Re-ranking with cross-encoders is a practical way to improve the precision of AI database search without asking the database to do all of the semantic judgment in one step. A typical system first uses a fast retriever, often a bi-encoder with vector search or hybrid search, to collect a broad set of likely matches. It then sends only the top candidates to a cross-encoder, which compares the query and each candidate together and reorders them by relevance. This two-stage pattern works because bi-encoders are strong at recall, while cross-encoders are stronger at precision, as long as the candidate set is small enough to fit the application’s latency budget.
This guide explains how cross-encoder re-ranking fits into AI database retrieval, why two-stage retrieval is common in retrieval-augmented generation and semantic search systems, how to think about bi-encoder recall versus cross-encoder precision, and how to choose lightweight re-rankers that improve quality without making the user wait too long. By the end, you should be able to reason about when re-ranking is worth adding, where to place it in the retrieval pipeline, and which practical controls matter most for performance.
What Cross-Encoder Re-ranking Does
Cross-encoder re-ranking is a second-pass scoring step that looks more closely at the relationship between a user query and a small group of retrieved documents. Instead of relying only on precomputed document vectors, the cross-encoder reads the query and candidate text together as a pair. That joint reading lets the model pay attention to exact phrasing, negation, entity relationships, and context that may be blurred when a document is compressed into a single embedding.
In an AI database system, the first retrieval step usually returns more documents than the application will actually show to a user or send to a language model. For example, a vector search might retrieve the top 100 chunks, but the final answer may only need the best 5 to 10. Re-ranking helps decide which of those candidates deserve the limited final slots.
The re-ranker does not replace the AI database. It sits on top of the database as a relevance refinement layer. The database remains responsible for storage, filtering, indexing, candidate retrieval, and often hybrid search. The cross-encoder is responsible for making a more careful judgment about a much smaller set of candidates.
Once that basic role is clear, the next question is why the process is usually split into two stages instead of using the most precise model from the beginning. The answer is scale: precision is valuable, but it becomes useful in production only when it is applied after the system has narrowed the search space.
Why Two-Stage Retrieval Is the Common Pattern
Two-stage retrieval separates the problem of finding possible matches from the problem of choosing the best matches. The first stage is optimized for speed and coverage across a large corpus. The second stage is optimized for deeper relevance judgment on a much smaller candidate set. This division is common because AI database workloads often need both broad recall and high precision, and no single retrieval step is usually ideal for both.
In the first stage, the system may use dense vector search, keyword search, sparse retrieval, metadata filters, or a hybrid combination. The goal is to avoid missing useful candidates. If the correct document never appears in the first-stage candidate set, the re-ranker cannot recover it later. That makes recall the first priority.
In the second stage, the system reorders the retrieved candidates using a cross-encoder or another re-ranking model. The goal is not to search the whole database again. The goal is to make the final order better, especially near the top of the results, where users and generation models are most sensitive to mistakes.
A Simple Two-Stage Retrieval Flow
- The user asks a question or submits a search query.
- The AI database applies metadata filters if needed, such as product category, tenant, date range, document type, or access permissions.
- A first-stage retriever returns a candidate set, such as the top 50, 100, or 200 chunks.
- The cross-encoder scores each query-candidate pair in that smaller set.
- The application keeps the highest-scoring results for display, answer generation, or downstream reasoning.
This pattern is especially useful for retrieval-augmented generation because the downstream language model has a limited context budget. Sending too many chunks can dilute the answer with loosely related information. Sending too few can omit necessary evidence. Re-ranking helps select the most useful evidence before it reaches the generation step.
With the two-stage pattern in place, the most important design choice becomes how much responsibility belongs to the fast retriever and how much belongs to the re-ranker. That tradeoff is easiest to understand by comparing bi-encoder recall with cross-encoder precision.

Bi-Encoder Recall vs Cross-Encoder Precision
A bi-encoder turns the query and each document into separate embeddings. Because document embeddings can be computed ahead of time and indexed in an AI database, query-time search can be fast even across millions or billions of vectors. This makes bi-encoders well suited for first-stage retrieval, where the system needs to scan a large search space and quickly find plausible candidates.
