Re-ranking improves a RAG pipeline by adding a second retrieval stage that carefully reorders the most promising results before they are sent to the language model. A first-stage retriever, such as vector search, keyword search, or hybrid search, quickly finds a broad candidate set. A re-ranker then scores those candidates more precisely against the user query, often using a cross-encoder model. The result is usually better context quality, fewer irrelevant chunks in the prompt, and more grounded answers, but the improvement comes with extra latency and compute cost.
This guide explains how re-ranking fits into retrieval-augmented generation, why cross-encoders are commonly used for the second stage, how to choose the top-K candidate set to re-rank, and how re-ranking affects answer quality and response time. By the end, you should understand when re-ranking is worth adding, how to tune it, and what to measure before treating it as a production requirement.
Why Re-ranking Matters in RAG
A RAG system depends on the quality of the context it retrieves. If the language model receives passages that contain the answer, use the right terminology, and exclude distracting near-matches, it has a much better chance of producing a useful response. If retrieval sends weak or noisy context, the generation step may sound fluent while relying on incomplete, outdated, or unrelated information. Re-ranking matters because first-stage retrieval is usually optimized for speed and recall, not for final answer precision.
First-stage retrievers are good at narrowing a large corpus down to a manageable set of candidate chunks. Dense vector search finds text that is semantically similar to the query, keyword search finds exact or near-exact term matches, and hybrid search combines signals from both. These methods are efficient enough to run over large indexes, but their scores are not always subtle enough to decide which few passages should enter the prompt. A chunk can be semantically close without answering the question, and a chunk can share keywords while discussing the wrong policy, product, time period, or entity.
Re-ranking adds a precision-focused step after initial retrieval. Instead of asking the first-stage retriever to do everything, the system asks it to find a wide enough shortlist. The re-ranker then evaluates that shortlist with a more expensive but more discriminating model. In practical RAG terms, this often means retrieving dozens of candidates and then selecting only a small number of re-ranked chunks for generation.
This division of labor is the core idea behind two-stage retrieval. The first stage answers, “What might be relevant?” The second stage answers, “Which of these candidates is most relevant to this exact query?” Once that separation is clear, the next question is what kind of model should perform the second stage.
How a Cross-encoder Re-ranking Stage Works
A cross-encoder is a common choice for re-ranking because it compares the query and each candidate passage together rather than representing them separately. In a typical vector search setup, a query and a document chunk are each converted into embeddings, and similarity is computed between those vectors. That approach is fast because document embeddings can be precomputed and stored in an AI database. A cross-encoder is slower because it reads the query and candidate text as a pair at query time, but that paired attention helps it judge relevance more directly.
In a RAG pipeline, the cross-encoder stage usually follows this pattern:
- The user asks a question.
- The system retrieves an initial candidate set from the AI database, often using vector, keyword, or hybrid search.
- The cross-encoder receives the query paired with each candidate chunk.
- The cross-encoder assigns a relevance score to each query-chunk pair.
- The system sorts candidates by the new scores and sends only the strongest chunks to the generator.
The important difference is that the cross-encoder can consider word order, phrase interactions, negation, entity relationships, and query intent inside the same model pass. For example, a vector retriever may bring back several chunks about “data retention,” but the cross-encoder can better distinguish a chunk about retention policy exceptions from a chunk that merely defines retention in general. That distinction can matter a great deal when the final answer depends on a small clause or a specific condition.
Cross-encoders are not the only re-ranking option. Some pipelines use lightweight learned rankers, late-interaction models, LLM-based scoring, rules, metadata boosts, or cascades that combine several approaches. Still, cross-encoders are a useful default concept because they show the tradeoff clearly: higher query-document precision in exchange for additional inference work.
Once a cross-encoder is added, the pipeline has a new tuning problem. The re-ranker cannot improve candidates it never sees, so the size and quality of the initial candidate set become critical. That is where top-K selection becomes one of the most important design choices.
