Voronoi cells are one of the simplest ways to understand how many vector indexes make search faster: a set of centroid vectors divides the embedding space into regions, and each stored vector is assigned to the region of its nearest centroid. In an IVF index, those regions become inverted lists, so a query can search only the most relevant partitions instead of scanning every vector. The quality of that partitioning matters because poor centroids can place true neighbors in regions the query does not visit, lowering recall even when the distance function and embeddings are otherwise appropriate.
This guide explains how centroids partition vector space, why that partitioning affects recall, and how the same idea becomes the foundation of inverted file indexing for approximate nearest neighbor search. By the end, you should be able to reason about why IVF works, where it can fail, and which tuning choices control the balance between search speed and result quality.
What a Voronoi Cell Means in Vector Search
A Voronoi cell is the region of space that is closer to one selected point than to any other selected point. In vector search, the selected points are usually centroids learned from the dataset. Each centroid acts like a representative for a cluster of nearby vectors, and every vector is assigned to the centroid it is closest to under the index’s distance or similarity measure.
Imagine a two-dimensional map with several anchor points scattered across it. If every location on the map is colored according to the nearest anchor point, the map is divided into polygon-like regions. Those regions are Voronoi cells. In real AI database workloads, the space is usually hundreds or thousands of dimensions rather than two, but the same idea applies: each centroid owns a region of the embedding space.
This matters because vector search is built around distance. Embeddings that are close together are assumed to represent items with related meaning, behavior, or content. Partitioning the space by centroid proximity gives the database a way to narrow the search area before doing more detailed comparisons.
Once this partitioning idea is clear, the next question is how the centroids are chosen. The usefulness of each cell depends less on the abstract geometry and more on whether the centroids actually reflect the shape of the stored data.
How Centroids Partition Vector Space
Centroids usually come from a clustering process such as k-means. The index trains on a sample of vectors, chooses a target number of clusters, and iteratively adjusts centroid positions so that vectors are grouped around nearby representatives. After training, each database vector is assigned to its nearest centroid, and that assignment determines which partition the vector belongs to.
The number of centroids controls how fine-grained the partitioning is. With a small number of centroids, each cell contains many vectors, so search has fewer partitions to choose from but more candidates inside each partition. With a large number of centroids, each cell is smaller, which can reduce the number of candidate vectors per cell, but the system has more centroids to compare against and more partitions that might need to be probed.
Centroids also create boundaries. A vector near the center of a cell is usually easy to assign because it is clearly closest to one centroid. A vector near the boundary between cells is more ambiguous. It may be assigned to one centroid even though its nearest useful neighbors sit just across the boundary in another cell. This boundary effect is one of the main reasons approximate search can miss relevant results.
In high-dimensional embedding spaces, the shape of the data is rarely uniform. Some topics, users, documents, or product categories may form dense areas, while others are sparse or stretched out. Good centroids adapt to that distribution. Weak centroids create partitions that are too large, too uneven, or poorly placed for the actual query patterns the application needs to support.
That leads directly to recall. Partitioning is not only a storage decision; it decides which candidates the search process is likely to inspect and which candidates it may never see.

Why Partition Quality Affects Recall
Recall measures how many of the truly relevant nearest neighbors are returned by the search system. In exact search, recall is high because every vector is considered. In approximate search, recall can fall because the system intentionally skips much of the dataset to reduce latency and computational cost. With partition-based search, the skipped data is usually the vectors in cells that were not selected for probing.
Partition quality affects recall because the index assumes that the nearest centroid or a small set of nearest centroids will contain the best candidate vectors. When that assumption is true, the system can search quickly while still finding most of the right results. When that assumption is false, the true nearest neighbors may be outside the visited partitions, so the system cannot return them no matter how accurately it ranks the candidates it did inspect.
