Scaling to billions of vectors requires more than choosing a fast nearest neighbor index. At that size, the main challenge is building a system that can control memory use, limit disk I/O, route queries across shards, preserve recall, and keep indexes fresh as data changes. The strategies that usually hold up are sharding, disk-based indexes, quantization, careful reranking, and disciplined operational planning around rebuilds, monitoring, filtering, and capacity growth.
This guide explains what changes when a vector database grows from millions to billions of embeddings. It covers why large indexes become difficult to operate, how sharding changes query execution, when disk-based indexes make sense, how quantization reduces cost, and what teams need to monitor once very large vector indexes are running in production.
Why Billion-Scale Vector Search Is Different
A billion-vector system is not just a larger version of a million-vector system. The raw storage alone can become enormous before the index, metadata, replicas, caches, and temporary build files are counted. For example, one billion 1,536-dimensional float32 vectors require roughly 6 TB for the raw vectors alone because each vector stores 1,536 numbers at 4 bytes per number. A graph index, partition index, metadata payload, or replication layer can add significantly more.
This is why billion-scale vector search usually becomes an infrastructure problem as much as a retrieval problem. The system must decide where vectors live, which parts of the index stay in memory, which parts can sit on SSDs, how many machines are involved, and how queries are merged across partitions. Even if the search algorithm is approximate, the surrounding database still has to ingest data, enforce filters, return stable results, recover from failures, and maintain predictable latency.
The most important shift is that memory stops being the default answer. In smaller systems, it is common to keep an HNSW-style index and the vectors in RAM because this gives strong latency and recall. At billion scale, that may be too expensive or physically impractical. The architecture has to combine memory, disk, compression, and distribution in a way that matches the application’s latency, recall, throughput, and freshness requirements.
Once the raw size problem is clear, the next question is how to divide the work. Sharding is usually the first architectural tool teams reach for because it spreads storage and query load across multiple machines, but it introduces its own tradeoffs.
Sharding Large Vector Indexes
Sharding splits a large vector collection into smaller pieces that can be stored, indexed, and searched separately. A shard might contain a range of document IDs, a subset of tenants, a partition of embedding space, or a time-based slice of the corpus. At billion scale, sharding is often necessary because one machine cannot cheaply hold the full index, or because one index cannot handle the required query and ingestion load.
The simplest approach is document-based or tenant-based sharding. Each shard owns a portion of the data, and a query is sent to the relevant shard or set of shards. This is operationally understandable because it maps well to access control, ownership, and data lifecycle rules. It works especially well when queries naturally target a tenant, account, region, or content category.
The harder case is global semantic search, where a query may need to search across the whole corpus. In that situation, the system often sends the query to many shards, asks each shard for its top candidates, then merges and reranks the combined results. This fan-out pattern can work, but it raises tail latency and creates pressure on network, coordination, and query aggregation. If one shard is slow, the whole query can become slow.