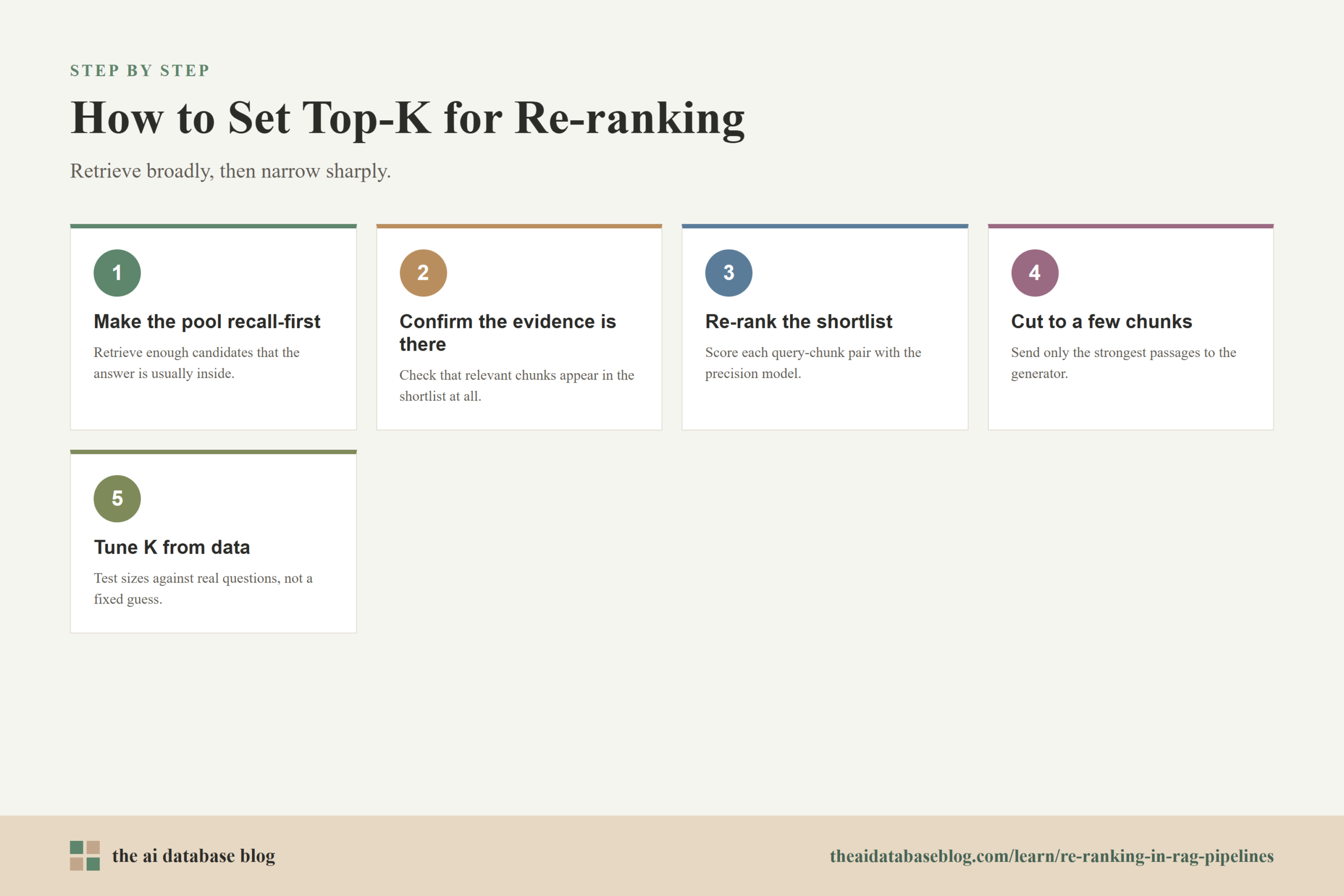
Choosing the Top-K Candidates to Re-rank
Top-K is the number of initial retrieval results passed into the re-ranking stage. It is easy to treat this as a simple setting, but it controls a major quality and latency tradeoff. If K is too small, the right chunk may be missing from the candidate set, and the re-ranker cannot recover it. If K is too large, the re-ranker has more chances to find the best evidence, but it also has to score more query-chunk pairs, which increases latency and cost.
