Self-hosted vector databases give teams the most control over infrastructure, data placement, configuration, and long-term cost, but they also make the team responsible for deployment, scaling, monitoring, backups, upgrades, security, and incident response. Managed vector databases reduce that operational burden and usually help teams move faster, but they can cost more at scale and may limit some infrastructure choices. Bring your own cloud, often called BYOC, sits between the two by running the database in the customer’s cloud environment while the provider handles part of the management layer.
This guide explains how to compare self-hosted, managed, and BYOC vector database deployments for AI applications. It covers the practical tradeoffs around control, cost, reliability, compliance, operational work, team size, scale, and expertise, so readers can choose a deployment model that fits their retrieval workload rather than defaulting to the option that looks simplest at the start.

What Deployment Model Means for a Vector Database
A vector database stores embeddings and supports similarity search, usually with metadata filtering and sometimes hybrid search that combines vector search with keyword search. The deployment model describes who runs the infrastructure behind that database and who is responsible when it needs to scale, recover, update, or meet security requirements. This matters because vector search is not just a storage problem. It is also a performance, relevance, and operations problem.
In a self-hosted deployment, the organization runs the vector database itself. That might mean a single instance for a small internal tool, a Kubernetes deployment for a production application, or an on-premises environment for workloads with strict data location rules. The organization controls the cloud account, compute resources, network design, version upgrades, index configuration, and observability stack.
In a managed deployment, the provider runs the database service. The customer still designs the application, manages the data model, chooses embeddings, controls access, and evaluates retrieval quality, but the provider takes on much of the infrastructure work. This usually includes provisioning, availability, scaling mechanics, patching, and platform-level monitoring.
BYOC is a hybrid model. The database infrastructure runs inside the customer’s cloud account or private network boundary, but the provider manages some or most of the database operations. It is useful when a team wants managed-service help but cannot place the workload entirely inside a provider-owned cloud environment because of governance, network isolation, procurement, or compliance constraints.
Once the deployment models are clear, the next question is not simply which one is better. The better question is which responsibilities your team is ready to own, and which ones would distract from building the AI product itself.
Self-Hosted Vector Databases: Control and Cost With More Responsibility
Self-hosting is attractive because it gives teams direct control over the database environment. They can choose instance types, storage classes, regions, network topology, backup tooling, deployment cadence, and resource limits. For teams with strong infrastructure skills, this control can make the system easier to tune for a specific retrieval workload. It can also reduce vendor dependency because the team is operating the database on its own infrastructure.
The cost argument for self-hosting is strongest when usage is steady, predictable, and large enough for infrastructure efficiency to matter. A team running high query volume or storing many embeddings may be able to lower unit costs by reserving capacity, using existing cloud commitments, tuning hardware choices, and avoiding managed-service premiums. This is especially relevant when the organization already has platform engineers, database administrators, or site reliability practices in place.
However, self-hosting does not mean the database is free. It shifts costs from the vendor bill to infrastructure spend and staff time. The team must operate the system through normal production realities: index growth, memory pressure, disk usage, tail latency, reindexing, replication, failover, authentication, access control, incident response, and backup recovery. If those responsibilities are new to the team, the real cost can be much higher than the raw cloud bill suggests.
Where Self-Hosting Works Well
Self-hosting tends to work well when the organization has a mature operations function and a clear reason to own the database environment. Examples include regulated workloads with strict data locality requirements, high-scale applications where managed-service pricing becomes expensive, and systems that need unusual infrastructure choices or deep customization. It can also fit internal AI platforms where the vector database is one component in a larger self-operated data stack.
Where Self-Hosting Becomes Risky
Self-hosting becomes risky when the team underestimates operational load. A vector database may start as a simple semantic search index, but production usage quickly introduces harder requirements. The team needs to know what happens when an embedding model changes, when metadata filters become more complex, when query traffic spikes, when a node fails, or when an index rebuild affects latency. If nobody owns those questions, self-hosting can slow the product down instead of saving money.
Self-hosting gives the most control, but control only helps when the team can turn it into reliable operations. That leads naturally to the managed option, where the goal is to reduce the number of infrastructure details the application team has to carry.
