Score fusion is the process of combining results from different retrieval methods, such as keyword search and vector search, into one ranked list. The key challenge is that these methods produce scores with different meanings, scales, and distributions, so their raw numbers usually cannot be added directly. Reciprocal rank fusion solves this by using only result positions, while relative score fusion normalizes each method’s scores and blends them with a tunable balance between lexical and semantic relevance.
This guide explains why raw retrieval scores are not directly comparable, how reciprocal rank fusion and relative score fusion work, and how to tune the balance between keyword and vector signals in an AI database or retrieval system. By the end, you should understand when rank-based fusion is safer, when normalized score blending can preserve more useful signal, and how to evaluate the right settings for a real search or retrieval-augmented generation application.
Why Score Fusion Matters in AI Databases
AI databases often support more than one way to find relevant content. A keyword method such as BM25 is good at matching exact terms, rare words, identifiers, product names, error codes, and phrases that should appear literally in the document. A vector method is good at matching meaning, intent, paraphrases, and conceptually similar text even when the query and document do not use the same words. Hybrid retrieval combines these strengths by running both methods and merging their results.
The fusion step matters because the two methods often disagree. A keyword search might rank a document highly because it contains an exact phrase, while vector search might rank a different document highly because it captures the user’s intent more completely. The retrieval system needs a principled way to decide which documents rise to the top, which documents remain candidates for reranking, and which documents are left out of the final context window.
In an AI application, this decision can affect the entire user experience. For a support chatbot, score fusion may determine whether the model sees the precise troubleshooting article or a semantically related but less actionable overview. For enterprise search, it may determine whether a query for a policy number, code name, or acronym returns the exact matching record or a broader conceptual match. For RAG pipelines, fusion quality directly influences whether the generation step has the right evidence available.
Once a system uses multiple retrieval methods, the next question is not just which method is better. The more useful question is how their signals should be combined without letting one method dominate for accidental numerical reasons.
Why Scores From Different Methods Cannot Be Added Directly
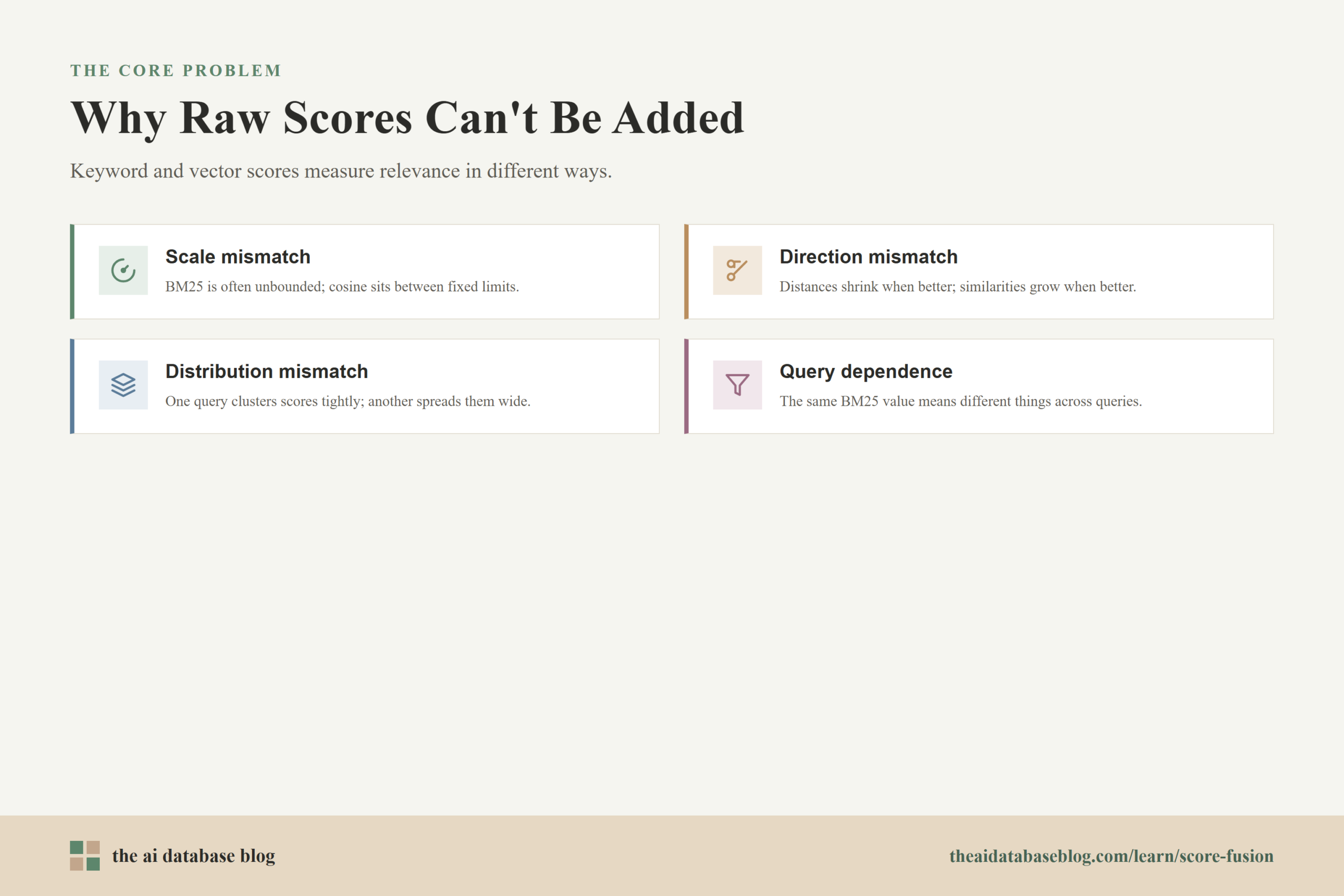
Raw scores from different retrieval methods are usually not interchangeable because they do not measure relevance in the same way. A BM25 score, a cosine similarity score, a vector distance, and a neural reranker score can all be used to rank results, but the numbers are produced by different formulas and often have different ranges. A higher number in one method does not mean the same thing as the same number in another method.