The tradeoff is that each document vector is a compressed representation created before the user’s exact query is known. A single embedding may capture the general meaning of a chunk, but it may not preserve every detail that matters for a specific query. This can be a problem when documents are similar, queries are nuanced, or the application needs exact alignment between the question and the returned evidence.
A cross-encoder works differently. It receives the query and a candidate document together and produces a relevance score for that pair. Because the model sees both texts at the same time, it can judge whether the candidate actually answers the query rather than merely being close in embedding space. This usually improves top-result precision, but it is more expensive because the model must run separately for each query-candidate pair.
What the Bi-Encoder Should Optimize For
The first-stage retriever should be tuned to retrieve enough potentially relevant material for the re-ranker to work with. In practice, that often means favoring recall over strict precision. A slightly noisy top 100 can be acceptable if it contains the best evidence. A clean top 10 is less useful if it misses the answer entirely.
Good first-stage retrieval often depends on chunking, metadata filtering, hybrid search, and query handling as much as the embedding model itself. A strong re-ranker cannot fully compensate for poor data modeling, overly large chunks, missing metadata, or a retriever that consistently fails to bring the right candidates into the candidate pool.
What the Cross-Encoder Should Optimize For
The cross-encoder should be judged by how much it improves the final ranked list. In many applications, the key question is not whether the average candidate score improves, but whether the top few results become more useful. For RAG systems, that may mean better answer grounding, fewer irrelevant chunks in the prompt, and less chance that the generator follows a misleading source.
Cross-encoders are especially helpful when many candidates look similar to a vector retriever. Examples include support articles with overlapping wording, legal or policy documents with repeated clauses, product documentation with small version differences, and enterprise knowledge bases where many chunks share the same terminology.
The benefit of precision has a cost, so the next practical question is not simply whether cross-encoders are better. It is whether they improve the final experience enough to justify the extra time they add to each query.
How to Think About the Latency Budget
A latency budget is the amount of time the application can spend on retrieval before the user experience starts to suffer. Re-ranking consumes part of that budget because the system must score multiple query-document pairs after the first-stage retrieval step. The impact depends on the re-ranker size, candidate count, text length, hardware, batching strategy, and whether the system is calling a local model or a remote service.
The most important control is the number of candidates sent to the re-ranker. If a cross-encoder takes meaningful time per pair, re-ranking 200 candidates will feel very different from re-ranking 20 candidates. The model may be the same, but the total workload changes directly with the candidate count.
Latency also depends on document length. Long chunks require more tokens, and more tokens usually mean slower scoring. This is one reason chunking strategy matters. Chunks should be large enough to carry useful context, but not so large that every re-ranking call becomes expensive or the model’s attention is diluted across unnecessary text.
Set a Budget Before Choosing a Re-ranker
Teams often get into trouble when they choose a re-ranker based only on offline quality scores. A model that performs well in evaluation may still be too slow for an interactive product. Before selecting a model, define a practical budget for the retrieval portion of the request. For example, a search interface may need very fast responses, while an internal research assistant may tolerate a little more delay if the results are much better.
Once the budget is clear, work backward. Decide how many candidates can be retrieved, how many can be re-ranked, how long each candidate can be, and whether batching is available. This turns re-ranking from an open-ended quality feature into an engineering tradeoff that can be measured.
Use Candidate Windows Deliberately
A common pattern is to retrieve a wider first-stage set, then re-rank only a smaller window. For example, the database might retrieve 100 candidates, apply basic filtering or diversity logic, and send 20 to 50 candidates to the cross-encoder. The final answer may use only the top 5 to 10 results after re-ranking.
The right numbers depend on the corpus and the use case. If relevant information is hard to find, the system may need a larger candidate set. If the corpus is small and clean, a smaller set may work well. The key is to evaluate whether the correct evidence appears in the candidate window before blaming the re-ranker for poor final results.
After latency is under control, the next lever is model choice. Many retrieval systems do not need the largest or most expensive re-ranker to see a meaningful improvement. Lightweight re-rankers can often deliver much of the benefit at a lower cost.
