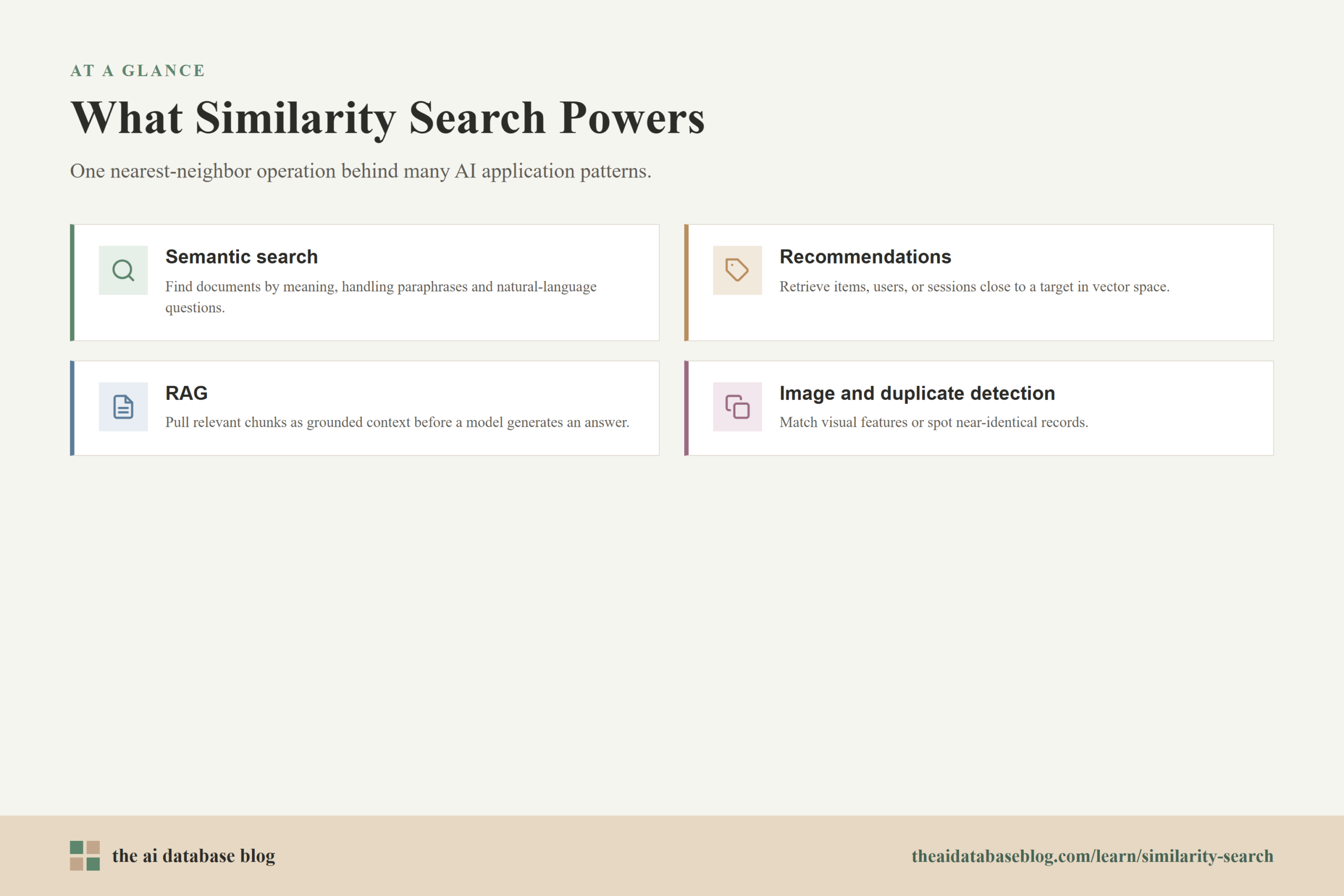
Similarity search is the process of finding data items that are closest in meaning, pattern, or behavior to a query, rather than looking only for exact keyword matches. In AI databases, similarity search usually works by comparing vectors, also called embeddings, and returning the top-K nearest results ranked by a distance or similarity score. This is the core operation behind vector databases, and it powers semantic search, recommendations, retrieval-augmented generation, image search, duplicate detection, and many other AI application patterns.