A useful way to think about K is to separate retrieval breadth from generation context. The system may retrieve the top 50 or 100 candidates for re-ranking, but it should not automatically send all of those candidates to the language model. Re-ranking is most useful when it lets the system search broadly, then narrow sharply. For many RAG applications, the final prompt may contain only a handful of chunks even though the re-ranker evaluated a much larger shortlist.
Start with recall, then tune for precision
The first-stage candidate set should be large enough that relevant evidence usually appears somewhere inside it. This is a recall problem. If relevant chunks are often absent from the first 20 results but present by the first 80, a re-ranker over only 20 candidates will not solve the issue. In that case, the retriever needs a larger K, better hybrid retrieval, improved chunking, stronger metadata filters, or query expansion before re-ranking can help reliably.
After the candidate set has acceptable recall, tune the final number of chunks sent to generation for precision. The language model does not benefit from unlimited context if much of that context is marginally related. Too many chunks can dilute the prompt, introduce contradictions, and make it harder for the model to identify the best evidence. Re-ranking helps by placing the strongest candidates at the top, but the pipeline still needs a final cutoff.
Use evaluation data instead of a fixed guess
A reasonable starting point is to test several values, such as retrieving 20, 50, 100, or 200 candidates for re-ranking, then returning the best 3 to 10 chunks for generation. The right values depend on corpus size, chunk length, query complexity, model speed, and the cost of a wrong answer. A support chatbot over concise documentation may work well with a smaller candidate set. A legal, scientific, or compliance-oriented system may need broader retrieval because relevant passages can be sparse, subtle, or phrased differently from the query.
The best K is therefore empirical. Use a test set of real or realistic questions, known relevant passages when available, and answer-quality checks. Track whether the relevant evidence appears in the initial candidate set, whether the re-ranker moves it near the top, and whether the final answer improves. Without that evaluation loop, K becomes a guess hidden inside a production setting.
Choosing K is not only about retrieval metrics. It also changes the user experience because every additional candidate creates more work for the re-ranker. The next step is to understand how that work affects answer quality and latency together.
Impact on Answer Quality
Re-ranking can improve answer quality because it changes the evidence the language model sees. In a RAG pipeline, generation quality is tightly linked to context precision, context recall, and the ordering of retrieved chunks. A cross-encoder re-ranker does not make the language model smarter by itself. It improves the input conditions by filtering and ordering evidence so the model is more likely to ground its answer in the most relevant passages.
The most common quality improvements are better factual grounding, fewer irrelevant citations, and stronger handling of questions where the wording differs from the stored text. Re-ranking is especially useful when the corpus contains many similar chunks. Internal documentation, policy libraries, product manuals, and technical knowledge bases often have repeated phrases across different pages. First-stage retrieval may find a cluster of similar passages, while the cross-encoder is better positioned to decide which one actually answers the question.
Re-ranking also helps when the answer depends on a relationship between the query and a passage, not just overall topical similarity. Consider a question like, “When should archived customer records be excluded from model training?” A chunk about customer records and a chunk about model training may both look similar in embedding space, but the best passage is the one that specifically connects archived records, exclusion criteria, and training use. A cross-encoder can score that direct match more carefully.
However, re-ranking is not a cure for every RAG problem. It cannot find information that is missing from the index. It cannot fully correct poor chunking if the answer is split awkwardly across passages. It may underperform if the re-ranker was trained on a very different domain or language from the target corpus. It can also over-prioritize passages that look locally relevant but lack enough surrounding context to support a complete answer.
For that reason, answer quality should be measured at more than one level. Retrieval metrics such as recall at K, precision at K, mean reciprocal rank, and normalized discounted cumulative gain can show whether better evidence is appearing near the top. Generation metrics and human review can show whether answers are more correct, complete, faithful, and useful. The most important production question is not simply whether the re-ranker changes the ranking, but whether users receive better answers.