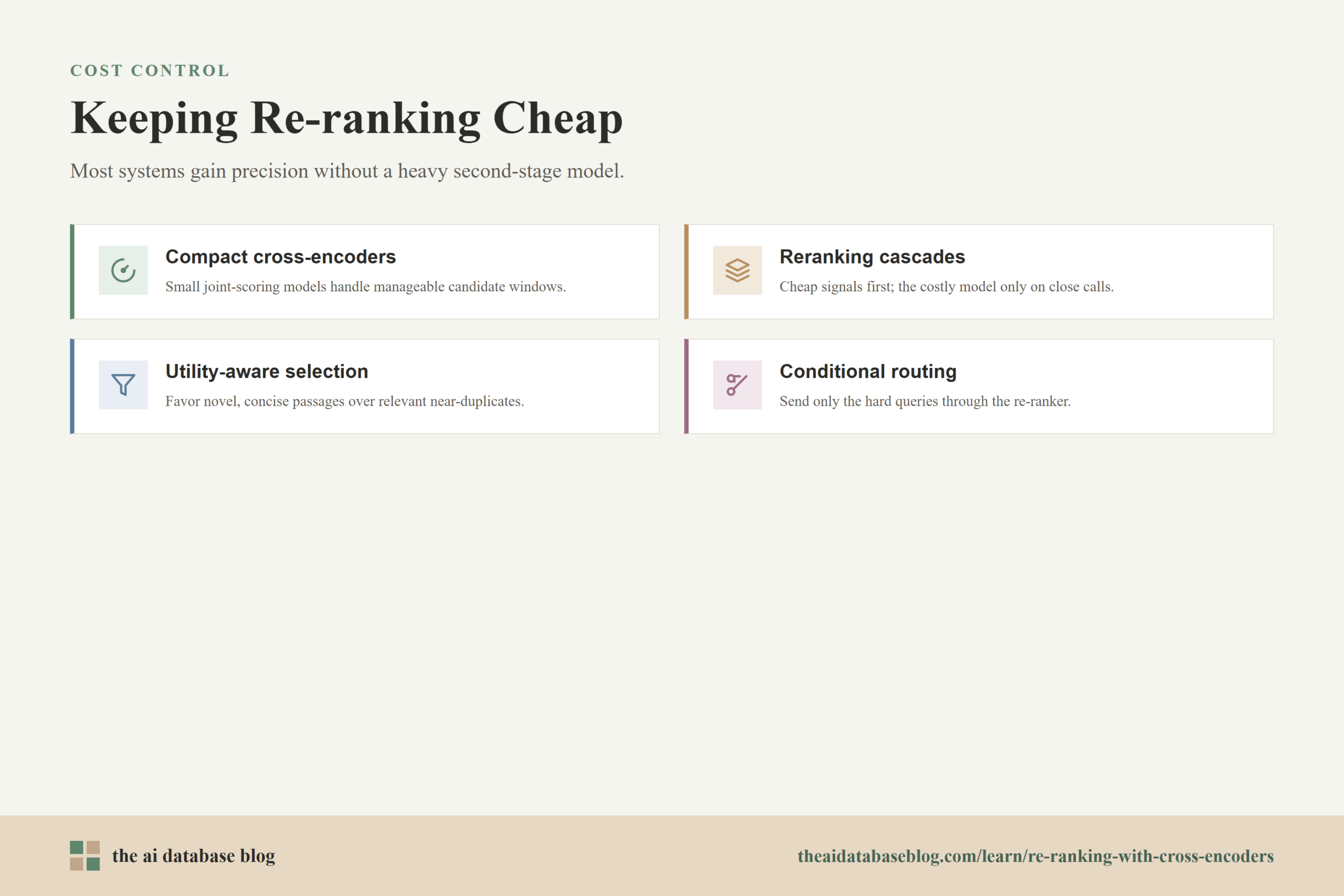
Lightweight Re-rankers That Improve Quality Cheaply
Lightweight re-rankers are smaller or more efficient models designed to improve relevance without adding heavy latency or infrastructure cost. They are useful because many production retrieval problems do not require a very large model to separate good candidates from weak ones. If the first-stage retriever already produces a reasonable candidate set, a smaller re-ranker can often make the top results cleaner.
