Namespaces, collections, and partitions are all ways to organize data in AI databases, but they operate at different levels. A collection is usually the main container for vectors, metadata, and indexing rules. A namespace is usually a logical boundary inside a larger index or collection, often used to separate tenants, projects, or environments. A partition is usually a smaller segment of data used to narrow search, route queries, improve isolation, or distribute storage and compute. The exact wording changes across systems, so the safest way to understand these concepts is to ask what each abstraction controls: schema, visibility, routing, physical placement, or query performance.
This guide explains how namespaces, collections, and partitions differ, how the same idea may appear under different names in different AI database systems, and how these structures affect multi-tenancy, data organization, search relevance, and performance. By the end, you should be able to choose a sensible organization model for retrieval-augmented generation, semantic search, recommendations, and other applications that rely on embeddings and metadata-aware retrieval.
Why These Terms Matter in AI Databases
AI databases store more than raw vectors. They usually store embeddings, object identifiers, text chunks, document metadata, access-control attributes, timestamps, and indexes that make similarity search practical at production scale. The way this data is grouped determines how easy it is to query, secure, update, evaluate, and operate the system over time.
The difficulty is that AI database terminology is not fully standardized. One system may use the word namespace for what another system treats as a tenant boundary. One system may use collection as the primary schema container, while another may use index for a similar role. Partition may mean a user-defined subset of records, an automatic shard, a hash-routed segment, or a physical unit that can be moved across nodes.
For application builders, the naming matters less than the behavior. When you design the storage layer for an AI application, you need to know whether a grouping choice changes the embedding model, distance metric, metadata schema, access rules, search scope, storage layout, or operational cost. Those are the practical differences that shape the architecture.
Once the terms are separated by function rather than by name, the model becomes easier to reason about. The next step is to define each concept in a way that works across systems while still leaving room for implementation differences.
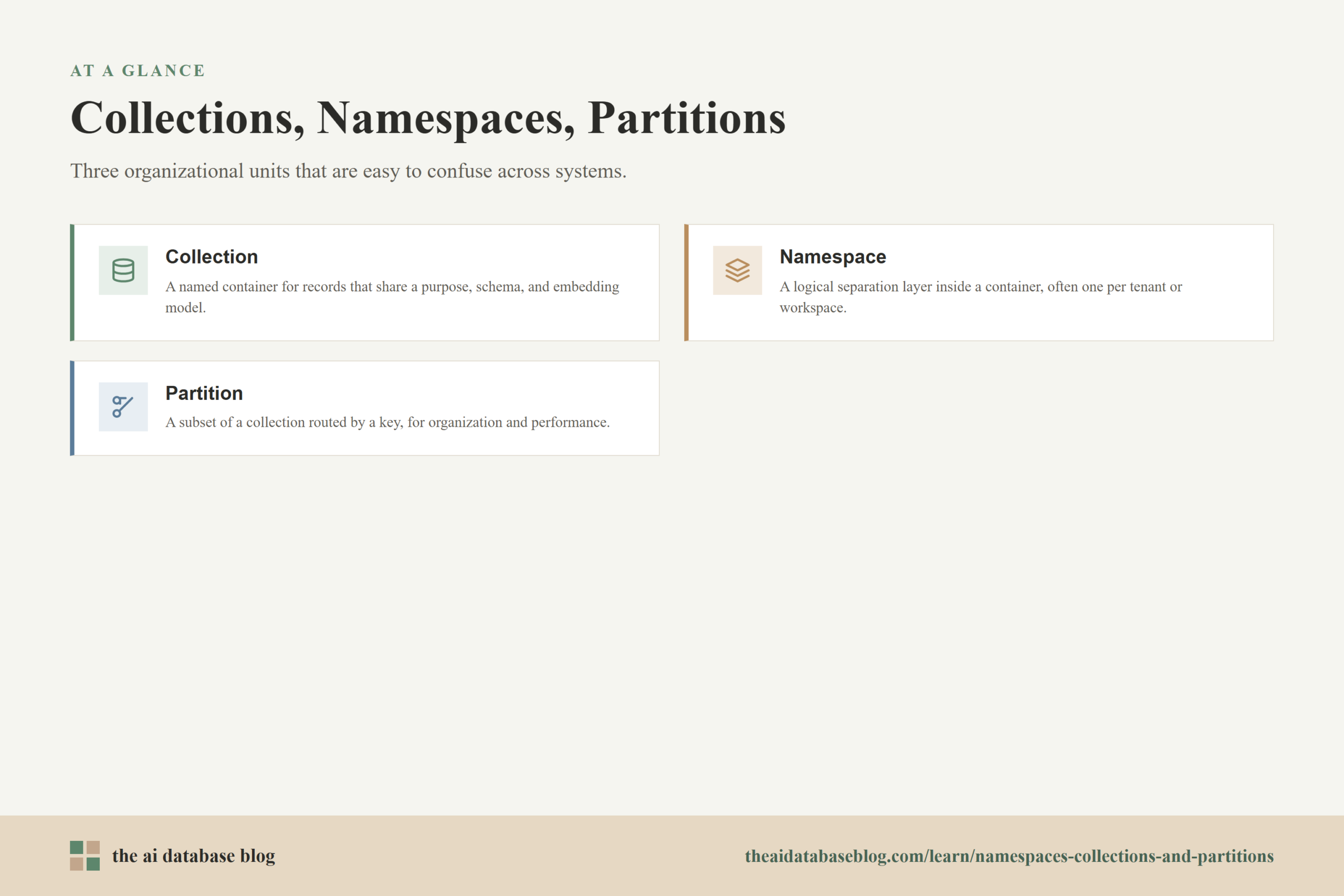
Core Definitions
The cleanest way to understand namespaces, collections, and partitions is to place them on a hierarchy from broadest data container to narrower routing or isolation mechanism. This hierarchy is not identical in every database, but it gives you a practical mental model for most vector search and AI retrieval systems.
Collections
A collection is usually a named container for a set of records that share the same broad purpose. In an AI database, each record often contains one or more vectors, metadata fields, and a reference to the original content or object. Collections commonly define or imply important rules such as vector dimensionality, similarity metric, vector index configuration, metadata indexing, and sometimes replication or sharding settings.
For example, a product search application might keep product description embeddings in one collection and support-ticket embeddings in another collection. These datasets have different source data, different query patterns, and possibly different metadata fields. Keeping them in separate collections makes the data model easier to understand and keeps search behavior predictable.