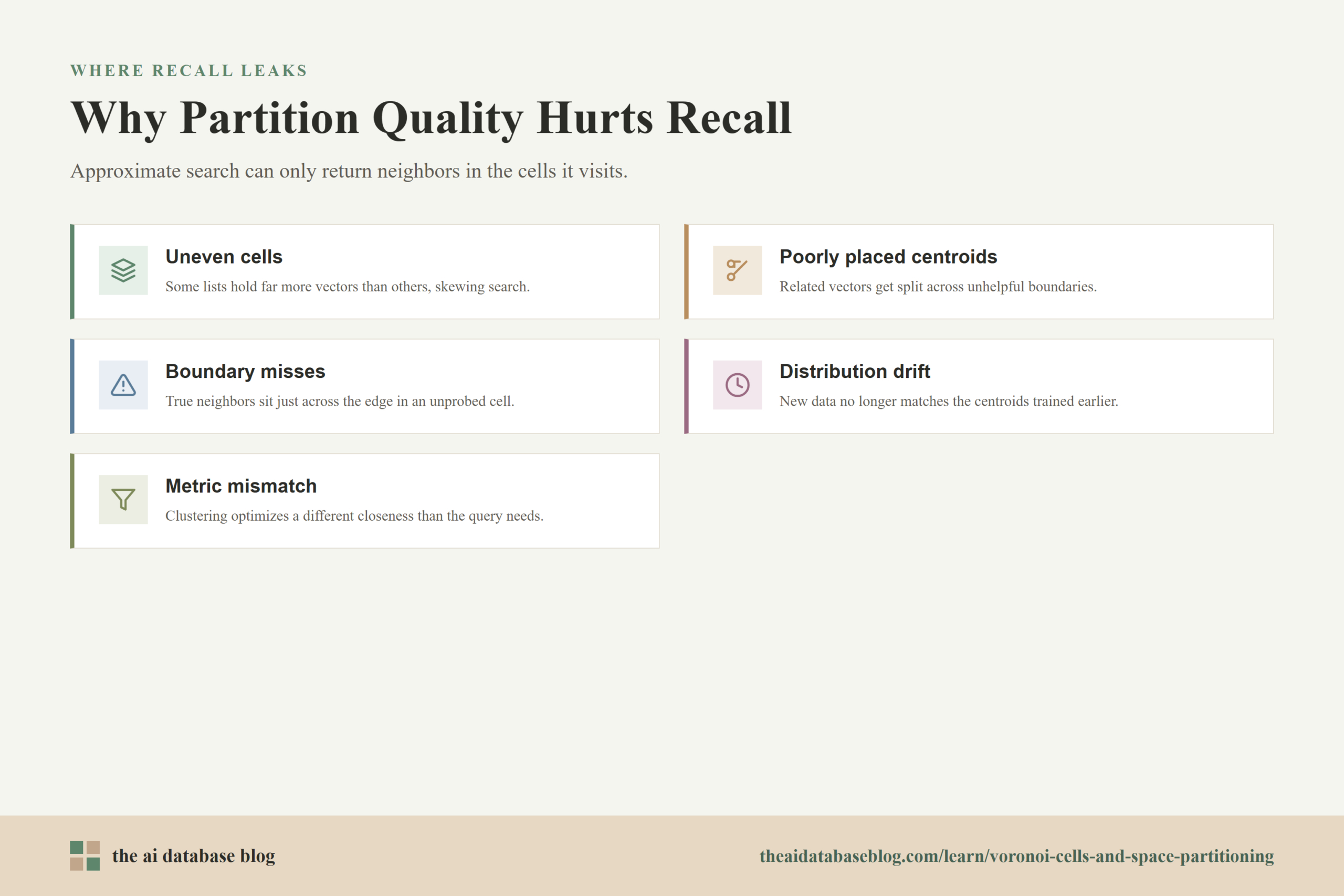
Several partitioning problems can reduce recall:
- Uneven cells: Some partitions may contain far more vectors than others. Large cells can make search slower, while tiny cells may force the query to probe more partitions to find enough strong candidates.
- Poorly placed centroids: If centroids do not match natural clusters in the data, vectors that should be searched together may be split apart in unhelpful ways.
- Boundary misses: A query near a cell boundary may have true nearest neighbors in adjacent cells. If the search probes only one partition, those neighbors can be missed.