There are several ways to keep re-ranking cheap. One is to use compact cross-encoders that are trained for relevance scoring. Another is to re-rank fewer candidates. A third is to use simpler learned ranking models, utility-based ranking, or cascade approaches where the system applies the expensive model only when cheaper signals are not enough.
Compact Cross-Encoders
Compact cross-encoders are often the simplest starting point. They still score query-document pairs jointly, but they use a smaller architecture than larger reranking models. This makes them attractive for interactive search, customer support assistants, documentation search, and other workloads where top-result precision matters but response time is still important.
A compact cross-encoder is usually a good fit when the application has a manageable candidate window, short-to-medium chunks, and a clear relevance target. It may be less suitable when queries require deep multi-step reasoning, very long context, or domain-specific judgment that a small general model does not handle well.
Reranking Cascades
A reranking cascade uses more than one scoring layer. The first layer might use cheap signals such as keyword overlap, embedding similarity, metadata matches, freshness, source authority, or a compact re-ranker. A more expensive cross-encoder is then applied only to the most competitive candidates or only to queries where the first layer is uncertain.
This approach is useful when traffic is high or latency requirements are strict. Instead of paying the full re-ranking cost for every candidate on every query, the system spends more compute only where it is likely to change the final result. Cascades can be especially effective when many queries are easy, repetitive, or already well served by the first-stage retriever.
Utility-Aware Re-ranking
For RAG systems, relevance is not the only useful signal. A candidate may be relevant but redundant, too long, too vague, or less useful than a shorter passage that directly supports the answer. Utility-aware re-ranking considers how helpful each candidate is for the final generation step, not just whether it is semantically similar to the query.
Practical utility signals can include relevance, novelty, brevity, source quality, recency, and whether a passage adds information not already covered by higher-ranked candidates. This helps the system avoid filling the prompt with several near-duplicate chunks when one clear passage and several complementary passages would produce a better answer.
Choosing a lightweight approach is only useful if the team can tell whether it actually improved retrieval. That means re-ranking should be evaluated with metrics and examples that reflect the final application, not just with model scores in isolation.
How to Evaluate Re-ranking Quality
Re-ranking should be evaluated at the point where it affects the user or the generation model. In search, that usually means the quality of the top results. In RAG, it means whether the selected context supports accurate, grounded answers. The evaluation should compare the system before and after re-ranking so the team can see whether the extra latency produces a real improvement.
Useful retrieval metrics include precision at a small cutoff, recall in the candidate set, mean reciprocal rank, normalized discounted cumulative gain, and answer-level faithfulness or groundedness for RAG. Human review is also valuable, especially for ambiguous queries where several results may be partially correct.
It is important to separate first-stage failure from second-stage failure. If the relevant document is missing from the candidate set, the re-ranker never had a chance. If the relevant document is present but ranked too low after re-ranking, then the re-ranker, chunking, or scoring setup may need adjustment.
Evaluate by Query Type
Aggregate metrics can hide important differences. Re-ranking may help complex, ambiguous, or highly specific queries while adding little value to simple navigational queries. Segmenting evaluation by query type makes it easier to decide when re-ranking should always run, when it should run conditionally, and when the first-stage retriever is enough.
For example, a product documentation assistant may not need re-ranking for exact error-code searches, but may benefit from it for natural-language troubleshooting questions. A policy search tool may need re-ranking more often because many documents share similar wording and the final answer depends on small distinctions.
Once evaluation shows where re-ranking helps, the system can be designed more confidently. The final architecture should make re-ranking a controlled part of the retrieval pipeline rather than an expensive step added to every query by default.
Practical Design Guidelines
A good cross-encoder re-ranking setup starts with a strong first-stage retrieval system. The better the candidate set, the less work the re-ranker has to do. That means investing in chunking, metadata design, filtering, hybrid retrieval, and query preprocessing before assuming that a larger second-stage model will solve relevance problems.
Start with a modest candidate window and a lightweight re-ranker. Measure both quality and latency. If quality improves and latency stays within budget, the system may not need a heavier model. If quality does not improve, inspect examples before changing models. The issue may be missing candidates, poor chunk boundaries, weak metadata filters, or a mismatch between the model’s training domain and the application’s content.