Quality gains are valuable only if the system remains responsive enough for its use case. A batch research assistant, an internal analyst workflow, and a real-time customer support chat may all tolerate different delays. That makes latency the other half of the re-ranking decision.
Impact on Latency and Cost
Re-ranking adds latency because the second-stage model must score each candidate at query time. A first-stage vector or hybrid search can often return candidates quickly because the index is designed for fast lookup. A cross-encoder, by contrast, performs model inference over the query and each candidate passage. As K grows, the number of query-passage pairs grows with it, and the re-ranking stage can become a visible part of total response time.
The latency impact depends on model size, hardware, batching, candidate length, concurrency, and whether the re-ranker is hosted locally or called through a service. A small cross-encoder over 20 short chunks may add a modest delay. A larger model over 200 long chunks can become expensive enough to dominate retrieval time. In many RAG systems, generation by the language model is still the slowest stage, but re-ranking can meaningfully increase the time before generation even begins.
Cost follows the same pattern. More candidates mean more scoring work. Longer chunks mean more tokens or model computation per candidate. Higher traffic multiplies the effect. This is why re-ranking should be treated as a precision tool rather than a default expansion mechanism. The goal is not to re-rank as much as possible. The goal is to re-rank enough candidates to improve answer quality within the latency budget.
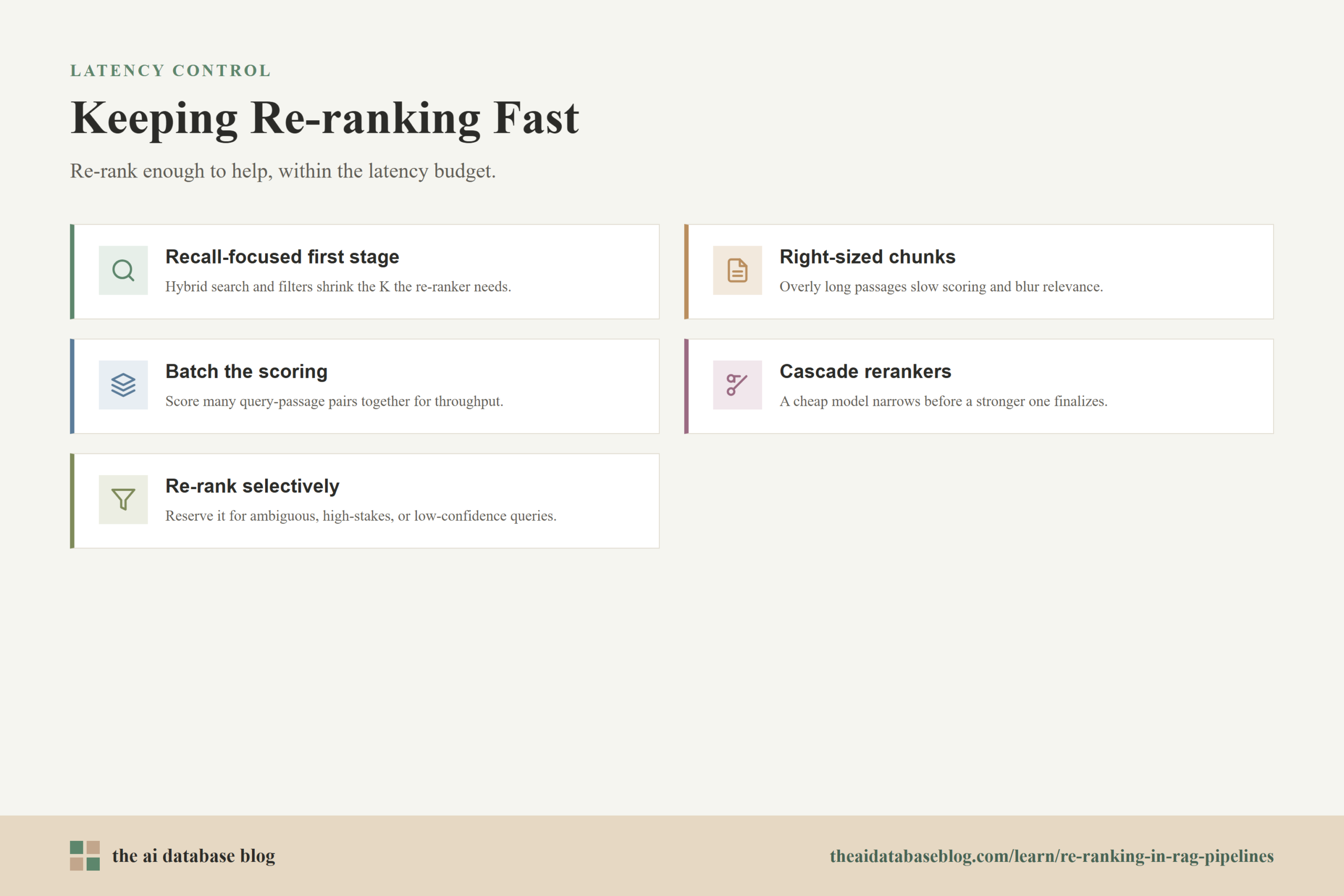
Several practical techniques can keep latency under control:
- Use a recall-focused first stage. Hybrid search and good metadata filters can improve the candidate set before the re-ranker sees it, reducing the need for very large K values.
- Keep chunks appropriately sized. Chunks that are too long slow down scoring and may blur relevance. Chunks that are too short may lack enough context. The best size depends on the corpus and answer style.
- Batch candidate scoring. Scoring multiple query-passage pairs together can improve throughput, especially on hardware suited for parallel model inference.
- Use cascades when needed. A smaller or cheaper re-ranker can narrow a larger set before a stronger model evaluates the final shortlist.
- Apply re-ranking selectively. Some queries are easy enough for first-stage retrieval. Re-ranking can be reserved for ambiguous, high-stakes, low-confidence, or citation-sensitive queries.