Managed Vector Databases: Faster Adoption With Less Operational Burden
Managed vector databases are designed to reduce the work required to launch and operate vector search. Instead of provisioning and maintaining every infrastructure component, teams can create an index or collection, load embeddings, configure metadata, and connect the database to the application. For many AI products, this is the fastest path from prototype to production because it lets engineers focus on retrieval quality, data pipelines, and user experience.
The biggest advantage is operational simplicity. Managed services usually handle infrastructure provisioning, routine maintenance, patching, availability architecture, scaling workflows, and parts of monitoring. That does not remove all responsibility from the customer, but it narrows the customer’s operational surface. The team still needs to design good schemas, protect sensitive data, track retrieval performance, and evaluate answer quality, but it spends less time keeping the database alive.
Managed deployments are especially useful when traffic is variable or uncertain. Early AI applications often move through stages: small prototype, internal pilot, customer beta, production launch, then sudden growth after adoption. A managed service can absorb more of that uncertainty because the platform is built around easier provisioning and elasticity. This can be worth more than cost optimization when the team is still proving the application.
The Cost Tradeoff in Managed Services
Managed services often cost more than raw infrastructure when usage becomes large and predictable. The price includes not only compute and storage, but also the provider’s platform, reliability work, support, automation, and margin. That can be a good trade when the alternative is hiring or distracting engineers to manage the system. It becomes less attractive when a team has enough scale and expertise to operate the database efficiently itself.
The Control Tradeoff in Managed Services
The tradeoff is that managed services can limit certain choices. A team may have fewer options for low-level index tuning, infrastructure placement, deployment topology, private networking patterns, or maintenance timing. Some of these limits are acceptable for most applications. Others matter for organizations with strict compliance, latency, procurement, or data residency needs. The right question is not whether managed services provide enough control in general, but whether they provide enough control for the workload in front of the team.
Managed services reduce operational effort, but not every organization can accept a provider-owned environment. That is where BYOC enters the comparison, because it tries to preserve more infrastructure control while still reducing the day-to-day burden of running the database.
BYOC: The Middle Ground Between Self-Hosted and Managed
BYOC stands for bring your own cloud. In a vector database context, it usually means the data plane runs inside the customer’s cloud account, virtual private cloud, or controlled network environment, while the provider manages the control plane, operational automation, or support layer. The exact responsibility split varies by provider and contract, so teams should inspect the architecture carefully rather than assuming every BYOC offering works the same way.
The appeal of BYOC is that it can satisfy requirements that a standard managed service may not meet. Data can remain inside the organization’s chosen cloud boundary. Network access can align with internal controls. Cloud spend may flow through existing accounts or commitments. Security teams may get more comfort because infrastructure is visible in the organization’s environment rather than fully abstracted away.
At the same time, BYOC is not the same as self-hosting. The provider may still handle deployment automation, upgrades, monitoring, scaling guidance, and database support. This can reduce the burden on internal teams while preserving more control than a fully managed service. For organizations that have compliance requirements but limited database operations capacity, BYOC can be a practical compromise.
What to Verify Before Choosing BYOC
Because BYOC models vary, teams should verify the responsibility boundary before committing. Important questions include who can access the environment, how upgrades are applied, where logs and metrics are stored, how backups work, what happens during an incident, how support engineers connect, and whether data ever leaves the customer-controlled environment. These details matter more than the BYOC label itself.
When BYOC Is Worth Considering
BYOC is worth considering when the organization wants managed help but has firm requirements around data residency, network isolation, security review, or cloud account ownership. It may also fit companies that are scaling beyond a simple managed deployment but are not ready to build a full internal database operations team. The main tradeoff is complexity: BYOC often requires more setup and coordination than a standard managed service, even if it requires less ongoing work than self-hosting.
With all three models on the table, the decision becomes more practical. The strongest choice depends on the team’s maturity, workload scale, compliance needs, and tolerance for operational responsibility.
How Team Size Should Influence the Choice
Team size matters because every deployment model assigns work to someone. A small team may be able to build an impressive retrieval application, but that does not mean it can safely operate a production vector database around the clock. A larger team may have the staff to self-host, but it still needs to decide whether database operations are worth the attention compared with product work.