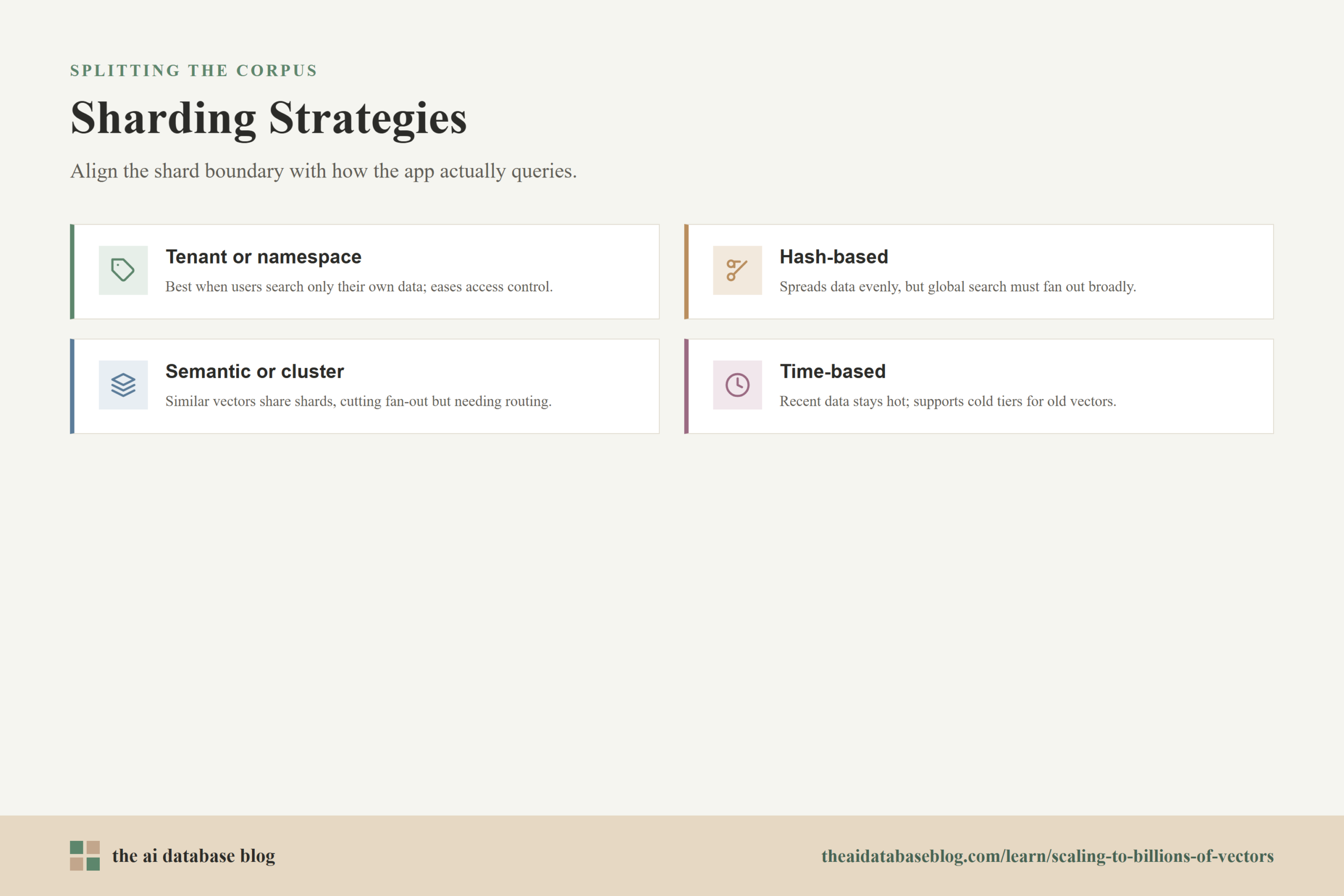
Common Sharding Strategies
There is no single best sharding pattern for every billion-vector system. The right choice depends on whether the workload is tenant-scoped, globally searchable, frequently filtered, write-heavy, or mostly static. The most durable designs make the shard boundary align with how the application actually asks questions.
- Tenant or namespace sharding works well when users usually search only their own data. It reduces unnecessary fan-out and makes access control easier to enforce.
- Hash-based sharding spreads data evenly and is easy to rebalance, but it may force broad query fan-out when searches are global.
- Semantic or cluster-based sharding routes similar vectors to the same or nearby shards. This can reduce query fan-out, but it requires good routing logic and can become harder to maintain as the embedding distribution changes.
- Time-based sharding is useful when recent data is searched more often than older data. It supports hot and cold storage tiers, but it may miss older relevant results unless queries include enough historical coverage.
Sharding solves capacity pressure, but it can also reduce recall if the query is not routed to the shard that contains the best neighbor. For that reason, large systems often use routing indexes, centroid indexes, or a two-stage search. A small in-memory index may identify promising shards or partitions, while deeper search runs only on those targets.
