their distance to the query.
The nprobe parameter tells the system how many of the nearest centroid cells to search. If nprobe is 1, the system searches only the single closest cell. If nprobe is 10, it searches the 10 closest cells. If nprobe equals nlist, the search effectively examines every cell, which moves it much closer to exhaustive search and removes much of the speed benefit of IVF.
After selecting the nprobe cells, the system scans the vectors inside those inverted lists and computes the final distances or similarity scores against the query. The top results are chosen from this candidate set. In a basic IVF_FLAT-style index, the stored vectors inside the selected lists are compared directly. In compressed variants, the system may compare compressed codes first and optionally refine or rescore candidates later.
The important point is that nprobe controls the width of the search. A small nprobe searches fewer vectors, which usually lowers latency but may reduce recall. A larger nprobe searches more vectors, which usually improves recall but increases query work. This is why nprobe is often treated as one of the most important query-time knobs in IVF-based retrieval.
The search process explains why IVF can be fast, but it also shows where mistakes can happen. The true nearest neighbor may sit just across a cell boundary, especially in high-dimensional spaces where geometric boundaries are not always intuitive. That makes the relationship between nlist and nprobe the practical tuning problem.
The nlist and nprobe Tradeoff
The nlist parameter sets the number of centroid lists created during index building. A higher nlist creates more clusters, which usually means smaller lists. Smaller lists can reduce the amount of work inside each probed cell. However, more clusters also mean more centroids to train, more centroid comparisons at query time, and a greater chance that nearby vectors are spread across several neighboring cells.
The nprobe parameter sets how many of those lists are searched for each query. A higher nprobe expands the candidate set and can recover neighbors that lie outside the single closest cell. It also increases the number of vector comparisons, so query latency and compute cost usually rise as nprobe increases.
These two parameters should not be tuned independently. If nlist is small, each cell contains many vectors, so even a low nprobe may still scan a large candidate set. If nlist is large, each cell may be small, but the system may need a higher nprobe to cover enough neighboring cells for good recall. The best setting depends on dataset size, embedding distribution, distance metric, hardware, concurrency, and the recall target of the application.
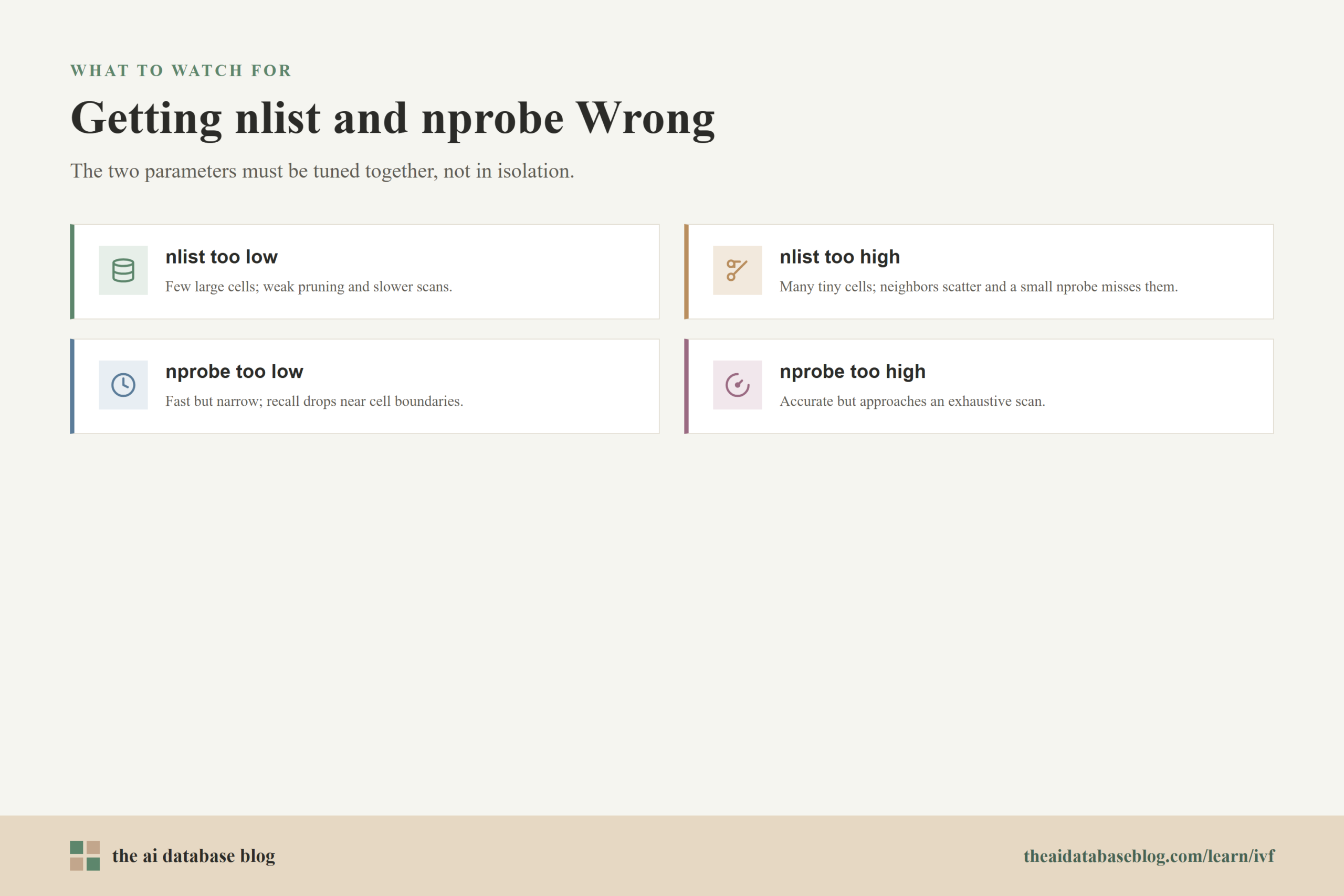
What Happens When nlist Is Too Low
When nlist is too low, the index has too few clusters. Each centroid represents a broad region, and each inverted list may contain many vectors. This can make the index easier to build and can reduce the overhead of centroid management, but it weakens the search-space reduction. Searching a few large lists may not be much better than scanning a large portion of the dataset.
Low nlist can also make clusters less specific. A cell may contain vectors that are only loosely related, so the query has to compare against many candidates that are not especially close. The result can be slower search, weaker pruning, and less control over latency at scale.
What Happens When nlist Is Too High