For solo developers and small startups, managed services are often the most practical default. The team can move quickly, test the product idea, and avoid spending early engineering time on infrastructure automation. If costs become meaningful later, the team can revisit the deployment model with better knowledge of query volume, vector count, latency needs, and customer requirements.
For growing teams with a few backend or platform engineers, the answer is more mixed. A managed deployment may still be the best fit for a customer-facing product where uptime and speed of delivery matter most. Self-hosting may make sense for internal tools, controlled workloads, or teams already comfortable operating databases. BYOC can be useful if customer requirements demand more infrastructure control before the team is ready to fully self-operate.
For larger organizations with dedicated platform, security, and data infrastructure teams, self-hosting and BYOC become more realistic. These teams can build runbooks, automate deployment, monitor performance, manage access controls, and recover from failures. Even then, managed services may remain attractive for non-core workloads or teams that want to avoid adding another specialized system to their internal operations portfolio.
Team size gives a useful starting point, but it is not enough by itself. A small expert team may self-host successfully, while a large team without vector search experience may prefer managed infrastructure. The next lens is scale, because scale changes both cost and operational risk.
How Scale Changes the Cost and Operations Equation
Scale affects vector databases in several ways. More vectors increase storage and indexing needs. More queries increase compute pressure and make tail latency more important. More metadata filters can change query performance. More tenants or user groups can complicate isolation, access control, and data lifecycle management. A deployment model that works for a prototype may not fit the same system after it becomes a high-traffic retrieval layer.
At small scale, managed services usually have the advantage because convenience matters more than deep cost optimization. The database bill is often easier to justify than the engineering time required to operate a self-hosted cluster. The main job is to learn what the application needs: how many embeddings it stores, how often they change, what latency users expect, and how retrieval quality affects the product.
At medium scale, teams should start calculating total cost of ownership rather than comparing only monthly service prices. Total cost includes cloud resources, support plans, engineering time, on-call coverage, monitoring tools, backup storage, incident handling, and the opportunity cost of slower product development. Managed services may still win if operations would distract the team. Self-hosting may win if usage is predictable and the team already has strong infrastructure practices.
At large scale, self-hosting or BYOC can become more compelling, especially for steady workloads with high query volume or large embedding collections. The team may be able to tune infrastructure more precisely and reduce unit costs. But the operational burden also grows: scaling plans, index maintenance, disaster recovery, security audits, and performance debugging all become more important. Large scale does not automatically mean self-hosting is best; it means the cost of the wrong operating model becomes more visible.
Scale can make cost differences obvious, but expertise determines whether a team can safely act on those differences. The next section connects the infrastructure choice to the skills required to keep retrieval reliable.
How Expertise Should Shape the Decision
Vector database expertise is not only about knowing how similarity search works. It also includes understanding how embeddings are generated, how indexes affect latency and recall, how metadata filtering interacts with search, how to monitor query behavior, and how to recover when data or infrastructure changes. A team choosing a deployment model should be honest about which of these skills it already has and which it would need to build.
Self-hosting requires the broadest expertise. The team needs database operations skills, cloud infrastructure skills, security skills, and enough vector search knowledge to tune the system responsibly. It also needs a clear ownership model. If the application team assumes the platform team will handle incidents, and the platform team assumes the application team understands the database, failures can fall between the cracks.
Managed services require less infrastructure expertise but still require retrieval expertise. A managed service will not automatically choose the right chunking strategy, embedding model, metadata schema, tenant design, or evaluation method. It may keep the database available, but the application team still owns whether search results are useful, current, secure, and grounded in the right data.
BYOC requires a blend of skills. The provider may operate much of the database, but the customer’s cloud, security, and networking teams still need to understand the environment. This makes BYOC a good fit for organizations that have cloud governance expertise but do not want to own every database maintenance task. It is less ideal when the organization wants a completely hands-off experience.
Once expertise is part of the decision, the best choice becomes easier to frame. The goal is not to maximize control or minimize responsibility in isolation. The goal is to match responsibility to the team that can handle it best.