A useful rule is that collections should separate data with different meaning, schema, embedding models, or retrieval behavior. They should not automatically be used for every user, customer, project, or document folder unless the database is designed for that pattern. Too many collections can create management overhead because each collection may require separate indexes, metadata configuration, memory, storage, monitoring, and operational tuning.
Namespaces
A namespace is usually a logical separation layer inside a larger data container. It is often used to isolate data that belongs to a tenant, workspace, project, environment, or application feature while keeping those groups under the same broad index or collection configuration. A query can be scoped to a namespace so that only records from that namespace are searched or returned.
Namespaces are especially common in multi-tenant retrieval systems. If each customer has private documents, the application can write each customer’s vectors into a separate namespace and query only that namespace when the customer asks a question. This can reduce accidental data mixing and make deletion or tenant-level lifecycle operations easier.
The important limitation is that namespace does not always mean physical isolation. In some systems, namespaces are logical partitions inside a shared index. In others, they may map more strongly to isolated storage or routing units. Before relying on a namespace for security, compliance, or performance guarantees, you need to understand whether the database enforces isolation at query time, storage layout, shard placement, access-control policy, or all of these.
Partitions
A partition is a subset of data used to divide a larger collection or index into smaller pieces. Partitions can be created manually, assigned by a partition key, derived from metadata, or managed automatically by the database. They are often used to restrict queries to a subset of the search space, route data to specific storage segments, or distribute work across machines.
Partitions can serve both organizational and performance goals. A legal research system might partition records by jurisdiction, while a customer-support system might partition by tenant, region, or language. If most queries only need one partition, the database can search less data, which may improve latency and reduce compute. If partitions are distributed across nodes, they can also support horizontal scaling.
The tradeoff is that partitioning introduces design risk. Too few partitions may not reduce the search space enough. Too many partitions can fragment the index, increase overhead, and make cross-partition queries slower or more complex. Poor partition keys can also create skew, where one partition becomes much larger or hotter than the others.
These definitions overlap because systems use different names for similar ideas. The next question is how those differences appear in real architectures without getting trapped by vendor-specific vocabulary.
How the Terms Differ Across Systems
Across AI databases, the same data organization problem is solved with different abstractions. Some systems start with an index-like container and offer namespaces inside it. Some start with collections and add tenants, partitions, or payload filters. Others use database, collection, shard, and access-control layers together. This is why architecture discussions can become confusing even when everyone is describing similar needs.