Use conditional re-ranking when query patterns vary. Some queries need deep semantic judgment; others are straightforward keyword or metadata lookups. Routing only the harder cases through a re-ranker can preserve quality while reducing average latency.
For RAG, evaluate the final context, not only the ranked list. The best re-ranking setup is the one that gives the language model the clearest, most relevant, least redundant evidence for the answer. Sometimes that means selecting a diverse set of passages rather than the top passages that all repeat the same point.
These guidelines make re-ranking more manageable because they turn it into a set of explicit choices: how many candidates to retrieve, how many to re-rank, how large the model should be, and when the extra step is worth using. The answers will vary by application, but the underlying tradeoff stays the same.
Common Mistakes to Avoid
The most common mistake is treating a cross-encoder as a cure for weak retrieval. Re-ranking can improve ordering, but it cannot rank a document that was never retrieved. If the correct answer is consistently absent from the candidate set, the first-stage retriever needs attention before the re-ranker does.
Another mistake is re-ranking too many candidates. Larger candidate windows can improve recall, but they also increase latency. Past a certain point, the added candidates may contribute little quality while making the system slower and more expensive. The candidate count should be tuned with evaluation data, not chosen by guesswork.
Teams also sometimes evaluate only offline ranking metrics and ignore product latency. A re-ranker that improves a benchmark but makes the application feel slow may not be the right production choice. Quality should be measured alongside response time, throughput, infrastructure cost, and user tolerance for delay.
Finally, it is easy to overlook redundancy. A re-ranker may place several similar chunks at the top because each one is individually relevant. For answer generation, that can waste context space. Adding diversity or utility-aware selection after relevance scoring can produce a better final prompt.
FAQs
1. What is a cross-encoder in retrieval?
A cross-encoder is a model that scores a query and a candidate document together as a pair. Unlike a bi-encoder, it does not create reusable document embeddings for large-scale search. Its strength is precise relevance scoring after a smaller candidate set has already been retrieved.
2. Why not use a cross-encoder for the whole database?
A cross-encoder must run a separate scoring pass for each query-document pair, so using it across an entire database would usually be too slow and expensive. It is better used after vector search, keyword search, or hybrid search has narrowed the corpus to a small candidate set.
3. How many candidates should be sent to a re-ranker?
There is no universal number, but many systems start by testing a candidate window such as 20, 50, or 100 results. The right choice depends on corpus size, first-stage recall, chunk length, model speed, and the application’s latency budget. The goal is to send enough candidates to include the right evidence without wasting time on weak matches.
4. Does re-ranking always improve RAG answers?
Re-ranking often improves RAG answers when the first-stage retriever returns relevant but poorly ordered candidates. It may add little value if the corpus is small, the first-stage results are already precise, or the relevant evidence is missing from the candidate set. The only reliable answer comes from evaluating the pipeline on realistic queries.
5. Are lightweight re-rankers good enough for production?
Lightweight re-rankers can be good enough when the first-stage retriever already produces a reasonable candidate set and the application mainly needs better ordering near the top. They are especially useful when latency and cost matter. Larger models may still be useful for more complex domains, longer documents, or nuanced reasoning tasks.
6. How does re-ranking work with hybrid search?
Hybrid search can combine dense vector similarity with keyword or sparse retrieval signals to produce a stronger candidate set. A cross-encoder can then re-rank those candidates using a deeper query-document comparison. This is often a strong pattern because hybrid search improves recall and candidate diversity, while the re-ranker improves final precision.
Takeaway
Cross-encoder re-ranking improves AI database retrieval by adding a precise second-stage relevance check after a fast first-stage retriever has gathered likely candidates. The approach is most useful for teams building semantic search, hybrid search, and RAG systems where the top few results matter and where similar documents can confuse embedding-only retrieval. The practical lesson is to use bi-encoders and AI database indexing for recall, use cross-encoders for precision, respect the latency budget, and start with lightweight or conditional re-ranking before reaching for heavier models. For use cases such as support search, documentation assistants, policy retrieval, and enterprise knowledge tools, this pattern can make retrieved evidence cleaner, more focused, and more useful for both users and generation models.
Watch this video to learn more