BM25-style keyword scoring is based on term frequency, inverse document frequency, document length normalization, and the distribution of words in the collection. Its scores are often unbounded and query-dependent. A BM25 score of 8 might be strong for one query but ordinary for another, depending on how rare the query terms are and how documents are distributed across the index.
Vector similarity scores behave differently. Depending on the similarity metric, vector search may return cosine similarity, dot product, or a distance value. Cosine similarity is often bounded, while dot product may not be. Distances may be smaller when results are better, while similarity scores are usually larger when results are better. Even before fusion begins, a system may need to convert distance into a relevance-like score so that the direction of comparison is clear.
This creates a scale mismatch. If a keyword result has a BM25 score of 14 and a vector result has a cosine similarity of 0.82, adding those values directly would cause the keyword score to dominate even if the vector result is more semantically relevant. The problem is not that BM25 is necessarily better or worse. The problem is that the raw numbers are not calibrated to the same meaning.
There is also a distribution mismatch. For one query, vector scores may be tightly clustered, with the top ten results all sitting near each other. For another query, the best vector result may stand far above the rest. Keyword scores can show similar variation when a query contains rare terms, common terms, or a mixture of both. A good fusion method needs to account for these patterns instead of treating every raw score gap as equally meaningful.
The practical lesson is simple: direct score addition is usually unsafe unless the scores have already been calibrated onto a shared scale. Most hybrid retrieval systems therefore use either rank-based fusion or normalized score fusion to make the signals easier to combine.
What Reciprocal Rank Fusion Does
Reciprocal rank fusion, often shortened to RRF, combines result lists by looking at where each document appears rather than what raw score it received. Each retrieval method produces a ranked list. A document receives points based on its rank in each list, and those points are added together. Documents that appear near the top of multiple lists usually rise in the final ranking.
The common RRF idea is that a result ranked first should receive more credit than a result ranked tenth, but the method should not need to know whether the first result had a BM25 score of 12, a cosine similarity of 0.79, or any other raw value. A typical formula gives each document a contribution based on one divided by a constant plus the rank. The constant controls how steeply the score falls as rank gets lower.
For example, imagine keyword search ranks document A first and vector search ranks it fifth. RRF gives document A credit from both lists. If document B appears first in vector search but does not appear in the keyword list, it still receives credit, but it may not outrank a document that performs well across both methods. This makes RRF especially useful when the system wants consensus across retrievers.