One common pattern is the collection-first model. In this model, collections are the main unit of schema and retrieval configuration. You create a collection for a coherent dataset, such as document chunks embedded with the same model and searched with the same distance metric. Multi-tenancy is then handled inside that collection with tenant labels, metadata filters, tenant objects, partitions, or shards.
Another common pattern is the index-and-namespace model. In this model, the larger index defines the vector search configuration, while namespaces divide the index into logical groups. This is attractive for applications with many tenants that share the same embedding model and schema, because each tenant can be separated without creating a fully independent index for every customer.
A third pattern is the partition-key model. In this model, a field such as tenant ID, region, project ID, or category is used to route records into partitions. Queries that include the same key can search a smaller portion of the data. This approach can combine application-level organization with database-level routing, but it depends heavily on choosing a stable, high-value key.
A fourth pattern is the shard-aware model. Here, the system exposes or partially exposes the physical distribution of data. A shard may be a storage and query execution unit, while a namespace or tenant may be mapped to one or more shards. This can improve isolation for large tenants and support scaling, but it also raises operational questions about balancing, replication, promotion of large tenants, and query fan-out.
These models are not mutually exclusive. A single AI database architecture may use collections for schema, namespaces or tenant IDs for visibility, partitions for search narrowing, and shards for physical distribution. The practical design question is not which term is correct, but which layer should carry which responsibility.
How They Map to Multi-Tenancy
Multi-tenancy means one system serves multiple customers, teams, users, or workspaces while keeping their data appropriately separated. In AI databases, this is especially important because retrieved context may be fed into an AI model. A retrieval mistake can expose private content, produce an incorrect answer, or mix unrelated knowledge sources.
There are several levels of multi-tenant organization. The strongest form is separate infrastructure for each tenant, such as a separate cluster or database. This can provide strong isolation but is expensive and harder to operate at scale. A middle option is separate collections or indexes per tenant. This may be reasonable for a small number of large tenants, but it can become costly when tenant counts grow. A lighter option is a shared collection with tenant-level namespaces, partitions, or metadata filters.
Namespaces are often a good fit when many tenants share the same schema and embedding model. They let the application scope writes, reads, and deletes to a tenant-specific boundary. This keeps the number of top-level containers lower while still giving the application a clear way to separate tenant data.
Collections are often a better fit when tenants or datasets do not share the same retrieval design. If one tenant uses a different embedding model, vector dimension, similarity metric, document structure, or indexing strategy, forcing everything into one shared collection can make the system harder to reason about. In that case, separate collections may be cleaner even if they add operational overhead.
Partitions are often a good fit when tenant ID or another key is frequently present in queries. A partition key can help the database route searches to the relevant subset of data instead of filtering after searching a much larger pool. This can improve both latency and relevance, especially when most queries should never cross tenant boundaries.
Metadata filtering can support multi-tenancy, but it should be treated carefully. Filtering by tenant ID is useful, but the database must apply the filter in a way that is correct and efficient for vector search. If filtering happens too late, the system may search broadly, discard many results, and return weak matches. If filtering is indexed and applied before or during candidate generation, it can be much more effective.
After choosing a tenant isolation strategy, the next question is how to organize non-tenant data such as document types, products, languages, regions, and access-control groups. Those choices affect both developer ergonomics and retrieval quality.
How They Map to Data Organization
Data organization in an AI database should follow retrieval behavior. The goal is not just to store embeddings neatly; the goal is to make the right content easy to find, update, evaluate, and remove. Namespaces, collections, and partitions each help with this, but they are useful at different levels of the design.
Use collections for datasets that should be modeled and searched differently. If two groups of records need different vector dimensions, distance metrics, metadata indexes, retention policies, or query pipelines, they probably belong in different collections. This keeps schema decisions explicit and avoids mixing data that should not share the same retrieval behavior.
Use namespaces for logical boundaries inside a shared retrieval setup. A namespace can represent a customer, workspace, project, environment, or application domain when the underlying data model is otherwise consistent. This is especially useful when a system needs many isolated groups but does not need a separate schema for each group.
Use partitions when queries naturally target a predictable subset of the data. Good partition keys are fields that appear frequently in queries and divide data in a balanced, meaningful way. Tenant ID, region, time bucket, language, and content category can be useful in the right context. Poor partition keys are fields that are rarely queried, change often, or create one very large group and many tiny groups.