When nlist is too high, the index creates many small cells. This can reduce the number of vectors per list, but it also makes the partition more fragmented. The nearest results for a query may be scattered across several adjacent cells, so a small nprobe may miss important candidates.
A very high nlist can also increase index build time because k-means has to train more centroids. It may require more memory for index metadata and can create uneven lists if the data does not naturally fill all clusters. In some cases, many tiny lists create more overhead without delivering a meaningful recall or latency improvement.
What Happens When nprobe Is Too Low
When nprobe is too low, the search is fast but narrow. The system may look only in the closest cell or a small handful of cells. This can work well when clusters are clean and the query sits near the center of a relevant cell, but it is risky when relevant vectors lie near cell boundaries.
The most common symptom of too-low nprobe is reduced recall. Users may see results that are plausible but miss better matches. In retrieval-augmented generation, this can mean the model receives weaker context. In recommendation or semantic search, it can mean the system returns items that are close enough to look reasonable while quietly missing stronger candidates.
What Happens When nprobe Is Too High
When nprobe is too high, the search becomes broader and more accurate, but the speed advantage shrinks. Each additional probed cell adds more candidate vectors to score. At the extreme, probing every cell approaches exhaustive search across the whole index.
High nprobe can be useful for workloads where recall is more important than low latency. It can also help during evaluation because it shows how much recall improves as the search expands. But in a production system, nprobe usually needs to be balanced against service-level goals such as response time, throughput, and compute budget.
Understanding these failure modes makes IVF tuning less mysterious. The goal is not to find a universally correct nlist or nprobe value. The goal is to measure how candidate coverage, latency, and recall change together for the specific data and workload.
How to Tune IVF in Practice
IVF tuning works best as an empirical process. Start with a representative dataset, a realistic query set, and a clear definition of acceptable recall and latency. Then compare IVF results against a stronger baseline, often an exact or high-recall search on a smaller sample, so you can measure how many expected neighbors the index retrieves.
A practical tuning process usually changes nlist at build time and nprobe at query time. Because nlist affects the trained index structure, changing it often requires rebuilding or retraining the index. Because nprobe is a search parameter, it can often be adjusted per query or per workload without rebuilding the index. This makes nprobe useful for runtime tuning, while nlist is more of a design-time decision.
Useful evaluation metrics include recall at k, latency percentiles, throughput, memory use, and index build time. Recall at k asks whether the expected nearest neighbors appear in the top k results. Latency percentiles show how the system behaves not just on average but under slower queries. Build time matters because large indexes may need periodic refreshes or rebuilds as data changes.
For many applications, the best approach is to choose an nlist that creates reasonably sized and reasonably balanced lists, then sweep nprobe upward until recall reaches the target without exceeding latency goals. The exact values vary widely. A small internal knowledge base, a large consumer search system, and a high-throughput recommendation pipeline may all choose different settings.