The main strength of RRF is robustness. Because it ignores raw score magnitudes, it avoids the scale mismatch between keyword and vector scores. It can combine BM25, dense vector search, sparse vector search, or other rankers without requiring their scores to be directly comparable. This is why RRF is often a strong default for hybrid retrieval, especially when the retrieval system is new or score calibration has not been studied carefully.
RRF also has limits. Since it only sees rank position, it discards information about how confident a method was. If the top vector result is far better than the second result, RRF treats that gap mostly as a rank difference rather than a large relevance difference. If the top ten vector results are nearly tied, RRF still treats first place as meaningfully above tenth place. In some cases, this loss of score magnitude can hide useful evidence.
RRF is therefore best understood as a stable, low-assumption fusion method. It is not trying to interpret the raw scores. It is asking a simpler question: which documents are ranked highly by one or more retrieval methods?
What Relative Score Fusion Does
Relative score fusion takes a different approach. Instead of ignoring raw scores, it first normalizes scores from each retrieval method so they can be blended on a shared scale. In a typical setup, each method’s scores are scaled between 0 and 1 for the current query, then combined with a weight that controls the balance between the methods.
For example, the top keyword result may be normalized to 1, the weakest keyword result in the candidate set may be normalized to 0, and the remaining keyword results may be placed between them based on their relative scores. The same process is applied to vector results. Once each method has a normalized score, the system can compute a blended score, such as a weighted combination of keyword relevance and vector relevance.
This approach preserves more information than pure rank fusion. If vector search finds one document that is clearly more semantically similar than the rest, relative score fusion can allow that strong gap to matter. If BM25 has a sharp score drop after the first few exact matches, relative score fusion can also preserve that signal. This can produce better rankings when score distributions are meaningful and reasonably stable.
The tradeoff is that normalization is still not magic calibration. A normalized score of 0.9 from keyword search and a normalized score of 0.9 from vector search may be easier to combine than the raw scores, but they still come from different retrieval behaviors. Min-max normalization is also sensitive to the candidate set. If the top and bottom scores change, the normalized values for the middle results can change too.
Relative score fusion is most useful when the shape of the scores carries real relevance information. It can reward a method not only for ranking a result highly, but for ranking it highly by a large margin. That makes it attractive for hybrid search systems where both lexical and semantic scores are useful, and where evaluation shows that score magnitude improves the final ordering.