These techniques show that re-ranking is not a single switch. It is a design choice that affects the entire retrieval path. To make it work well, the pipeline needs clear operating rules for when to re-rank, how many candidates to score, and how to judge whether the extra time is justified.
Practical Design Pattern for Production RAG
A production-friendly RAG pipeline usually treats re-ranking as one part of a broader retrieval architecture. The first stage should maximize the chance that the right evidence appears in the candidate pool. The second stage should improve ordering and precision. The final generation step should receive a compact, high-quality context set that is easy for the language model to use. This structure keeps each component responsible for the work it does best.
A practical version of the pattern looks like this:
- Normalize and chunk source content so each chunk has enough meaning to stand alone.
- Store embeddings, text, and useful metadata in the AI database.
- Use vector, keyword, or hybrid retrieval to get a recall-oriented candidate set.
- Apply metadata filters before re-ranking when the user’s query clearly implies scope, such as product, region, date, access level, or document type.
- Re-rank the top-K candidates with a cross-encoder or another precision-focused model.
- Send the best few chunks, with source metadata, to the generator.
- Evaluate retrieval quality, answer quality, latency, and cost together.
This pattern also makes failures easier to diagnose. If the right chunk is not in the initial candidate set, the problem is likely first-stage retrieval, filtering, chunking, or indexing. If the right chunk is present but ranked too low after re-ranking, the problem may be the re-ranker, domain mismatch, candidate text length, or scoring setup. If the right chunks reach the generator but the answer is still weak, the issue may be prompt design, context formatting, answer synthesis, or the generation model.
For many teams, the strongest implementation is not the most complex one. A well-tuned hybrid retriever plus a cross-encoder over a moderate candidate set can outperform a larger, slower pipeline that sends too much context downstream. The useful question is always concrete: does this re-ranking stage improve the answers enough for the users who rely on this system?
Answering that question requires a measurement plan. Without measurement, teams may either skip re-ranking because they fear latency or add it everywhere because it sounds like an obvious quality upgrade. Both choices can be wrong depending on the application.
