Grounding reduces hallucinations by giving an AI system retrieved evidence to use before it answers. Instead of relying only on patterns learned during model training, the system searches a trusted knowledge source, places relevant passages in the model context, asks the model to answer from that evidence, and encourages it to cite what supports each claim. Grounding works best when the retrieved evidence is relevant, complete, and current, and when the model is instructed to say that it does not know when the evidence is missing or unclear.
This guide explains how retrieved evidence anchors answers, why citations make grounding easier to inspect, how abstention instructions reduce unsupported responses, and where grounding still falls short. By the end, you should understand how AI databases support grounded generation, what design choices matter in a retrieval pipeline, and why a grounded system still needs evaluation rather than blind trust.
What Grounding Means in AI Database Systems
Grounding is the practice of connecting a model’s answer to external evidence that can be searched, inspected, and updated. In AI database systems, that evidence usually comes from documents, records, knowledge base entries, product manuals, policies, transcripts, or other stored content. The model is not simply asked to answer from memory. It is given retrieved context and instructed to use that context as the basis for its response.
This matters because language models are fluent generators, not databases of verified facts. A model can produce confident text even when it has no reliable basis for a claim. Grounding changes the task from “generate an answer from everything you might know” to “generate an answer from these retrieved sources, and make the relationship between answer and evidence visible.” That narrower task is usually easier to control and evaluate.
In a retrieval-augmented generation system, the AI database is responsible for finding evidence that is likely to answer the user’s question. It may use vector search to match semantic meaning, keyword search to preserve exact terms, metadata filters to narrow by source or date, and reranking to improve the final set of passages. The generation model then receives the question plus the selected evidence and produces a response.
Once grounding is understood as an evidence workflow rather than a single model feature, the next question becomes more practical: how does the retrieved evidence actually reduce hallucinations during answer generation?
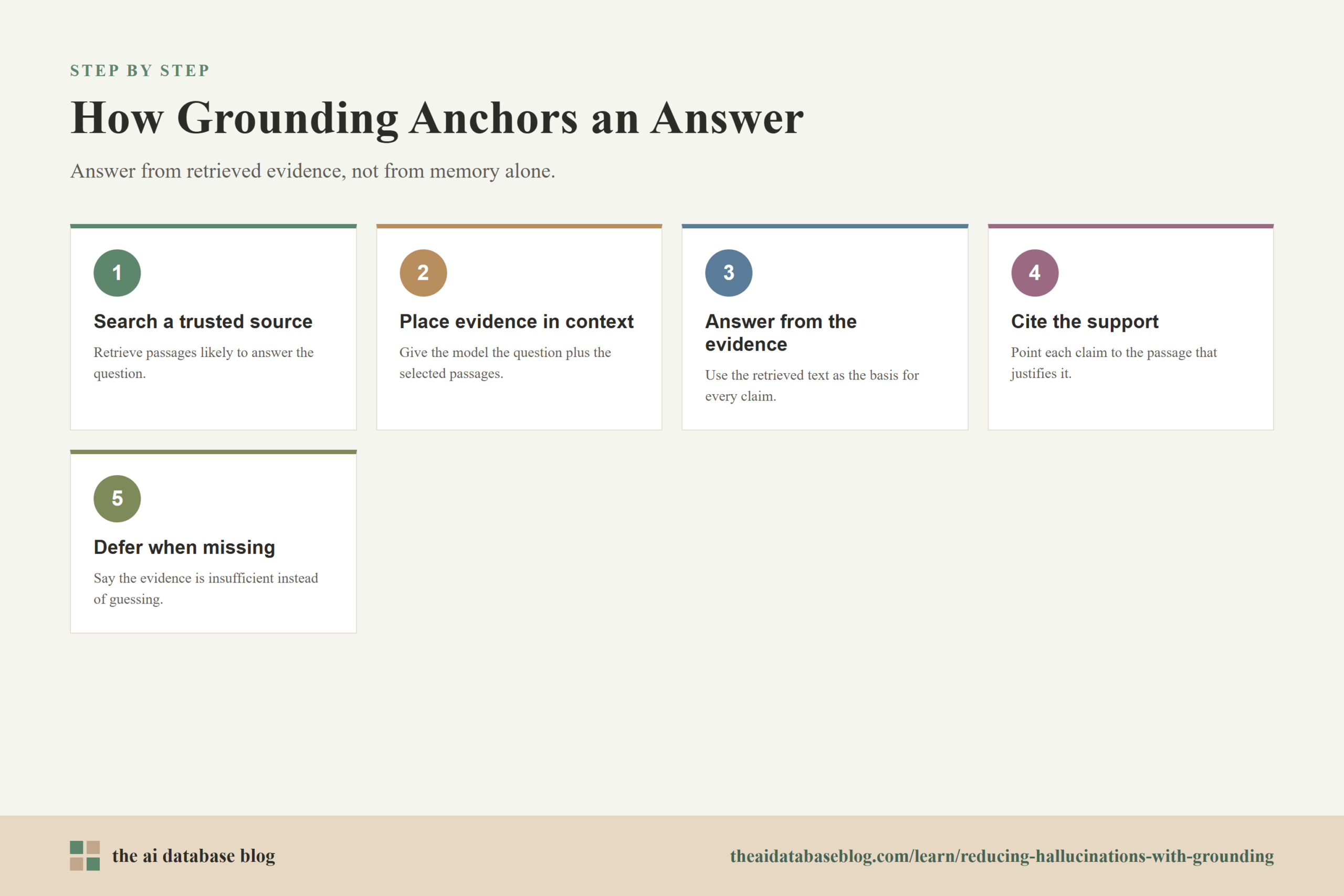
How Retrieved Evidence Anchors Answers
Retrieved evidence anchors answers by giving the model concrete material to quote, paraphrase, compare, and synthesize. If a user asks about a company policy, the system can retrieve the relevant policy section. If a user asks about a technical specification, the system can retrieve the exact specification page. If a user asks for a summary of meeting decisions, the system can retrieve the relevant transcript segments or notes.
The anchor works because the model is no longer forced to fill gaps from probability alone. It can use the retrieved text as the immediate reference point for names, dates, definitions, numbers, conditions, and exceptions. This is especially important for information that changes over time or is specific to one organization, because those facts may not exist in the model’s training data or may have changed since the model was trained.
Good grounding also limits the answer space. A model asked “What is our refund policy?” might otherwise produce a generic refund policy based on common language it has seen elsewhere. A grounded system should retrieve the organization’s actual refund policy and answer only from that material. If the retrieved evidence says refunds are available within 30 days for unused products, the answer should not invent a 60-day exception unless the evidence supports it.