Now that the two methods are clear, the practical choice becomes easier to reason about. RRF protects you from incompatible score scales by using ranks. Relative score fusion tries to use normalized score strength when that strength is meaningful enough to trust.
RRF vs Relative Score Fusion
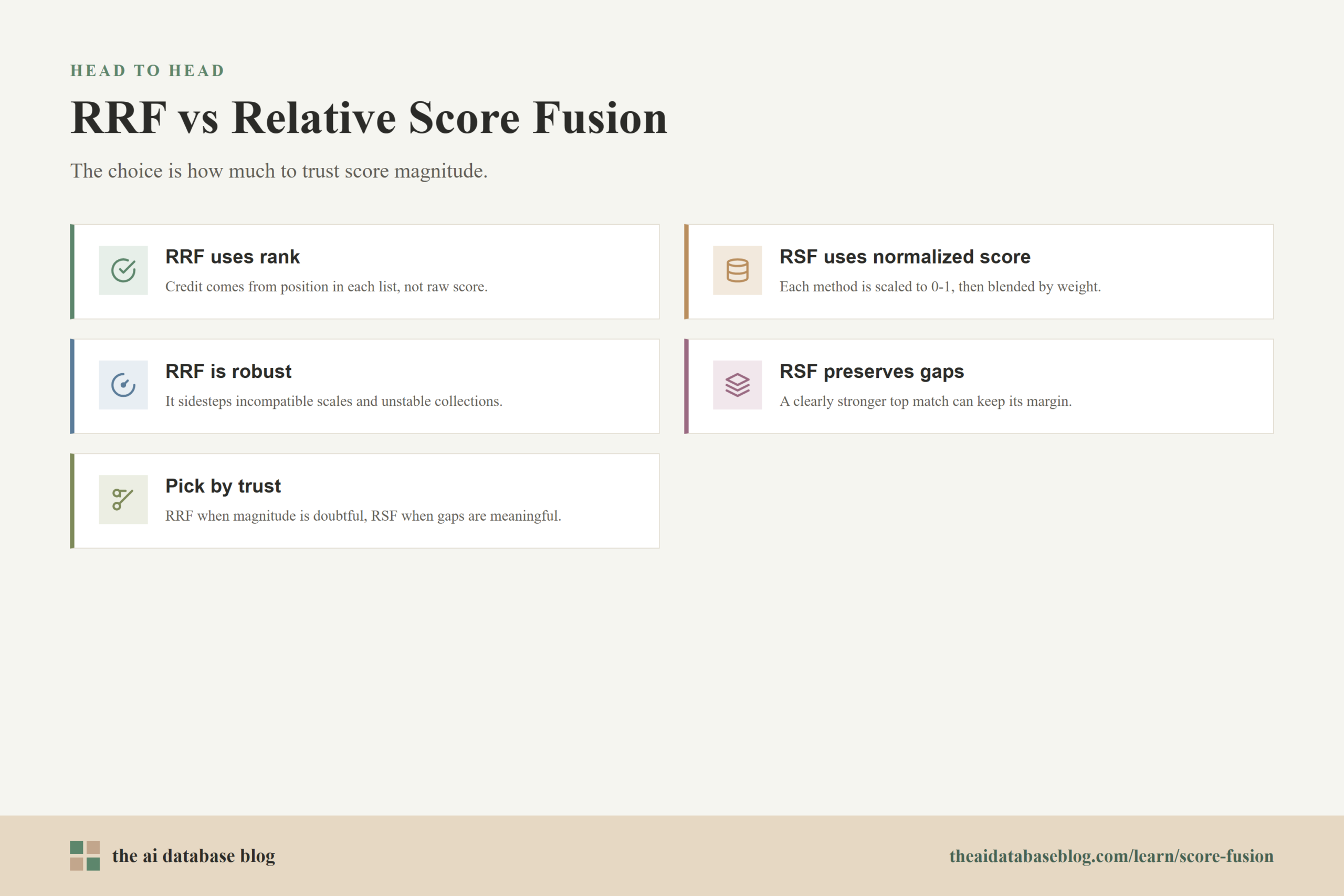
The difference between RRF and relative score fusion is not just mathematical. It reflects a deeper choice about how much trust the system should place in raw or normalized score magnitudes. RRF assumes that positions in ranked lists are safer than scores. Relative score fusion assumes that, after normalization, score gaps can carry useful relevance information.
RRF is often a good fit when the retrieval methods have very different scoring behavior, when the collection is changing quickly, or when there is not enough evaluation data to tune score blending carefully. It is also useful when combining multiple rankers with very different score types. The method is easy to explain: a document earns credit for appearing high in each result list.
Relative score fusion is often a good fit when the retrieval methods produce score distributions that are informative for the use case. If the system can observe that a large vector similarity gap reliably predicts better results, or that high BM25 confidence should strongly favor exact matches, normalized score blending can capture information that RRF throws away. This can matter in domains where the difference between a barely relevant result and a highly relevant result is visible in the score distribution.
The two methods can behave differently on the same query. Suppose vector search returns three documents with nearly identical similarity scores, while BM25 returns one document with a much stronger exact-term match than the rest. RRF may still give strong credit to the top vector positions because they are ranked highly. Relative score fusion may give more weight to the keyword result if the normalized BM25 gap is large.
The reverse can also happen. Suppose BM25 ranks several documents highly because they repeat the query terms, but vector search shows one document is a much better semantic match. RRF will reward the rank positions from both lists, while relative score fusion may allow the strong vector score gap to push the semantic match higher. Whether that is good depends on the query and the application.
A useful rule of thumb is that RRF is safer when you do not trust score magnitude, while relative score fusion is more expressive when you do. In production retrieval systems, the best answer is rarely theoretical. It is usually found by testing both approaches against real queries, real documents, and relevance judgments that match the application’s goals.
Tuning the Balance Between Keyword and Vector Signals
Fusion is not only about choosing RRF or relative score fusion. Most hybrid systems also need a way to tune the balance between keyword and vector search. This balance determines whether exact lexical matches, semantic matches, or a mixture of both should dominate the final ranking. In many systems, the balance is represented as a weight, often with one side favoring keyword search and the other side favoring vector search.