- Distribution drift: If the data changes after the index is trained, the centroids may no longer represent the current embedding distribution well.
- Metric mismatch: If the clustering process and search metric are not aligned with the application’s relevance goal, the partitions may optimize the wrong notion of closeness.
These issues do not mean partition-based indexes are unreliable. They mean the index is making a deliberate approximation. The quality of that approximation depends on training data, centroid count, query behavior, and how many neighboring partitions are searched at query time.
To see how this becomes a practical database index, it helps to connect Voronoi cells to the inverted file structure used in IVF.
The Link Between Voronoi Cells and IVF Indexing
IVF stands for inverted file. In vector search, an IVF index uses centroids as a coarse quantizer: a first-stage model that maps each vector to a partition. Each partition has an inverted list containing the vectors assigned to that centroid. At query time, the system compares the query vector to the centroids, chooses the nearest centroid lists, and then searches only the vectors inside those lists.
The connection to Voronoi cells is direct. Each centroid defines a cell, and each cell becomes an inverted list. If a dataset has 4,096 centroids, it has 4,096 coarse partitions. The query does not need to compare itself to every stored vector immediately. It first compares itself to the centroids, identifies the most promising cells, and searches within those smaller candidate pools.
Two common IVF parameters explain the speed-recall tradeoff:
- nlist: The number of centroid partitions or inverted lists in the index. More lists usually mean smaller partitions, but also more centroid structure to train and manage.
- nprobe: The number of partitions searched for each query. Higher nprobe usually improves recall because more neighboring cells are inspected, but it also increases latency because more candidate vectors are evaluated.
For example, if a query probes only the single closest centroid, search may be fast but vulnerable to boundary misses. If it probes the nearest 10 or 50 centroids, it has a better chance of including the cells that contain true nearest neighbors. The result is a tunable approximation: the database can spend more or less work per query depending on the application’s relevance and latency needs.
This is why IVF is often described as a coarse-to-fine search method. The coarse stage chooses likely regions of the vector space. The fine stage ranks candidate vectors inside those regions, sometimes using exact vector distances and sometimes using compressed representations such as product quantization.
Understanding the mechanism makes IVF easier to tune. The next step is to think about what makes a partition good in practical AI database workloads.
What Makes a Good Space Partition
A good partition is one that keeps likely neighbors together while keeping candidate sets small enough to search efficiently. This is a balancing act. If partitions are too broad, the index saves less work because each selected list contains too many vectors. If partitions are too narrow, the query may need to probe many lists to avoid missing neighbors near cell boundaries.
Good partitioning usually depends on representative training data. The centroid training set should resemble the vectors that will actually be stored and queried. If the training sample overrepresents one domain, language, content type, or user behavior pattern, the centroids may allocate too much structure to that part of the space and too little to others.
Balanced cells are helpful, but balance alone is not enough. A partition can have similar list sizes while still splitting semantically related vectors across boundaries. The goal is not just equal buckets; it is useful candidate generation. The partitions should increase the probability that the vectors worth ranking are present in the probed lists.
Query distribution also matters. Some applications have queries that resemble stored documents. Others have short user prompts, product descriptions, code snippets, or multimodal embeddings that land in different parts of the space. If query vectors and stored vectors occupy different patterns, the nearest centroid routing may need more probing or a different indexing strategy to achieve strong recall.
Once partition quality is viewed as candidate generation, tuning becomes more concrete. The practical question is no longer whether IVF is accurate in the abstract, but whether a particular partitioning strategy finds enough good candidates within the latency budget.
How to Tune IVF for Better Recall
Improving IVF recall usually starts with measurement. Run queries with known or manually judged relevant results, compare approximate search against a stronger baseline, and track recall at the result depth your application actually uses. Recall at 10, for example, may matter more for a retrieval-augmented generation system than recall at 1 if the generator receives several context chunks.
The most direct tuning lever is nprobe. Increasing nprobe searches more Voronoi cells and reduces the chance that true neighbors are excluded by the coarse partitioning step. This is often the first adjustment to test because it changes query-time behavior without necessarily rebuilding the entire index.