Once the tuning process is in place, it becomes easier to decide whether IVF is the right index at all. IVF is strong in some situations, but it is not the only way to organize vector search.
When IVF Is a Good Fit
IVF is often a good fit when a dataset is large enough that flat search is too expensive, but the application can tolerate approximate results in exchange for faster search. It is especially useful when embeddings have enough structure for clustering to reduce the search space effectively. If similar vectors tend to group together, centroid-based partitioning can work well.
IVF can also be useful when the system needs a clear recall-latency control. Because nprobe is intuitive, teams can run experiments and choose different search widths for different workloads. For example, an interactive search feature may use a lower nprobe to keep responses fast, while an offline enrichment job may use a higher nprobe to improve recall.
Another reason to use IVF is that it can combine with compression methods. In very large systems, storing and comparing full precision vectors may be expensive. IVF can first narrow the search to a set of cells, then compressed representations can reduce memory and scoring cost inside those cells. This creates a family of index designs that trade storage, speed, and accuracy in different ways.
However, IVF may be less attractive for small datasets where flat search is already fast, for highly dynamic workloads where constant retraining is inconvenient, or for embedding distributions where k-means does not produce useful partitions. The index is only as useful as the partitioning and tuning make it.
These practical boundaries are important because IVF is not simply a faster version of exact search. It is a controlled approximation. To use it well, teams need to understand what the index is allowed to skip and how that affects the application.
Common Mistakes to Avoid
A common mistake is treating nlist and nprobe as isolated settings instead of connected parts of the same retrieval behavior. Increasing nlist without increasing nprobe can make recall worse if relevant neighbors are split across more cells. Increasing nprobe without considering list sizes can make latency worse than expected. The two settings should be evaluated together.
Another mistake is tuning only on average latency. IVF queries can vary because different probed cells may contain different numbers of vectors. If the index has uneven list sizes, some queries may scan many more candidates than others. Looking at percentile latency and list balance can reveal issues that average numbers hide.
Teams also sometimes evaluate IVF with queries that do not represent real usage. A benchmark query set should reflect the kinds of questions, items, documents, or user behaviors the application actually serves. Otherwise, the chosen settings may look good in testing but underperform once real users begin querying the system.
Finally, it is risky to assume that higher recall always creates a better application. Higher nprobe may retrieve more accurate nearest neighbors, but it also costs more. For some applications, slightly lower recall with much better latency may produce a better user experience. For others, such as high-stakes knowledge retrieval, the extra search cost may be justified.
With those mistakes in mind, the most durable way to understand IVF is to remember the full flow: train centroids, assign vectors to cells, probe nearby cells, and tune the search width against real retrieval goals.
FAQs
1. What does IVF stand for in vector search?
IVF stands for Inverted File Index. In vector search, it is an index that partitions embeddings into centroid-based lists so the system can search a smaller candidate set instead of comparing the query against every vector in the database.
2. Why does IVF use k-means clustering?
IVF uses k-means because k-means provides a practical way to divide a vector space into clusters. Each cluster has a centroid, and each stored vector can be assigned to the nearest centroid. This creates the inverted lists that IVF searches later.
3. What is a Voronoi cell in IVF?
A Voronoi cell is the region of space closest to a particular centroid. In IVF, each centroid’s Voronoi cell corresponds to an inverted list of vectors assigned to that centroid. The query searches the cells whose centroids are closest to the query vector.
4. What is the difference between nlist and nprobe?
nlist controls how many centroid lists are created when the index is built. nprobe controls how many of those lists are searched for a query. nlist shapes the index structure, while nprobe controls the query-time search width.
5. Does higher nprobe always improve search quality?
Higher nprobe usually improves recall because the search examines more cells and more candidate vectors. However, it also increases latency and compute cost. The right value depends on how much recall the application needs and how much query time it can afford.
6. Is IVF better than flat vector search?
IVF is often faster than flat search on large datasets because it avoids scanning every vector. Flat search can be more accurate because it is exhaustive. IVF is better when the speed gain is worth the approximate retrieval tradeoff, while flat search is often better for small datasets or use cases that require exact nearest neighbors.
Takeaway
IVF is a practical way to make vector search faster by using k-means centroids to divide embedding space into Voronoi-like cells, assigning each vector to its nearest centroid, and searching only the nprobe nearest cells for each query. The method is most useful for teams building AI database systems that need scalable semantic search, recommendations, or retrieval-augmented generation over large embedding collections. The key lesson is that IVF performance depends on tuning nlist and nprobe together: nlist controls the granularity of the index, nprobe controls the breadth of each search, and the best balance is the one that meets the application’s recall, latency, and cost requirements.
Watch this video to learn more