A balanced setting can be a reasonable starting point, but it should not be treated as universally correct. Different query types need different retrieval behavior. A query with an error code, legal clause number, SKU, person name, or database identifier often benefits from stronger keyword influence. A query written in natural language, such as “how do I handle duplicate customer records,” may benefit from stronger vector influence because the best document may use different wording.
Good tuning starts with query categories. Instead of testing only average retrieval quality, separate queries by intent. Exact lookup queries, troubleshooting queries, conceptual questions, navigational queries, and long natural-language questions may each prefer a different balance. This helps reveal whether one setting is genuinely good or merely averaging over different failure modes.
Evaluation should use the same downstream goal the retrieval system is meant to support. For search, that may mean measuring whether the best result appears in the top few positions. For RAG, it may mean measuring whether the retrieved context contains enough evidence for the model to answer correctly. A fusion setting that looks good for top-ten recall may still be poor if the most useful passage appears too low for the generation step to use.
It is also important to inspect failures manually. If keyword-heavy fusion returns documents that repeat the query but miss the intent, the balance may be too lexical or the keyword index may need better field weighting. If vector-heavy fusion returns conceptually related documents that miss exact constraints, the balance may be too semantic or metadata filtering may need to happen before fusion. These errors teach different lessons.
For relative score fusion, tuning the balance also means watching score normalization behavior. If normalized keyword scores are frequently flat, they may not contribute much distinction. If vector scores are tightly clustered, the normalized values may exaggerate small differences. If one method regularly produces one extreme outlier, it may dominate the blended score unless the weight is adjusted.
For RRF, tuning may involve the rank constant, candidate depth, and per-method weighting if the system supports it. Candidate depth matters because a document cannot receive fusion credit from a method if it was never retrieved by that method. If each retriever returns too few candidates, fusion may miss useful documents. If each retriever returns too many weak candidates, fusion may add noise and increase reranking cost.
The goal is not to find a perfect universal weight. The goal is to find a setting that performs well for the application’s most important queries and fails in understandable ways. For mature systems, adaptive weighting by query type can be more effective than one global setting, but a well-evaluated global setting is usually the right place to begin.
Practical Examples of Fusion Behavior
Examples make the tradeoff easier to see because score fusion can otherwise feel abstract. Imagine a query for “OAuth token expiration error 401.” Keyword search may strongly favor documents containing “OAuth,” “token,” “expiration,” and “401.” Vector search may favor documents about authentication failures even if some exact terms are missing. A keyword-leaning blend may be best because the error code and technical terms are important constraints.
Now imagine a query like “why does the system forget earlier conversation details?” A vector search may find documents about context windows, memory, prompt state, and retrieval grounding even if the exact phrase “forget earlier conversation details” does not appear. Keyword search may still help, but pure exact matching could miss the best conceptual material. A vector-leaning blend may be more useful here.
A third case is mixed intent. A query such as “data retention policy for archived invoices” contains exact terms that matter, but it also has a broader concept. Keyword search may identify documents with “archived invoices,” while vector search may surface policy documents about retention periods and compliance rules. Hybrid fusion can outperform either method alone if it keeps both signals in play.
These examples show why the fusion method and balance should be evaluated together. RRF might work well when the system mainly needs agreement between retrievers. Relative score fusion might work better when a sharp score gap in one retriever should influence the final order. In both cases, the retrieval design should be judged by whether it returns useful evidence, not by whether one scoring formula looks elegant.
Common Pitfalls to Avoid
The most common mistake is treating hybrid search as a guaranteed upgrade. Combining keyword and vector retrieval can improve relevance, but it can also combine the mistakes of both methods. If keyword search retrieves noisy matches and vector search retrieves broad semantic neighbors, fusion may produce a mixed list that looks plausible but does not answer the user’s query well.
Another mistake is tuning only by intuition. A developer may assume vector search should receive most of the weight because the application uses AI, or assume keyword search should dominate because exact terms feel safer. Both assumptions can be wrong depending on the collection, query mix, chunking strategy, metadata filters, and downstream task. Retrieval should be tuned with examples and measured against expected outcomes.
Candidate generation is another source of errors. Fusion can only combine what each method retrieves. If the vector index returns too few candidates, relevant semantic matches may never reach fusion. If the keyword search is poorly configured, exact matches may be absent or diluted. Before blaming the fusion algorithm, inspect the separate result lists.