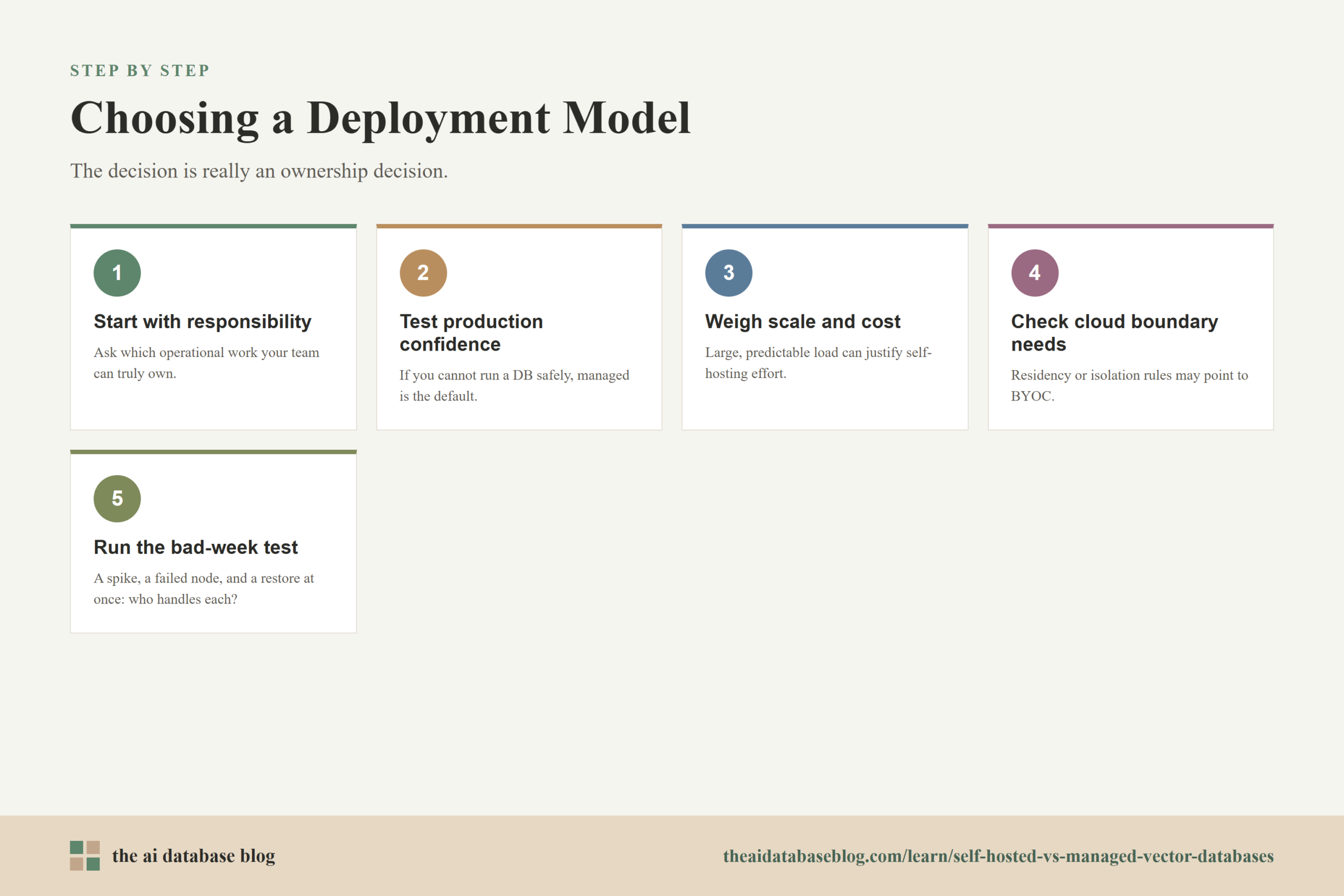
A Practical Decision Framework
The simplest way to choose is to start with responsibility, then test the answer against cost and control. If the team cannot operate a production database confidently, a managed service is usually the safest starting point. If the team has strong operations skills and a workload large enough to justify the work, self-hosting deserves serious consideration. If the organization needs infrastructure control but also wants managed support, BYOC may be the right middle path.
