When you change embedding models, the vectors created by the old model usually cannot be treated as interchangeable with vectors created by the new model. Each embedding model maps text, images, code, or other content into its own vector space, with its own dimensions, distances, and learned meaning patterns. A safe migration normally means re-embedding the source content, building a new index, validating retrieval quality, and shifting traffic in a controlled way instead of replacing the model in place.
This guide explains why model changes invalidate old vectors, how to plan a full re-embed, how a dual-index migration works, and how to avoid downtime while moving production retrieval systems to a new embedding model. By the end, you should understand the operational steps behind a model migration and the tradeoffs that matter for AI database reliability.
Why Changing Embedding Models Invalidates Old Vectors
An embedding model is not just a tool that produces numbers. It defines the coordinate system in which those numbers have meaning. When a model turns a chunk of text into a vector, nearby points are meant to represent items that the model sees as semantically similar. A different model may use a different training method, tokenizer, dimension count, normalization behavior, language coverage, or objective function. Even when two models are designed for the same task, they usually arrange meaning differently.
This is why old vectors become unsafe to search with new query vectors. If documents were embedded with one model and the search query is embedded with another, the distance calculation may still produce a number, but that number no longer has the same meaning. The index may return irrelevant results, miss strong matches, or appear to work only for easy cases while quietly degrading on harder queries.
The most obvious incompatibility happens when the old and new models produce vectors with different dimensions. For example, one model might produce 768-dimensional vectors while another produces 1,024-dimensional vectors. In that case, the database often cannot compare them at all. But even if the dimensions match, the vectors can still be incompatible because the two models learned different internal representations.
A model change can also affect the assumptions around similarity metrics. Some systems use cosine similarity, some use dot product, and some use distance-based scoring. If a model expects normalized vectors and the pipeline stores unnormalized vectors, relevance can shift. If a new model is better for multilingual content, code retrieval, long context, or domain-specific language, that improvement only helps after the content and queries are embedded in the same new space.
Once this is clear, the migration question becomes practical rather than theoretical. The issue is not only whether the new model is better. The issue is how to rebuild enough of the retrieval system so that every comparison is made inside one consistent vector space.
What Has To Be Re-embedded
A full re-embed usually starts with the original source content, not the old vectors. The old vectors are the output of the previous model, so they are not a reliable input for the new model. The migration process should return to the stored documents, chunks, records, metadata, and any preprocessing rules that produced the searchable units in the first place.
In a retrieval system, the unit that gets embedded is often a chunk rather than a full document. That means re-embedding is tied to chunking strategy. If the old chunks are still useful, the migration can reuse them and simply create new vectors for each chunk. If the model change is part of a broader retrieval upgrade, it may be a good time to revisit chunk size, overlap, field selection, metadata extraction, and text cleaning rules. That can improve quality, but it also makes validation harder because more than one variable changes at once.
The minimum set of data to preserve for a controlled migration includes the stable record identifier, the raw or normalized text used for embedding, the chunk identifier, metadata used for filters, and the embedding model version. Without these fields, it becomes harder to reproduce vectors, compare old and new results, or roll back safely if the new index underperforms.
It is also important to re-embed newly created or updated content during the migration window. If the existing corpus is being reprocessed while users continue adding data, the system needs a plan for writes. Otherwise, the new index may be complete for yesterday’s data but missing today’s updates when it goes live.
After identifying what must be re-embedded, the next question is how to run the work without overwhelming the embedding provider, the AI database, or the application that depends on search.
Planning A Full Re-embed
A full re-embed is a data migration, a model migration, and a search migration at the same time. Treating it as a background script is risky because the job may involve millions of chunks, rate limits, retries, index rebuilds, cost controls, and quality checks. A good plan defines the target model, the target index, the migration order, the validation process, and the cutover strategy before large-scale processing begins.
The first planning step is to freeze the embedding contract. That contract should include the model name, model version if available, vector dimension, similarity metric, input formatting rules, chunking rules, metadata schema, and any filtering behavior that affects retrieval. If the model supports configurable dimensions or different input modes, those choices should be recorded as part of the index version.
The second step is to estimate the workload. Count the number of records and chunks, the total tokens or characters to embed, expected throughput, provider limits, storage growth, and index build time. This helps avoid a migration that begins confidently and then stalls because the new index needs more disk, more memory, or more time than expected.