After sharding, the next pressure point is where the index lives. If every shard still needs a large in-memory graph, the cluster may remain expensive. Disk-based indexing changes that cost profile by moving more of the search structure onto SSDs.
Disk-Based Indexes
Disk-based vector indexes are designed for datasets that are too large or too expensive to keep fully in memory. Instead of assuming the whole graph or vector store lives in RAM, these systems keep selected routing data, compressed representations, caches, or entry points in memory while storing most vectors and index neighborhoods on fast SSDs. The goal is to preserve useful recall and latency while reducing the amount of RAM needed per billion vectors.
This approach is attractive because RAM is usually the most expensive resource in a large vector search cluster. SSDs offer much more capacity per dollar, but they behave differently. Random disk reads are slower than memory access, and graph-based nearest neighbor search can create scattered access patterns. A good disk-based design tries to make each query perform a bounded number of useful reads instead of wandering unpredictably through storage.
DiskANN-style approaches showed that billion-point search can be practical on SSD-backed systems by combining graph search with careful memory use and compressed representations. More recent research and production designs continue to focus on the same theme: keep enough navigation information in memory to start and guide the search, then use SSDs for the larger body of vectors and graph data.
When Disk-Based Indexes Work Well
Disk-based indexes are strongest when the dataset is very large, the workload can tolerate slightly higher latency than an all-memory index, and the system is engineered around SSD performance. They are especially useful for mostly read-heavy retrieval systems, large RAG corpora, catalog search, long-term memory stores, and applications where cost per stored vector matters more than ultra-low millisecond latency.
They are less attractive when the application needs extremely low latency, frequent high-volume updates, or complex filters that force the search to examine many candidates before finding valid results. Disk-backed search can still support these requirements, but the operational margin is thinner. The design must be careful about caching, write amplification, compaction, and how filtered queries interact with the index.
Disk changes the economics of vector search, but it does not remove the need to reduce data size. Quantization is the other major strategy because it lowers memory use, storage use, and distance computation cost.
Quantization and Compression
Quantization reduces the size of vectors by representing them with fewer bits or compact codes. Instead of storing every vector as full-precision float32 values, a system may use float16, int8 scalar quantization, binary quantization, product quantization, or another compressed representation. At billion scale, even a small reduction per vector can translate into terabytes saved.
The tradeoff is that quantization introduces approximation error. A compressed vector may not preserve distances exactly, so search quality can decline if compression is too aggressive. The practical goal is not to compress as much as possible. The goal is to compress enough to meet cost and latency targets while preserving the recall needed by the application.
Scalar Quantization
Scalar quantization compresses each vector dimension independently, often converting float values into lower-precision numbers such as int8. It is relatively simple to understand and can reduce memory use substantially. It is often a good first compression technique because it tends to preserve enough signal for many retrieval workloads while being easier to evaluate and operate than more complex compression schemes.
Product Quantization
Product quantization splits a high-dimensional vector into smaller subvectors and represents each subvector with a code from a learned codebook. This can produce much stronger compression than scalar quantization, which is why it is common in billion-scale approximate nearest neighbor systems. The cost is more training complexity, more tuning, and a greater need for reranking when high precision matters.
Reranking With Full or Higher-Precision Vectors
Many large systems use compressed vectors for the first-stage candidate search, then rerank the top candidates using full-precision or higher-precision vectors. This gives the system a practical compromise. The expensive exact comparison is applied only to a small candidate set, while the large-scale search benefits from compression.
Quantization is powerful, but it must be evaluated against the real task. A support-search system, a recommendation system, and a legal retrieval system may all have different tolerance for missed neighbors. That is why billion-scale planning needs a strong evaluation loop instead of relying only on index settings.
Choosing an Index Strategy at Billion Scale
The index strategy should follow the workload, not the other way around. HNSW, IVF, disk-backed graph indexes, and compressed indexes all have different strengths. A system that needs high recall on a hot working set may use in-memory HNSW for recent or popular data. A system that needs affordable search across a huge archive may use disk-backed search with quantization. A system with naturally clustered data may use IVF-style partitioning with reranking.