Choose a managed vector database when speed, simplicity, and reliability support matter more than deep infrastructure control. This is common for early products, small teams, variable workloads, and organizations that want engineers focused on product and retrieval quality rather than database operations.
Choose self-hosting when control, customization, data placement, or cost efficiency at scale are more important, and when the team has the operational maturity to support that choice. This is common for large workloads, internal AI platforms, regulated environments with strict infrastructure policies, and teams that already operate production databases successfully.
Choose BYOC when the organization needs the database to run in its own cloud environment but still wants help with management, support, and operations. This is common when security, compliance, data residency, or cloud-account ownership requirements rule out a standard managed service, but full self-hosting would create too much operational burden.
A useful final test is to ask what would happen during a bad week: a traffic spike, a failed node, an urgent security patch, a backup restore, and a retrieval-quality regression all at once. If the team knows who handles each problem and has the tools to do it, self-hosting may be reasonable. If the answer is unclear, managed or BYOC options are likely safer.
Common Mistakes to Avoid
One common mistake is comparing only the monthly database bill. A cheaper self-hosted cluster can become expensive if it consumes senior engineering time, creates downtime, or delays product work. A more expensive managed service can be a good investment if it keeps the team focused on building and evaluating the AI application.
Another mistake is assuming managed means no responsibility. The provider may operate the platform, but the customer still owns data quality, access control decisions, retrieval evaluation, embedding updates, and application behavior. Managed infrastructure can reduce operational burden, but it does not replace good AI database design.
A third mistake is treating BYOC as a magic compromise without checking the details. BYOC can be powerful, but only if the responsibility split is clear. Teams should understand how support access works, where data and logs live, how upgrades happen, what is monitored, and who responds to incidents. Without that clarity, BYOC can become confusing instead of simplifying the deployment.
These mistakes all point to the same lesson: the deployment decision is really an ownership decision. The right model is the one that makes ownership clear, affordable, and sustainable for the team that has to run the application.
FAQs
1. Is a self-hosted vector database always cheaper than a managed one?
No. Self-hosting can reduce direct infrastructure or service costs at scale, but it also adds engineering, monitoring, maintenance, backup, security, and incident-response costs. It is usually cheaper only when the workload is large or predictable enough and the team already has the skills to operate it efficiently.
2. When should a small team choose a managed vector database?
A small team should usually choose managed when it needs to move quickly, validate a product idea, support production users, or avoid building database operations capability too early. Managed services let the team spend more time on retrieval quality, application behavior, and customer feedback.
3. What does BYOC mean for vector databases?
BYOC means bring your own cloud. In practice, the vector database runs in the customer’s cloud account or controlled network environment, while the provider manages part of the database service. It is meant to combine stronger infrastructure control with some of the operational benefits of a managed service.
4. Does BYOC remove all operational responsibility from the customer?
No. BYOC usually reduces operational work, but the customer still owns parts of the cloud environment, security review, networking, access policies, cost management, and application-level retrieval behavior. The exact split depends on the provider’s architecture and support agreement.
5. What should teams monitor in a self-hosted vector database?
Teams should monitor query latency, throughput, memory usage, CPU usage, disk usage, index health, replication status, backup success, error rates, and retrieval behavior. They should also track application-level signals such as whether search results are relevant, fresh, and properly filtered by permissions or metadata.
6. Can a team switch from managed to self-hosted later?
Sometimes, but the migration can be more involved than it looks. Teams need to move embeddings, metadata, schemas, indexes or index settings, access controls, and application integrations. Planning for portability early can help, especially by keeping data models clear and avoiding unnecessary coupling to one deployment environment.
Takeaway
Self-hosted, managed, and BYOC vector databases each solve a different ownership problem. Self-hosting is best for teams that need maximum control and have the expertise to operate the system reliably, managed services are best for teams that value speed and reduced operational burden, and BYOC is useful when an organization needs its own cloud boundary without taking on every database task alone. This guidance is most useful for engineering leaders, platform teams, and AI application builders choosing infrastructure for retrieval-augmented generation, semantic search, recommendation, or knowledge retrieval systems where performance, cost, compliance, and team capacity all matter.
Watch this video to learn more