The third step is to make the job resumable. Each chunk should have a stable identifier and a migration status, such as pending, embedded, indexed, failed, or verified. Failed items should be retried with backoff, and persistent failures should be logged for review. A resumable job prevents a network error or rate-limit event from forcing the entire corpus to start over.
The fourth step is to validate retrieval quality before cutover. This can include a set of known user queries, expected documents, judged relevance pairs, click or conversion signals, and manual review for important workflows. The goal is not to prove that every result is perfect. The goal is to make sure the new index is at least good enough for production and that any tradeoffs are understood.
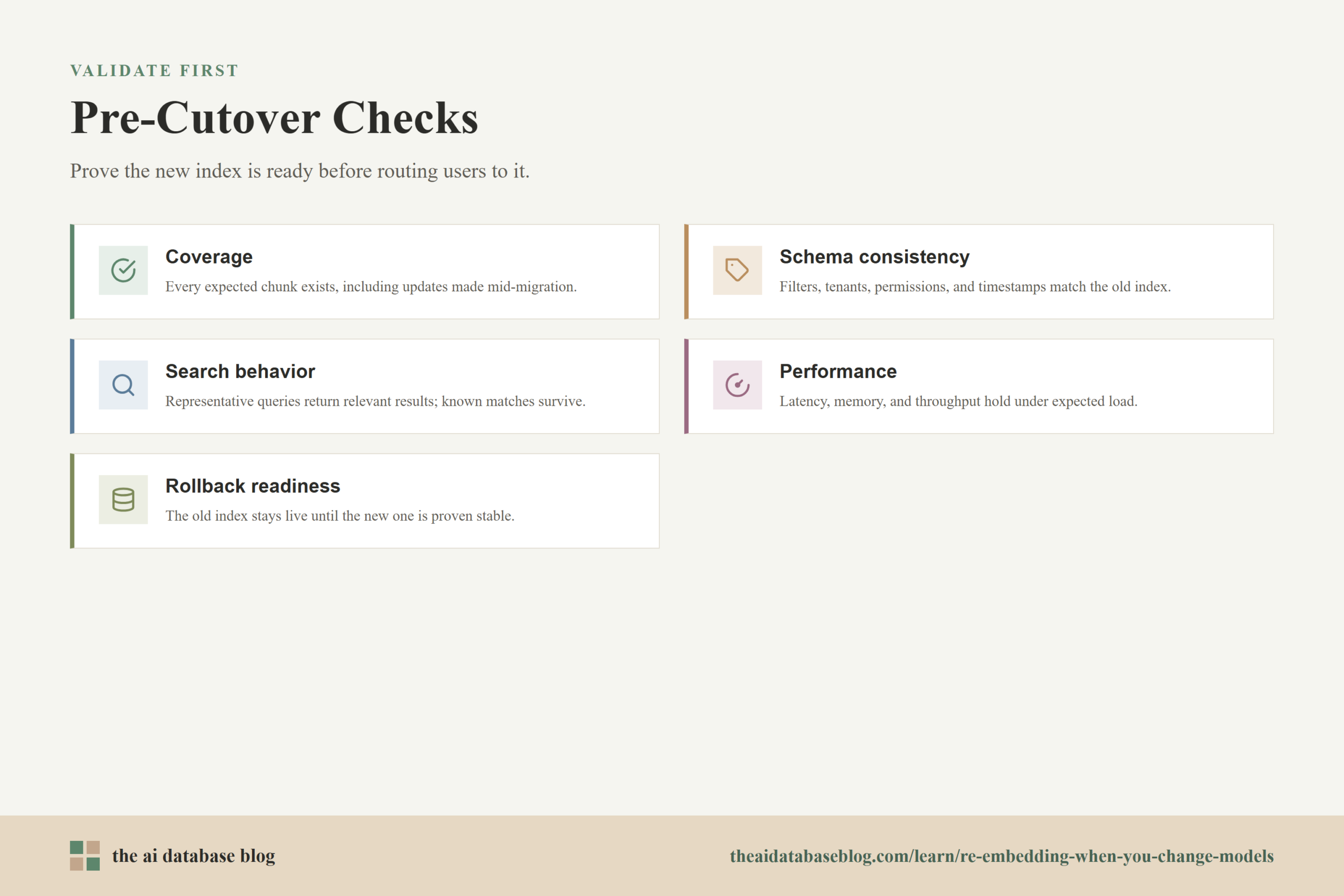
A practical re-embed plan often includes these checks:
- Coverage: every expected document or chunk exists in the new index, including recent updates created during the migration.