HNSW is often strong when the index fits in memory and low latency matters. Its graph structure helps search move quickly through nearby vectors, but the memory overhead can become difficult at large scale. IVF-style indexes partition the vector space into clusters and search selected partitions, which can make storage and search more predictable. Product quantization can be layered with IVF or graph-based approaches to reduce memory and storage. Disk-backed indexes are useful when the dataset exceeds practical RAM budgets.
The right choice also depends on filtering. If most queries include strict metadata filters, the system must avoid retrieving many semantically similar but invalid candidates. Pre-filtering can reduce the search space but may limit index efficiency. Post-filtering is simpler but can damage recall if too many top vector results are filtered out. At billion scale, filter-aware indexing, shard design, and candidate oversampling become important.
Once the architecture is chosen, the real work continues in operations. Very large vector indexes have a lifecycle: they are built, warmed, queried, monitored, refreshed, compacted, backed up, and sometimes rebuilt. Those steps are where many production problems appear.
Operational Realities of Very Large Indexes
Operating a billion-scale vector index requires planning for the full life of the data, not just query performance. Large indexes can take a long time to build, consume temporary storage during construction, and create performance changes when new segments are added. A design that looks efficient in a benchmark can still be painful if it cannot rebuild safely, recover quickly, or absorb daily ingestion without degrading search quality.
Freshness is one of the first operational questions. Some ANN indexes are easier to update incrementally than others, but frequent inserts and deletes can still create fragmentation, uneven graph quality, or stale partitions. Systems often separate mutable and immutable data, keeping a smaller write-friendly index for fresh vectors and periodically merging it into larger read-optimized segments.
Capacity planning also becomes less forgiving. Teams need to account for raw vectors, compressed vectors, graph edges, metadata, replicas, snapshots, build-time scratch space, caches, and query buffers. A billion-vector deployment can run out of capacity long before the raw vector count suggests it should, especially when replication and rebuild overhead are included.
Metrics That Matter
Latency averages are not enough for large vector search. Tail latency, recall, candidate counts, shard fan-out, disk read volume, cache hit rate, and filter selectivity all matter. A system can look healthy at the median while failing for queries that hit cold shards, rare filters, or dense neighborhoods.
- Recall at K shows whether the approximate system is returning enough of the true nearest neighbors for the task.
- Tail latency shows whether slow shards, disk reads, or merge steps are harming user experience.
- Shard balance shows whether some shards are carrying more vectors, traffic, or expensive filters than others.
- Index freshness shows whether newly inserted vectors are searchable within the expected window.
- Cache and disk I/O metrics show whether disk-backed search is staying within its planned read budget.
Rebuilds, Backups, and Versioning
Large indexes should be treated as versioned infrastructure. Rebuilding an index can take hours or days, and a failed rebuild can delay deployments or data refreshes. A safer pattern is to build a new index version in parallel, validate recall and latency, warm the index, then switch traffic gradually. This makes it possible to roll back if the new index performs poorly.
Backups also need special attention. Storing only the index may not be enough if the index can be rebuilt from source data, but storing only the source data may not be enough if rebuild time is too long for recovery objectives. Teams need to decide what must be recoverable quickly: vectors, metadata, index files, routing tables, quantization codebooks, and shard assignments.
These operational concerns lead to the most practical question: what strategy should a team choose first? The answer depends on scale, workload shape, and tolerance for cost, latency, and recall tradeoffs.

Practical Strategy for Billion-Scale Systems
A practical billion-scale strategy usually starts with workload segmentation. Not every vector needs the same latency target, freshness requirement, or recall level. Hot data can live in memory or a faster index. Cold data can use disk-backed search or stronger compression. Tenant-scoped data can be routed to a small number of shards. Global search may need a routing index and a broader merge step.