This guide explains how similarity search works inside an AI database, why vectors make semantic comparison possible, how distance metrics affect ranking, what top-K results mean, and why exact and approximate search are used in different situations. By the end, you should understand how similarity search turns unstructured data into searchable AI memory and why it has become a foundational part of modern retrieval systems.
Similarity Search Finds Near Matches Instead Of Exact Matches
Traditional database search is usually built around exact values, structured filters, or text tokens. If a user searches for a product ID, a database can look for that exact ID. If a user filters for documents created after a certain date, the database can compare stored dates against the requested condition. Even keyword search, while more flexible than a strict equality check, still depends heavily on whether the words in the query overlap with words in the indexed text.
Similarity search answers a different kind of question: which stored items are most like this query? The query might be a sentence, a paragraph, a support ticket, an image, an audio clip, a user profile, or a product description. Instead of requiring exact word overlap, the system compares the query to stored items by their position in a mathematical space. Items that sit close together in that space are treated as more similar.
This is especially useful for AI applications because many user questions are semantic rather than literal. A user might ask, “How do I reset access after losing my password?” while the relevant document says “account recovery after credential loss.” A keyword system may miss that relationship unless the words overlap or synonyms are manually configured. Similarity search can retrieve the document because the two pieces of text express related meaning.
The reason this works is that AI systems convert data into embeddings before search happens. To understand similarity search clearly, the next step is to understand what those embeddings represent and why vector databases are designed around them.
The Core Operation Of A Vector Database
The core operation of a vector database is nearest-neighbor search. A vector database stores embeddings for many records, then accepts a query embedding and finds the stored embeddings that are closest to it. Each stored vector is usually connected to useful payload data, such as a document chunk, product record, image ID, metadata fields, or the original text that produced the embedding.
An embedding is a list of numbers produced by a machine learning model. The exact numbers are not meaningful to a human reader by themselves, but their position relative to other vectors is meaningful. If two text passages have similar meaning, their embeddings tend to be close in vector space. If two images have similar visual features, their embeddings may be close as well. The database does not need to understand the content in a human way; it needs to compare the vectors efficiently and return the nearest records.