- Schema consistency: metadata filters, tenant identifiers, access controls, timestamps, and source references match the old index.
- Search behavior: representative queries return relevant results, and important known matches are not lost.
- Performance: latency, memory use, indexing time, and query throughput are acceptable under expected load.
- Rollback readiness: the old index remains available until the new one is proven stable.
Planning the full re-embed gives the migration a reliable foundation, but it does not by itself prevent downtime. For production systems, the safer pattern is usually to run old and new retrieval paths side by side until the new one is ready.

How Dual-index Migration Works
A dual-index migration keeps the old index available while building a new index with the new embedding model. This is often the cleanest way to avoid service interruption because production reads can continue using the old index while the new index is being populated, checked, and tuned. The application does not need to expose incomplete results from the new model before the migration is ready.
The old index and new index should be treated as separate retrieval systems, even if they live in the same AI database. Each index should have its own embedding model version, vector dimension, similarity settings, and lifecycle state. Mixing old and new vectors in one searchable vector space is usually the mistake this migration is meant to avoid.
A common dual-index pattern has four phases. First, create the new index using the new embedding configuration. Second, backfill existing chunks into the new index in batches. Third, keep new writes synchronized so that fresh content lands in both the old and new retrieval paths during the migration. Fourth, switch reads to the new index after validation passes.
The write strategy matters because migrations often take time. If content changes while the backfill is running, the system needs either dual writes, a change log, or a catch-up job. Dual writes send new or updated records to both indexes from the moment the migration begins. A change log records updates and replays them into the new index before cutover. A catch-up job compares source records against the new index and fills any gaps. The best choice depends on write volume and operational complexity.
Dual-index migration also makes comparison easier. The application or evaluation pipeline can run the same query against both indexes and compare result sets, scores, latency, and downstream answer quality. In retrieval-augmented generation systems, this can reveal whether the new embedding model improves context selection or merely changes the ranking in ways that need prompt, chunking, or reranking adjustments.
Once the new index is complete and validated, the remaining risk is the cutover itself. Avoiding downtime depends on making that switch gradual, observable, and reversible.
Avoiding Downtime During Cutover
Downtime usually happens when a migration forces the application to wait for indexing, exposes a partially built index, or removes the old retrieval path too early. The safer approach is to make the new index production-ready before routing users to it. Then cutover becomes a routing change rather than a live rebuild.
A simple cutover uses a configuration flag that tells the application which index to query. More cautious teams use a gradual rollout. For example, internal users might test the new index first, then a small percentage of traffic, then a larger percentage after monitoring confirms stable behavior. This approach is especially useful when retrieval quality affects customer-facing answers, recommendations, support workflows, or compliance-sensitive content access.
During cutover, monitor both technical and relevance signals. Technical signals include query latency, error rate, timeout rate, index memory, and database load. Relevance signals include click-through behavior, user feedback, judged query performance, answer groundedness, and cases where the generator cannot find enough context. If the new model changes ranking behavior, the retrieval layer may need adjusted filters, hybrid search weights, or reranker settings.
Rollback should be boring. The old index should remain intact until the new index has handled real production traffic successfully for a defined period. If errors spike or retrieval quality drops, the application should be able to route reads back to the old index without waiting for another data operation. Only after the new index is stable should the old one be archived or deleted.
For applications with strict freshness requirements, cutover should also include a final consistency check. Compare recent source records, update timestamps, and deleted records against the new index. A migration that preserves old content but misses recent deletes or permission changes can create correctness and access-control problems even if the embedding quality is strong.
Cutover planning reduces operational risk, but model migration is also a chance to improve the system’s long-term maintainability. The best migrations leave behind clearer versioning and easier future upgrades.
Versioning Your Embeddings And Indexes
Every production AI database should make embedding versioning explicit. The version should be visible in metadata, index names, deployment configuration, evaluation reports, and runbooks. This keeps future teams from guessing which model created a vector or whether two indexes can be compared safely.
Useful version fields include the embedding model identifier, model version or release date when available, vector dimension, chunking version, preprocessing version, similarity metric, and index build date. If the system uses hybrid search, it can also help to version keyword indexing settings and ranking weights. If the system uses reranking, record that separately because reranking can mask or amplify embedding changes.