How to Evaluate Whether Re-ranking Is Worth It
The right way to evaluate re-ranking is to compare pipelines under realistic conditions. Use the same question set, same indexed content, and same generation model, then vary the retrieval and re-ranking settings. This makes it easier to see whether answer improvements come from the re-ranker itself rather than from unrelated changes in chunking, prompting, or model behavior.
Start with retrieval-level evaluation. Check whether known relevant chunks appear in the first-stage top-K candidates. Then check whether the re-ranker moves those chunks closer to the top. Metrics such as recall at K, precision at K, mean reciprocal rank, and normalized discounted cumulative gain are useful because they describe different aspects of retrieval quality. Recall shows whether the evidence is present. Precision shows how much of the returned context is useful. Ranking metrics show whether the best evidence appears early enough to matter.
Then evaluate generated answers. A RAG answer can improve even if retrieval metrics move only modestly, because the final prompt may become cleaner and less contradictory. It can also fail to improve if the generator ignores the better evidence or receives too little context after filtering. Human review, reference answers, citation checks, faithfulness scoring, and task-specific acceptance criteria can all help determine whether re-ranking improves the actual user-facing output.
Finally, measure latency and cost at the same time. Track average latency, high-percentile latency, throughput, model cost, and timeout rates. A re-ranker that improves answer quality by a small amount may still be worthwhile for high-value research or compliance workflows. The same re-ranker may be too slow for a high-volume chat interface where users expect near-instant responses. The decision should reflect the value of precision in the specific use case.
Once evaluation connects retrieval behavior to answer quality and latency, re-ranking becomes much easier to reason about. The remaining questions tend to be practical ones: when should it be used, how large should K be, and what tradeoffs should teams expect?
FAQs
1. What is re-ranking in a RAG pipeline?
Re-ranking is a second-stage retrieval step that reorders an initial set of retrieved chunks before they are sent to the language model. The first retriever quickly finds candidates from the AI database, and the re-ranker scores those candidates more carefully against the query. The goal is to place the most useful evidence at the top and reduce irrelevant context in the final prompt.
2. Why use a cross-encoder for re-ranking?
A cross-encoder is useful because it evaluates the query and candidate passage together. This allows it to model detailed interactions between the question and the text, which can improve relevance judgments. The tradeoff is that it usually cannot precompute document scores in the same way an embedding retriever can, so it adds query-time latency.
3. How many candidates should a RAG system re-rank?
There is no universal top-K value. A common approach is to test several candidate sizes, such as 20, 50, 100, or more, and measure whether the right evidence appears in the pool and moves near the top after re-ranking. The best value is the smallest K that gives acceptable recall and answer quality within the latency budget.
4. Does re-ranking always improve answer quality?
No. Re-ranking often helps when first-stage retrieval returns noisy or hard-to-order candidates, but it cannot fix missing data, poor indexing, weak chunking, or a re-ranker that does not match the domain. It should be evaluated against real questions to confirm that it improves final answers, not just retrieval scores.
5. How does re-ranking affect latency?
Re-ranking adds latency because the model must score each candidate at query time. The added delay depends on the number of candidates, chunk length, model size, hardware, batching, and traffic level. Larger candidate sets can improve recall but also increase response time, so top-K should be tuned with latency in mind.
6. When is re-ranking most useful?
Re-ranking is most useful when precision matters and the initial retriever returns several plausible but uneven candidates. It is especially helpful for policy search, technical documentation, compliance workflows, support knowledge bases, and other domains where similar chunks can lead to different answers. It may be less necessary for small, clean corpora where the top results are already highly reliable.
Takeaway
Re-ranking in RAG pipelines is a practical way to improve retrieval precision by adding a cross-encoder or similar second-stage model after the initial AI database search. The key is to retrieve broadly enough that the right evidence appears in the candidate set, re-rank only the top-K candidates that are worth the extra computation, and send a compact set of high-quality chunks to the generator. This guidance is most useful for teams building RAG systems over documentation, policies, support content, or technical knowledge bases where answer quality depends on selecting the right passage from many similar options. Re-ranking can improve grounded answers, but it should be tuned and measured against latency, cost, and the actual quality of user-facing responses.
Watch this video to learn more