However, retrieved evidence only helps when it is strong enough for the question. A passage can be relevant without being sufficient. For example, a retrieved paragraph may mention a pricing plan but not the cancellation terms the user asked about. In that case, the model has context, but not enough context. This is where grounding must be paired with citation discipline and uncertainty handling.
Why Evidence Quality Matters More Than Context Volume
It is tempting to assume that adding more retrieved text will automatically make an answer safer. In practice, grounding depends less on the amount of context and more on whether the context contains the right evidence. A long prompt filled with loosely related passages can distract the model, bury the key fact, or create contradictions that the model resolves incorrectly.
High-quality retrieval should optimize for evidence coverage, not just semantic similarity. Semantic similarity is useful because it can find passages that mean the same thing as the user’s question even when they use different words. But exact terms still matter for names, identifiers, legal language, product codes, configuration settings, and domain-specific phrases. That is why many AI database systems combine vector retrieval with keyword search, metadata filtering, and reranking.
Metadata is especially useful for grounding because it helps the system retrieve the right slice of the knowledge base. A query about an employee policy may need filters for country, department, effective date, or policy version. A query about a support issue may need filters for product line, release version, or customer tier. Without these filters, the system may retrieve content that sounds relevant but applies to the wrong situation.
Evidence freshness also matters. A grounded answer based on outdated content can be fluent and cited but still wrong. The retrieval layer should make it possible to prioritize current documents, exclude retired content, and expose source dates when they affect the answer. For use cases where facts change quickly, grounding should be connected to sources that are updated often enough to support the desired level of reliability.
After retrieval quality is handled, the next design challenge is making the answer auditable. That is where citations become useful, because they show whether the model’s claims are actually connected to the evidence it retrieved.
How Citations Make Grounded Answers Easier to Trust
Citations reduce hallucination risk by forcing the system to expose the evidence trail behind an answer. A citation does not make a claim true by itself. Its value is that it lets a reader, reviewer, or automated evaluator check whether the claim is supported by a specific source. In grounded generation, a good citation points to the retrieved document, passage, or record that justifies the statement being made.
The most useful citations are close to the claims they support. A paragraph-level citation is better than a loose list of sources at the end, and sentence-level citation is better for high-risk answers where each factual claim needs verification. If an answer says a policy changed on a certain date, that sentence should cite the policy page or changelog where the date appears. If an answer compares two options, the comparison should cite the evidence for each option rather than hiding all sources in a generic footer.
Citations also help identify weak grounding. If an answer includes several claims but only one broad citation, the citation may not support everything the model said. If a cited passage is merely topically related, the answer may still be hallucinated. If a source is cited for a claim that does not appear in that source, the citation is decorative rather than evidential.