Chunking can also affect fusion quality. If documents are split into chunks that are too small, keyword search may miss context and vector search may lose meaning. If chunks are too large, keyword matches may be buried inside broad passages and vector similarity may become less precise. Fusion is downstream from these choices, so a poor chunking strategy can make any fusion method look weaker than it really is.
Finally, avoid assuming normalized scores are universally comparable across queries. Relative score fusion usually normalizes within a query’s candidate set, which helps with local blending but does not make scores globally meaningful. A hybrid score of 0.85 for one query does not necessarily mean the same level of relevance as 0.85 for another query.
These pitfalls point toward a practical workflow: inspect individual retrievers, choose a fusion method, tune the balance, evaluate with real queries, and then decide whether reranking or adaptive weighting is needed.
How to Choose a Fusion Strategy
The best fusion strategy depends on how much you know about your retrieval signals and how much tuning your application can support. If you are building an early hybrid search system, RRF is often the safer first choice because it avoids direct score calibration. It gives you a stable baseline and makes it easier to inspect whether keyword and vector retrieval are both contributing useful candidates.
If you have evaluation data and the score distributions are informative, relative score fusion may provide better control. It can preserve meaningful differences between strong and weak matches inside each retrieval method. This is especially useful when the top result from one method is not merely first, but clearly better than the rest.
For RAG systems, the choice should also consider whether a later reranker is used. If a cross-encoder or other reranking model reorders the fused candidates, the fusion stage may mainly need to provide a diverse, high-recall candidate pool. In that case, RRF can be attractive because it is robust and simple. If there is no reranker, the final fused order matters more, and relative score fusion may be worth tuning carefully.
For search interfaces, explainability may matter as well. RRF is easy to explain in terms of rank agreement, while relative score fusion is easier to connect to weighted relevance signals. Neither is automatically more transparent. The more important requirement is that the system can expose enough detail for developers to understand why a result was ranked highly.
A practical decision path is to start with separate keyword and vector baselines, add RRF as a robust hybrid baseline, test relative score fusion with a few balance settings, and compare all of them against real relevance judgments. If relative score fusion wins consistently, use it. If the results are similar or unstable, prefer the simpler method and invest effort in better chunking, filtering, candidate generation, or reranking.
FAQs
1. What is score fusion in hybrid search?
Score fusion is the process of combining results from multiple retrieval methods into one ranked list. In AI databases, it often means merging keyword search results with vector search results so the system can use both exact term matching and semantic similarity.
2. Why can BM25 and vector scores not be added directly?
BM25 and vector scores are produced by different formulas and usually have different scales, ranges, and meanings. A BM25 score of 10 and a vector similarity of 0.8 are not two measurements of the same thing. Adding them directly can cause one method to dominate for numerical reasons rather than relevance reasons.
3. Is reciprocal rank fusion the same as ranked fusion?
In many hybrid search discussions, ranked fusion refers to a reciprocal rank fusion style of combining results by rank position instead of raw score. The exact implementation can vary, but the core idea is the same: documents receive credit based on where they appear in each ranked list.
4. When is relative score fusion better than RRF?
Relative score fusion can be better when normalized score gaps carry useful relevance information. If one retriever can show that its top result is much stronger than the rest, score blending can preserve that signal. RRF would mostly reduce that information to rank position.
5. How should I tune the keyword and vector balance?
Start with a balanced setting, then test several weights against real queries. Separate exact lookup queries from conceptual queries because they often need different behavior. Use relevance judgments, top-k success, RAG answer quality, or another application-specific measure rather than relying only on intuition.
6. Does hybrid fusion remove the need for reranking?
Not always. Fusion helps create a better combined candidate list, but reranking can still improve the final order by using a more expensive relevance model on a smaller set of candidates. Many retrieval systems use fusion for recall and reranking for precision.
Takeaway
Score fusion helps AI databases combine keyword and vector retrieval without pretending their raw scores mean the same thing. RRF is a robust rank-based method that works well when score scales are incompatible or difficult to trust, while relative score fusion uses normalized scores to preserve useful confidence gaps when those gaps are meaningful. This guidance is most useful for teams building hybrid search, RAG retrieval, support search, or knowledge discovery systems where exact terms and semantic intent both matter; a practical use case is tuning a documentation chatbot so it can retrieve both precise error-code matches and conceptually relevant troubleshooting guidance.