Versioning also supports selective re-embedding. If only one data source changes, the system can reprocess that source without touching the whole corpus. If only metadata changes, vectors may not need to be regenerated at all. If the chunking rule changes, however, re-embedding is usually needed because the embedded text units have changed.
Good versioning makes migrations less mysterious. It turns the question from “which vectors are in this database?” into a concrete answer: “this index contains chunks generated by preprocessing version 3, embedded with model version 2, using this dimension and similarity metric.” That clarity helps with debugging, evaluation, cost planning, and rollback.
With versioning in place, the last important question is how to decide whether the new model actually deserves the migration effort.
When A New Embedding Model Is Worth The Migration
A newer embedding model is not automatically better for every retrieval system. It may improve multilingual search, domain-specific matching, long-document understanding, or cost efficiency, but it may also change rankings in ways that disrupt existing workflows. The decision should be based on measured retrieval quality and operational impact, not only on model release notes.
Start with a representative evaluation set. Include common queries, rare but important queries, ambiguous queries, and queries that previously failed. Compare old and new indexes using the same source content when possible. Look at top result relevance, recall of expected documents, diversity, latency, cost, and downstream answer quality if the index feeds a generation system.
It is also worth testing hybrid search behavior. Many AI database applications combine vector search with keyword search and metadata filters. A new embedding model may improve semantic matching while still needing keyword constraints for exact names, identifiers, error codes, legal clauses, or product SKUs. The best retrieval system is often the one that combines the model’s semantic strengths with structured filtering and exact-match signals.
Cost should include more than the embedding call itself. A migration may require temporary duplicate storage, additional index memory, background processing capacity, evaluation time, and monitoring. If the corpus is large, a full re-embed can be a meaningful infrastructure project. That does not mean it should be avoided, but it should be planned as production work.
When the new model provides a measurable retrieval gain, better coverage for the application’s content, lower long-term cost, or continued support after an old model is deprecated, re-embedding is often justified. When the gain is small or unclear, it may be better to run a pilot index, improve chunking or metadata first, or use reranking before committing to a full migration.
FAQs
1. Do I always need to re-embed when I change embedding models?
In most production retrieval systems, yes. A different embedding model usually creates a different vector space, so old document vectors and new query vectors should not be compared as if they were compatible. Even if the vector dimensions are the same, the meaning of the coordinates can differ enough to hurt relevance.
2. Can I keep old vectors if the new model has the same dimension?
The same dimension is not enough to guarantee compatibility. Two models can both produce vectors of the same length while arranging semantic meaning differently. Dimension compatibility may allow the database to store or compare the vectors, but it does not make the comparison meaningful.
3. Should I re-chunk documents during a model migration?
Re-chunking is optional, but it changes the migration scope. If you reuse the old chunks, you isolate the effect of the new embedding model and make comparison easier. If you also change chunking, you may improve retrieval quality, but you should evaluate the new system as a broader retrieval redesign rather than a simple model swap.
4. What is the safest way to avoid downtime?
The safest common approach is to build a new index in parallel while the old index continues serving production traffic. Keep new writes synchronized, validate the new index, then switch reads gradually or through a reversible configuration change. Keep the old index available until the new one proves stable.
5. How do I know the new embedding model is better?
Use a representative evaluation set and compare the old and new indexes on real retrieval tasks. Look at whether expected documents appear in the top results, whether irrelevant matches decrease, whether latency and cost remain acceptable, and whether downstream generated answers become more accurate or better grounded.
6. Can I migrate only part of the corpus?
You can migrate part of the corpus if the application keeps the vector spaces separate and queries them deliberately. For example, one index can serve migrated content while another serves legacy content. What you should avoid is mixing old-model and new-model vectors in one vector space and treating their scores as directly comparable.
Takeaway
Changing embedding models is a full retrieval migration because the new model changes the vector space that search depends on. The safest path is to preserve the source chunks, create a new index, re-embed in batches, keep writes synchronized, validate relevance, and cut over only when the new index is complete and reversible. This guidance is most useful for teams running AI databases, semantic search, or retrieval-augmented generation systems where search quality and uptime both matter, especially when upgrading models for better accuracy, broader language support, lower cost, or continued long-term maintainability.