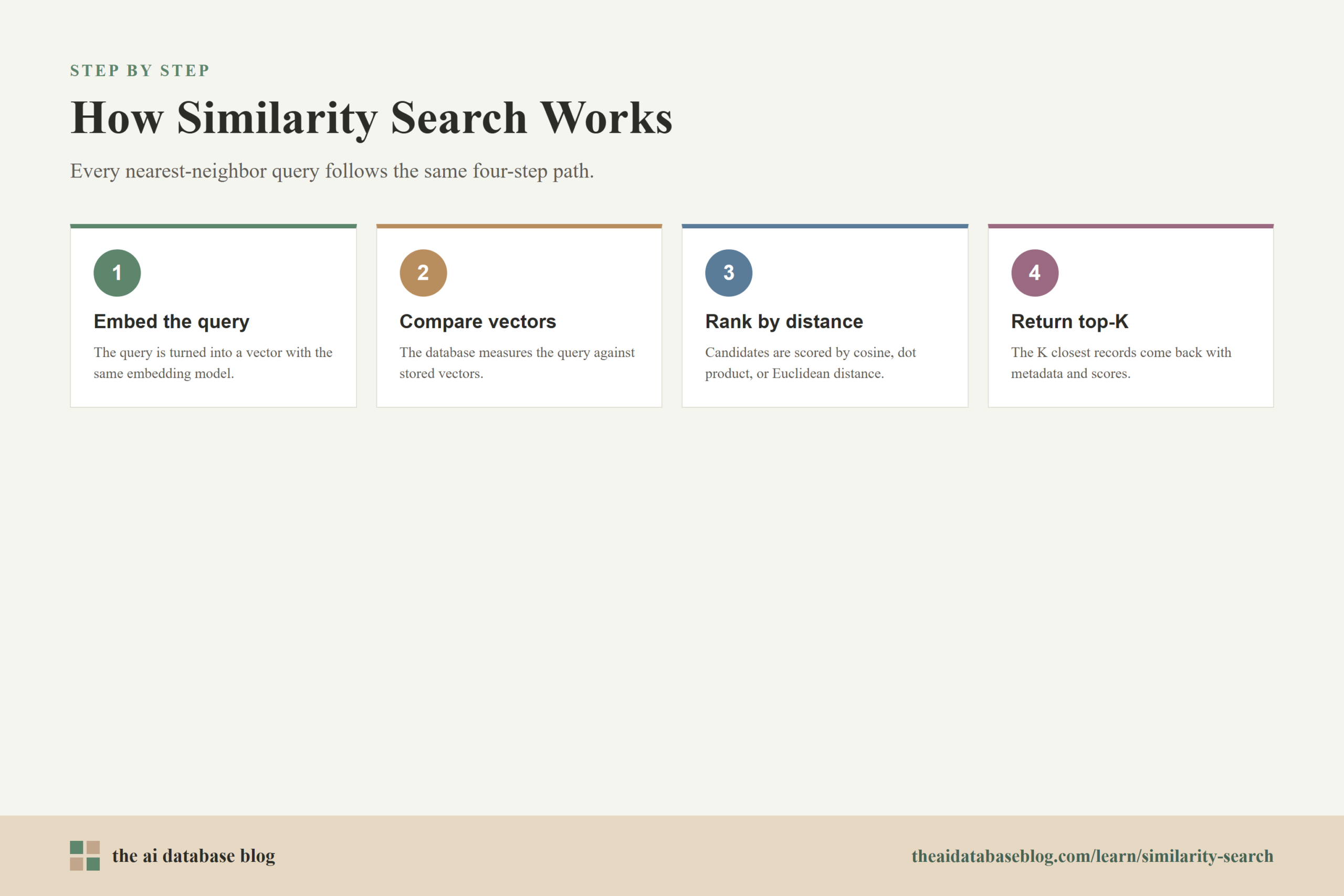
A typical similarity search workflow has four steps:
- The application converts the query into an embedding using the same embedding model or a compatible model.
- The vector database compares the query vector against stored vectors.
- The database ranks candidates by a distance or similarity metric.
- The application receives the top-K results, often with metadata and scores.
This makes vector databases different from ordinary storage systems. They are not only storing vectors; they are optimized to compare vectors quickly, rank likely matches, and combine vector search with practical database features such as metadata filtering, updates, batching, and result retrieval.
Once the basic workflow is clear, the next important question is how the database decides which vectors are close. That decision depends on the distance or similarity metric used for ranking.
Ranking By Distance And Similarity
Similarity search depends on a scoring method. The database needs a way to compare the query vector with each candidate vector and decide which records are most relevant. This is usually described as ranking by distance, although some systems express the score as similarity instead. A smaller distance generally means the vectors are closer. A higher similarity score generally means the vectors are more alike.
The most common metrics are cosine similarity, dot product, and Euclidean distance. They all compare vectors, but they emphasize slightly different relationships. The right choice often depends on the embedding model, how the vectors were trained, and whether the vectors are normalized.
Cosine Similarity
Cosine similarity compares the angle between two vectors rather than focusing on their raw length. It is often used for text embeddings because it captures whether two vectors point in a similar direction in semantic space. In practical terms, cosine similarity can help identify passages that discuss similar ideas even if one passage is longer, shorter, or phrased differently from the other.
Dot Product
Dot product measures how strongly two vectors align, while also being affected by vector magnitude unless the vectors are normalized. Some embedding models are designed to work well with dot product scoring. When the model documentation recommends dot product, using a different metric can reduce relevance because the database ranking no longer matches the model’s training assumptions.
Euclidean Distance
Euclidean distance measures straight-line distance between vectors. It is intuitive because it is similar to measuring distance between points on a map, except the space may have hundreds or thousands of dimensions. Euclidean distance can be useful when the embedding model and index are designed around physical closeness in vector space.