Changing nlist can also help, but it usually requires retraining or rebuilding the index. A higher nlist can create smaller, more specific partitions, which may reduce candidate volume per list. However, if nprobe is too low, more partitions can also make boundary misses more likely because the nearest neighbors may be spread across more cells. A lower nlist can simplify routing but may leave each list too large for efficient search.
Other practical checks include:
- Train centroids on representative data: Use a sample that reflects the actual stored vectors and expected query patterns.
- Monitor list imbalance: Very large or very small lists can indicate that the centroids are not distributing the dataset well.
- Retune after major data changes: New domains, languages, embedding models, or document types can change the geometry of the vector space.
- Evaluate with metadata filters: If the application filters by tenant, category, time, or permissions, measure recall under those filtered conditions, not only on the whole dataset.
- Compare latency and recall together: A configuration is only good if it meets both relevance and performance requirements for the real workload.
These tuning steps are especially important because IVF is rarely used in isolation from application constraints. Retrieval quality, storage cost, filtering behavior, and response latency all shape whether a partitioning strategy is a good fit.
When IVF Partitioning Works Well
IVF works best when the dataset has enough structure for centroid-based routing to be meaningful. If vectors form recognizable clusters, the coarse quantizer can quickly route queries into useful regions. This is common in large collections of documents, products, images, support tickets, or other content where embeddings group related items together.
IVF can be especially useful when the dataset is large enough that exact search is too expensive, but the application still needs control over the recall-latency tradeoff. By adjusting how many partitions are searched, teams can choose whether a workload should prioritize faster responses or more exhaustive candidate coverage.
It is less ideal when the dataset is small enough for exact search, when recall requirements are extremely strict, or when the embedding distribution is difficult to partition cleanly. It can also require more operational care than simpler approaches because centroid training, index rebuilding, and parameter tuning affect the quality of results.
For AI applications, the important lesson is that IVF is not just a performance trick. It is a specific assumption about the shape of vector space: nearby vectors can be grouped around centroids, and queries can find good candidates by searching a limited number of those groups.
FAQs
1. What is a Voronoi cell in an AI database?
A Voronoi cell is the part of vector space assigned to one centroid because points in that region are closer to that centroid than to any other centroid. In an AI database index, this lets the system group stored vectors into partitions that can be searched more efficiently than the full dataset.
2. How do centroids divide vector space?
Centroids divide vector space by nearest-centroid assignment. Each stored vector is compared to the available centroids and placed in the partition owned by the closest one. The result is a set of regions that approximate the structure of the embedding space.
3. Why can IVF miss relevant nearest neighbors?
IVF can miss relevant neighbors when those neighbors are located in partitions that the query does not search. This often happens near Voronoi boundaries, where a query may be routed to one centroid even though some true nearest neighbors are assigned to nearby cells.
4. What does nprobe do in an IVF index?
nprobe controls how many centroid partitions the query searches. A higher nprobe visits more inverted lists, which usually improves recall because more candidate vectors are considered. The tradeoff is that higher nprobe also increases search work and may raise latency.
5. Is a higher number of IVF partitions always better?
No. More partitions can make each list smaller, but they can also make tuning harder because relevant neighbors may be spread across more cells. A higher partition count often needs a suitable nprobe value and representative centroid training to improve results.
6. How is IVF related to product quantization?
IVF and product quantization are often combined, but they solve different parts of the search problem. IVF narrows the search to selected partitions, while product quantization compresses vectors or residuals so candidates can be stored and compared more efficiently. Together, they can support large-scale approximate search with lower memory use.
Takeaway
Voronoi cells explain the geometry behind IVF indexing: centroids divide vector space into partitions, each partition becomes an inverted list, and queries search the most promising lists instead of the entire dataset. This is useful for engineers, architects, and technical readers who want to understand why vector indexes are fast, why recall can drop, and how parameters such as nlist and nprobe shape practical AI database behavior. For use cases such as retrieval-augmented generation, semantic search, recommendation, and large-scale content retrieval, the key lesson is that partition quality determines whether approximate search skips irrelevant work without skipping the neighbors that matter.