For AI database teams, citations require source-aware data modeling. Each chunk should preserve enough information to trace it back to its original document, section, page, URL, timestamp, author, version, or record identifier. Chunking should not strip away context that is needed to interpret the passage. A retrieved sentence about an exception may be misleading if the surrounding section defines when the exception applies.
Citations make grounding inspectable, but they do not solve every failure mode. The model still needs explicit instructions about what to do when the evidence does not answer the question, because a cited but unsupported answer can be just as misleading as an uncited one.
Instructing the Model to Defer When Unsure
A grounded system should tell the model when not to answer. This is often called abstention, deferral, or uncertainty handling. The instruction is simple in spirit: if the retrieved evidence does not contain enough information to answer confidently, the model should say so rather than guessing. This turns uncertainty into an acceptable output instead of a failure to be hidden.
Deferral is important because many hallucinations happen when a model tries to be helpful despite missing evidence. A user may ask a question that is underspecified, outside the available knowledge base, or dependent on private context that was not retrieved. Without a clear abstention rule, the model may produce a plausible answer from general knowledge, infer details that are not present, or blend retrieved evidence with unsupported assumptions.
Good deferral instructions are specific. Instead of only saying “be accurate,” the system prompt can say that the model must answer only from retrieved evidence, must identify missing information when the evidence is incomplete, and must ask a clarifying question when the user’s request is ambiguous. It can also require the model to separate supported facts from uncertain interpretations.
For example, if the retrieved passages describe account setup but not billing limits, a grounded assistant should say that the available sources explain setup but do not specify the billing limit. If the user asks whether a feature is available in a particular region and the retrieved evidence only discusses global availability, the assistant should avoid assuming regional eligibility. In both cases, the safer response is not silence; it is a transparent answer about what the evidence does and does not support.
Deferral works best when the retrieval system helps the model recognize insufficiency. The system can provide confidence signals from retrieval, show source diversity, include document dates, and flag when no passage passes a relevance threshold. These signals do not replace model judgment, but they make it easier for the model to decide whether the evidence is strong enough to answer.
Once deferral is part of the design, grounding becomes a balance between usefulness and caution. The system should answer when the evidence is sufficient, explain uncertainty when it is not, and avoid turning every answer into a vague disclaimer.
Practical Grounding Patterns for AI Database Applications
Grounding is most reliable when retrieval, prompting, generation, and verification are designed together. An AI database can retrieve excellent evidence, but the model may still ignore it if the prompt is weak. A prompt can demand citations, but the citations may be low quality if chunks do not preserve source metadata. A model can abstain, but it may abstain too often if retrieval is poorly tuned.
One useful pattern is evidence-first answering. The system retrieves passages, reranks them, and asks the model to identify which passages directly support the answer before producing the final response. This encourages the model to reason from evidence instead of treating sources as background decoration. In higher-risk systems, a separate verification step can check whether each generated claim is supported by the retrieved material.
Another pattern is query decomposition. Complex questions often contain several smaller questions. If a user asks for the differences between two policies, the system may need to retrieve evidence about each policy separately, then compare them. Decomposing the query can improve coverage because the retriever does not have to satisfy every part of the question with one passage.
Hybrid retrieval is also common because different evidence types need different search signals. Vector search is strong for conceptual matches. Keyword search is strong for exact terms. Metadata filters are strong for narrowing scope. Rerankers are useful for choosing the most answer-relevant passages from a larger candidate set. Together, these methods help the system retrieve evidence that is both semantically related and practically applicable.
Grounded systems should also handle contradiction. If two retrieved sources disagree, the model should not silently choose one unless there is a clear reason, such as a newer effective date or a higher-priority source. A better answer explains the conflict, cites both sources, and states what additional information is needed to resolve it.
These patterns make grounding stronger, but they also reveal why grounding is not the same as guaranteed truth. The system is still limited by what it retrieves, how it interprets evidence, and how thoroughly its claims are checked.

The Limits of Grounding
Grounding reduces hallucinations, but it does not eliminate them. The most important limit is evidence sufficiency. If the knowledge base does not contain the answer, the retrieval layer cannot produce reliable support. The model may still infer, overgeneralize, or answer from prior knowledge unless it is instructed and evaluated to abstain when the sources are insufficient.
A second limit is retrieval failure. The answer may exist in the database, but the system may fail to retrieve it because the query is vague, the chunking is poor, the embeddings do not capture the domain language, the metadata filters are too restrictive, or the relevant document is ranked too low. In that case, the model sees an incomplete picture and may produce an incomplete or incorrect answer.