The key point is that similarity search is not magic matching. It is a ranking operation based on a defined measurement. The embedding model creates the space, the metric measures closeness inside that space, and the database returns the records that score best under that measurement.
Distance ranking explains how results are ordered, but most applications do not want every possible match. They need a manageable set of the best candidates. That is where top-K retrieval becomes central.
What Top-K Results Mean
Top-K search means returning the K closest results to a query. If K is 5, the database returns the five nearest records. If K is 20, it returns the twenty nearest records. The number is chosen by the application based on how many candidates it needs for the next step in the workflow.
Top-K is important because similarity search is usually used as a candidate selection step. A search interface may show the top 10 documents to a user. A recommendation system may retrieve the top 50 similar products and then rerank them using business rules or personalization signals. A RAG system may retrieve the top 5 or top 20 chunks and pass a smaller final set into a language model as context.
Choosing K is a tradeoff. A small K can be faster and easier to inspect, but it may miss useful results that are just outside the cutoff. A large K gives downstream systems more candidates to work with, but it can increase latency, cost, and the chance of including less relevant material. Many systems retrieve a somewhat larger candidate set first, then rerank or filter it before showing results or using them in generation.
Top-K results often include a score, but that score should be interpreted carefully. Scores are most useful for comparing results within the same query, metric, model, and index setup. A score from one embedding model may not mean the same thing as a score from another model. Likewise, a threshold that works for one dataset may not transfer cleanly to another dataset.
Top-K retrieval gives the application a practical output, but the database still has to find those nearest vectors efficiently. For small datasets, it may be possible to compare everything directly. For large datasets, that can become too slow, which leads to the difference between exact and approximate similarity search.
Exact Similarity Search Versus Approximate Similarity Search
Exact similarity search checks the query against every relevant stored vector and returns the true nearest neighbors according to the chosen metric. This is sometimes called brute-force search or exact nearest-neighbor search. It is straightforward and accurate, but it can become expensive when the database contains millions or billions of vectors, especially when vectors have many dimensions and queries must return quickly.
Approximate similarity search uses an index or algorithm to find near neighbors without comparing the query against every vector. This is commonly called approximate nearest neighbor search, or ANN. The goal is to return results that are close enough to the exact nearest results while using much less time, memory, or compute at query time.
Approximate search is widely used because AI applications often need fast retrieval over large embedding collections. Instead of scanning the entire dataset, the database may use graph-based indexes, clustering methods, quantization, or combinations of these techniques to narrow the search. The result is a practical tradeoff: the system may not always return the mathematically perfect nearest neighbors, but it can respond quickly enough for real products.
When Exact Search Makes Sense
Exact search is useful when the dataset is small enough that exhaustive comparison is affordable, when correctness is more important than speed, or when the system is being used to evaluate the quality of an approximate index. It can also make sense during development because exact results provide a baseline for measuring recall, which is the percentage of true nearest neighbors that the approximate search successfully returns.
When Approximate Search Makes Sense
Approximate search is useful when latency, scale, and cost matter. Most production semantic search, recommendation, and RAG systems eventually need some form of approximate retrieval because the number of stored vectors grows quickly. Every document chunk, product, image, conversation, or event can become a vector. As the collection grows, scanning everything for every query becomes harder to justify.
The Practical Tradeoff
The tradeoff is not simply accuracy versus inaccuracy. A well-tuned approximate index can return highly relevant results while reducing query time dramatically. The practical question is whether the approximation preserves enough recall for the application. A product recommendation system may tolerate a little variation if the returned items are still useful. A legal, medical, or compliance retrieval workflow may require stricter evaluation, careful filtering, and possibly exact reranking of candidate results.
Exact and approximate search explain how a vector database finds candidates, but similarity search becomes most valuable when it is connected to real application workflows. The same basic operation can support search, recommendations, and RAG in slightly different ways.