The next step is to evaluate compression and indexing together. Quantization, disk layout, and ANN parameters interact. Compressing vectors may reduce memory enough to increase cache hit rates, but it may also require a larger candidate set or reranking stage to preserve relevance. Similarly, reducing shard fan-out may lower latency but hurt recall if routing is too narrow.
A strong production design usually includes the following pattern: use sharding to control size and ownership, use quantization to reduce memory and compute, use disk-based indexes where RAM is not economical, use reranking to recover precision, and use continuous evaluation to catch recall regressions. The details vary, but the principle is stable: at billion scale, retrieval quality and infrastructure efficiency have to be designed together.
Common Failure Modes
Many billion-scale vector projects struggle because they underestimate the operational load of large indexes. The failure is rarely that vector search is impossible. It is more often that the architecture was designed around a small benchmark and then exposed to real filters, real updates, real traffic skew, and real cost limits.
- Over-sharding can create excessive query coordination and reduce recall if too few shards are searched.
- Under-sharding can overload machines and make rebuilds or recovery too slow.
- Over-compression can save memory while quietly damaging relevance.
- Poor filter handling can return too few valid candidates or force expensive post-filtering.
- Ignoring rebuild cost can turn normal index maintenance into a production risk.
- Weak evaluation can make latency look good while recall declines for important query classes.
These problems are avoidable when the system is evaluated with realistic data, realistic filters, realistic traffic, and realistic update patterns. Billion-scale vector search is not only about making the index fast. It is about making the whole retrieval path measurable and resilient.
FAQs
1. What is the biggest challenge when scaling to billions of vectors?
The biggest challenge is balancing memory, latency, recall, and operational complexity at the same time. Raw vector storage can reach terabytes, and the index can add even more overhead. At that scale, teams must design around sharding, compression, disk I/O, rebuilds, monitoring, and query routing instead of assuming a single in-memory index will be enough.
2. Is HNSW still useful at billion scale?
HNSW can still be useful, especially for hot data, smaller shards, or workloads where low latency and high recall matter. The limitation is memory overhead. If the full graph and vectors must fit in RAM, cost can rise quickly. Many large systems use HNSW as part of a broader design rather than as the only strategy for the entire corpus.
3. When should a vector database use disk-based indexes?
Disk-based indexes make sense when the vector collection is too large or too expensive to keep fully in memory. They are most useful for large archives, read-heavy retrieval systems, and applications where slightly higher latency is acceptable in exchange for lower infrastructure cost. They require careful SSD-aware design because random disk access can become a major bottleneck.
4. Does quantization always hurt search quality?
Quantization introduces approximation error, but it does not always hurt quality enough to matter. Many workloads can tolerate scalar quantization or product quantization when the system also retrieves enough candidates and reranks the final results. The only reliable answer is to measure recall and task-level quality on representative queries.
5. How does sharding affect recall?
Sharding can reduce recall if the query is routed to the wrong shard or if too few shards are searched. This is especially important for global semantic search, where the best neighbor could be anywhere in the corpus. Routing indexes, centroid search, shard fan-out, and reranking can help preserve recall while keeping query cost manageable.
6. What should teams monitor in a billion-scale vector system?
Teams should monitor recall, tail latency, shard balance, cache hit rate, disk I/O, candidate counts, filter selectivity, index freshness, rebuild duration, and storage growth. These metrics reveal whether the system is staying accurate, fast, and operationally safe as data and traffic change.
Takeaway
Scaling to billions of vectors is about designing a complete retrieval system, not just selecting one ANN algorithm. Sharding distributes the data and query load, disk-based indexes reduce the need for massive RAM, quantization lowers storage and compute costs, and operational discipline keeps large indexes reliable over time. This guidance is most useful for teams building large RAG systems, semantic search platforms, recommendation systems, or knowledge retrieval applications where the corpus is too large for simple in-memory search and the cost of missed or slow results matters.
Watch this video to learn more