A third limit is source quality. Grounding can only anchor an answer to the available sources. If the sources are outdated, contradictory, biased, incomplete, or wrong, a grounded answer can faithfully repeat bad information. This is why grounding should be paired with content governance, version control, document ownership, and review workflows for high-impact domains.
A fourth limit is citation misuse. Models can attach citations to claims that the cited passages do not actually support. This creates a false sense of reliability because the answer looks grounded even when the evidence trail is weak. Citation checking, claim-level evaluation, and human review are important when the cost of an unsupported answer is high.
A final limit is reasoning over evidence. Some questions require synthesis across multiple sources, careful handling of exceptions, or awareness of what is not stated. Even with relevant evidence, the model can make a reasoning error. Grounding gives the model better material to reason from, but it does not guarantee that the reasoning will be correct.
Because of these limits, the goal is not to declare a grounded system hallucination-free. The goal is to make unsupported answers less likely, easier to detect, and easier to correct.
How to Evaluate Whether Grounding Is Working
Grounding should be evaluated directly rather than assumed from the presence of retrieval. A system can retrieve documents and still produce unsupported answers. Evaluation should ask whether the answer is correct, whether it is supported by the cited evidence, whether important evidence was missed, and whether the model abstained when the context was insufficient.
Useful evaluation metrics include retrieval recall, answer faithfulness, citation precision, citation coverage, abstention quality, and user task success. Retrieval recall asks whether the system found the evidence needed to answer. Faithfulness asks whether the answer stays within that evidence. Citation precision asks whether cited sources truly support the claims attached to them. Abstention quality asks whether the model declines only when it should, rather than guessing or refusing unnecessarily.
Evaluation should include answerable and unanswerable questions. If the test set only contains questions with known answers in the knowledge base, it will not show whether the system can recognize missing evidence. A good evaluation set includes ambiguous questions, outdated questions, questions with partial evidence, questions with conflicting sources, and questions outside the knowledge base.
Human review is still valuable, especially when the domain has high stakes or subtle source interpretation. Automated checks can flag unsupported claims, missing citations, or low retrieval confidence, but subject matter experts are often needed to judge whether an answer is practically correct. Over time, review findings can improve chunking, metadata, retrieval tuning, prompts, and source governance.
Evaluation closes the loop. It shows whether grounding is actually reducing hallucinations in the specific application, not just whether the architecture looks reasonable on paper.
FAQs
1. What is grounding in an AI system?
Grounding is the process of connecting a model’s answer to external evidence, such as retrieved documents, database records, or search results. In AI database applications, grounding usually means retrieving relevant content first and asking the model to answer from that content rather than relying only on its trained knowledge.
2. Does grounding completely prevent hallucinations?
No. Grounding reduces hallucinations, but it does not eliminate them. The system can still retrieve incomplete evidence, use outdated sources, misread a passage, attach weak citations, or make reasoning errors. Grounding is strongest when it is paired with citation checking, abstention rules, and ongoing evaluation.
3. Why are citations important in grounded answers?
Citations make the evidence trail visible. They let readers and evaluators check whether specific claims are supported by specific sources. The best citations are tied closely to the claims they support, because broad source lists can make an answer look trustworthy without proving that each statement is grounded.
4. What should a model do when retrieved evidence is incomplete?
The model should say that the available evidence is incomplete and avoid filling the gap with a guess. Depending on the use case, it can ask a clarifying question, explain what the sources do support, or recommend checking a specific missing source. The key is to make uncertainty visible instead of hiding it behind a confident answer.
5. How does an AI database improve grounding?
An AI database improves grounding by storing searchable content, preserving source metadata, supporting vector and keyword retrieval, applying metadata filters, and returning evidence that can be cited. Its job is not only to find similar text, but to retrieve the evidence that is most likely to support a correct answer.
6. What is the biggest mistake teams make with grounding?
The biggest mistake is assuming that retrieval alone makes an answer reliable. A grounded system still needs good source quality, careful chunking, effective retrieval, clear prompts, citation discipline, abstention behavior, and evaluation. Without those pieces, the system may produce answers that look grounded but are still unsupported.
Takeaway
Grounding helps reduce hallucinations by anchoring model responses to retrieved evidence, making claims easier to inspect through citations, and giving the model permission to defer when the available sources are not enough. This guidance is most useful for teams building retrieval-augmented generation systems, enterprise knowledge assistants, support tools, research copilots, and other AI applications where factual reliability matters. A practical use case is an internal policy assistant that retrieves the right policy version, cites the exact section behind each answer, and says when the policy library does not contain enough information to answer safely.
Watch this video to learn more