How Similarity Search Powers Search
In search applications, similarity search helps users find information by meaning instead of by exact wording. This is often called semantic search. The system embeds the user’s query, compares it with stored content embeddings, and returns the nearest documents, passages, products, tickets, or records. The result is a search experience that can handle paraphrases, related concepts, and natural-language questions more gracefully than keyword matching alone.
For example, a knowledge base may contain an article titled “Account Recovery After Credential Loss.” A user may search for “I forgot my password and cannot log in.” Keyword overlap may be limited, but the meanings are close. Similarity search can rank the account recovery article highly because the query and document occupy nearby regions in embedding space.
Many practical search systems combine similarity search with other retrieval methods. Keyword search can be strong for exact names, codes, error messages, and rare terms. Vector search can be strong for meaning, paraphrase, and concept matching. Hybrid search combines these signals so the system can handle both semantic intent and exact textual constraints.
Search is the most direct use of similarity search, but the same nearest-neighbor idea also works when the query is not a typed question. In recommendations, the query can be a user, item, session, or behavior pattern.
How Similarity Search Powers Recommendations
Recommendation systems use similarity search to find items, users, or behaviors that are close to a target. The query might be the embedding of a product a user is viewing, a profile representing a user’s interests, or a session embedding based on recent activity. The database returns nearby items that are likely to be relevant because they share semantic, behavioral, or visual patterns with the query.
For an ecommerce example, a product’s title, description, category, image, and historical interaction signals can be represented as vectors. When a user views that product, similarity search can retrieve nearby products that are similar in purpose, style, or use case. The recommendation layer may then rerank those candidates based on price, availability, diversity, user history, or business constraints.
This candidate retrieval pattern is useful because recommendations often need to search across large catalogs quickly. The vector database does not need to make the final recommendation decision by itself. Instead, it provides a strong candidate set that another ranking system can refine.
Recommendations show that similarity search is not limited to documents. It can retrieve any object that can be embedded. That flexibility is also why similarity search has become a major part of retrieval-augmented generation.
How Similarity Search Powers RAG
Retrieval-augmented generation, or RAG, uses retrieval to provide a language model with relevant external context before it generates an answer. Similarity search is often the retrieval step. The application embeds the user’s question, searches a vector database for the most relevant text chunks, and places selected chunks into the prompt or context window for the model to use.
This helps because language models do not automatically know the latest or private information inside an organization’s documents, tickets, policies, manuals, or databases. Similarity search gives the application a way to retrieve that information at query time. The model can then generate an answer grounded in retrieved context rather than relying only on what it learned during training.
A basic RAG pipeline usually looks like this:
- Split source documents into chunks that are large enough to carry meaning but small enough to retrieve precisely.
- Create embeddings for each chunk and store them in a vector database with metadata.
- Embed the user’s question when a query arrives.
- Run a top-K similarity search to retrieve candidate chunks.
- Optionally filter, rerank, or deduplicate the retrieved chunks.
- Send the best context to the language model along with the user’s question.
Good RAG depends on more than vector search alone. Chunking, metadata filters, hybrid search, reranking, permissions, freshness, and evaluation all affect answer quality. Still, similarity search is often the operation that connects a user’s question to the most relevant stored knowledge.
Because similarity search sits at the center of these workflows, it is helpful to know the common design decisions that affect quality and performance before building around it.
Practical Design Choices That Affect Similarity Search
Similarity search quality depends on several choices made before and after the database query. The vector database can rank vectors efficiently, but the relevance of the results depends on how the data was embedded, indexed, filtered, and evaluated. A system with a strong index but poor chunking or mismatched metrics can still return weak results.
Embedding Model Choice
The embedding model determines what kinds of similarity the system can detect. A text embedding model is useful for semantic text search, while a multimodal model may be needed for image-text retrieval. The metric used in the database should match the model’s recommended scoring behavior whenever possible.
Chunking And Data Modeling
For document retrieval, chunk size affects precision and context. Chunks that are too large may include irrelevant material alongside relevant content. Chunks that are too small may lose the context needed to answer a question. Metadata such as source, date, author, access level, product area, and document type can help narrow the search before or after vector ranking.
Filtering And Hybrid Retrieval
Similarity search is often strongest when combined with filters or keyword signals. Metadata filters can restrict retrieval to records the user is allowed to see or to content from a specific category. Hybrid search can combine semantic matching with lexical matching, which is useful for queries that include exact identifiers, technical terms, names, or error codes.
Evaluation And Tuning
Teams should evaluate similarity search with real queries and expected results. Useful measures include recall, precision, latency, and downstream task quality. In RAG, the best retrieval setup is the one that helps the final answer become more accurate, complete, and grounded. In recommendations, the best setup may be measured by engagement, conversion, diversity, or user satisfaction.
These choices show why similarity search should be treated as a retrieval system design problem, not just a database feature. The database provides the fast nearest-neighbor operation, but the application determines what should be embedded, how results should be filtered, and how relevance should be judged.
Common Mistakes To Avoid
Similarity search is powerful, but it can be misunderstood. One common mistake is assuming that a vector database automatically understands truth, quality, or authority. It does not. It ranks items based on vector closeness. A result can be semantically similar to a query while still being outdated, incomplete, low quality, or not permitted for a specific user.
Another mistake is treating the top result as always correct. Similarity scores are ranking signals, not proof. In RAG systems, retrieved chunks should be checked for relevance, deduplicated when needed, and combined carefully before generation. In user-facing search, result quality should be evaluated with real user queries rather than only with synthetic examples.
A third mistake is ignoring metadata. Vectors are excellent for meaning-based comparison, but metadata helps enforce boundaries. If a user asks about a specific product version, date range, region, or access-controlled document set, metadata filters can prevent the system from returning semantically similar but contextually wrong results.
Finally, teams sometimes tune only for speed. Low latency matters, but a fast system that retrieves the wrong information is not useful. The best similarity search systems balance speed, recall, precision, permissions, and downstream quality for the actual application.
With those cautions in mind, the main idea becomes simpler: similarity search is a practical way to retrieve useful candidates from large collections of embedded data, but it works best when the surrounding retrieval design is deliberate.
FAQs
1. What is similarity search in simple terms?
Similarity search is a way to find items that are most like a query. Instead of asking whether two values match exactly, it asks which stored items are closest in meaning, pattern, or features. In AI databases, that comparison usually happens between vector embeddings.
2. Why is similarity search the core operation of a vector database?
A vector database is designed to store embeddings and retrieve the nearest embeddings to a query vector. That nearest-neighbor operation is what makes the database useful for semantic search, recommendations, RAG, and other AI retrieval workflows.
3. What does top-K mean in similarity search?
Top-K means the database returns the K closest results to the query. If K is 10, the system returns the ten nearest records based on the chosen distance or similarity metric. Applications choose K based on how many candidates they need for display, reranking, or generation.
4. Is approximate similarity search inaccurate?
Approximate similarity search is not the same as random or careless search. It uses indexes and algorithms to find very close matches faster than exhaustive comparison. The tradeoff is that it may not always return the mathematically exact nearest neighbors, so teams measure recall and tune the index for their needs.
5. How does similarity search help RAG?
In RAG, similarity search retrieves relevant chunks of external knowledge for a user’s question. Those chunks are then provided to a language model as context, helping the model answer with information from the application’s documents or data instead of relying only on its training.
6. Can similarity search replace keyword search?
Similarity search can solve problems that keyword search handles poorly, especially paraphrase and semantic matching. However, keyword search is still useful for exact terms, names, codes, and rare phrases. Many strong systems combine both approaches through hybrid retrieval.
Takeaway
Similarity search is the retrieval operation that lets AI databases find the nearest records to a query by comparing embeddings. It ranks results by distance or similarity, returns a top-K candidate set, and can run exactly for smaller or stricter workloads or approximately for large-scale, low-latency systems. This guidance is most useful for builders, product teams, and technical readers who want to understand how vector databases support semantic search, recommendations, and RAG; for example, a support assistant can use similarity search to retrieve the most relevant policy or troubleshooting chunks before generating a grounded answer.
Watch this video to learn more