Access control deserves special attention. A namespace or partition can help narrow the search scope, but it should not be the only security mechanism unless the system explicitly supports that guarantee. Many AI applications still need application-level authorization checks, metadata constraints, or document-level permissions to ensure users only retrieve content they are allowed to see.
Good organization also supports lifecycle operations. If a tenant leaves, can you delete all of their records cleanly? If a document is reprocessed, can you replace all related chunks? If an embedding model changes, can you rebuild the affected data without disrupting unrelated workloads? These questions often matter as much as query speed.
Once the organization model is clear, performance becomes easier to reason about. The same structure that keeps data understandable can either improve search efficiency or create avoidable overhead.
Performance Characteristics
The performance impact of namespaces, collections, and partitions depends on how the database implements them. In general, each abstraction changes one or more of four things: how much data a query must consider, how indexes are built, how work is routed across storage or compute, and how much overhead the system carries for each isolated group.
Collections and Performance
Collections can improve performance when they separate genuinely different workloads. If a collection contains only records that are searched together, the vector index can be tuned for that data distribution and query pattern. Queries avoid unrelated records, metadata indexes stay focused, and operational monitoring becomes easier.
However, creating too many collections can hurt performance and manageability. Each collection may need its own indexing resources, memory, background maintenance, replication, and metadata structures. If thousands of small tenants each get a separate collection, the overhead may outweigh the benefit of isolation. The system can become harder to scale because the database is managing many small indexes instead of a smaller number of well-designed shared structures.
Namespaces and Performance
Namespaces can improve performance when they let queries search only the relevant tenant or project. A query scoped to one namespace has a smaller candidate pool than a query over all data, which can reduce latency and improve relevance. Namespaces can also make tenant-level deletion and usage measurement easier.
The exact performance profile depends on whether namespaces are implemented as independent segments, logical filters, or routing boundaries. If namespaces are lightweight labels inside a shared index, they may be easy to create but less physically isolated. If they map to separate storage or index segments, they may provide stronger isolation but carry more overhead. This is why namespace count, namespace size, and query distribution matter.
Partitions and Performance
Partitions are most helpful when they reduce query fan-out. If the application always knows that a query belongs to one tenant, region, or category, a partition key can route the query to the right subset of data. This can reduce the amount of vector search work and make metadata filtering more efficient.
Partitions can also harm performance when they are too granular or poorly balanced. If a query must search many partitions, the database may perform more coordination work than it would in a simpler layout. If one partition receives most of the traffic, it can become a hotspot. If partitions are too small, approximate nearest neighbor indexes may have less useful neighborhood structure, and recall can suffer for queries that need broader context.
Filtering, Recall, and Latency
Many AI retrieval systems combine vector search with metadata filtering. The order and implementation of filtering matter. If the database filters first or uses an indexed filter during candidate generation, it can avoid searching irrelevant records. If it retrieves vector candidates first and filters afterward, it may discard many candidates and return fewer or weaker results.
This is especially important for multi-tenant systems. A tenant filter is not just a convenience; it defines which knowledge base the answer should come from. For high-stakes retrieval, tenant scoping should be explicit in the query plan and tested as part of retrieval evaluation.
Performance is not only about speed. It also includes recall, consistency, operational cost, and the ability to grow without redesigning the data model. That makes the choice between namespace, collection, and partition a design decision rather than a naming preference.
Common Design Patterns
Most AI database applications can start from a few practical patterns. The right pattern depends on tenant count, data volume, schema variation, access-control needs, and query behavior. A good design keeps the top-level structure simple while leaving room for larger tenants or specialized workloads to move into more isolated structures later.
One Collection Per Embedding Model
This pattern uses one collection for records created with the same embedding model and vector configuration. Tenants, workspaces, document types, and permissions are represented with namespaces, metadata fields, or partitions. It works well when the data is mostly homogeneous and the main need is clean scoping.
The advantage is operational simplicity. The application has fewer collections to manage, and evaluation can focus on a consistent retrieval setup. The risk is that very large tenants or unusual workloads may eventually need stronger isolation.
One Namespace Per Tenant
This pattern places each tenant’s vectors into a separate namespace inside a shared index or collection. It works well when tenants share the same schema and embedding model but must not see each other’s data. It also makes tenant-level deletion and query scoping straightforward.
The main design question is scale. A small number of namespaces is easy to reason about, but a system with very high namespace counts should confirm that the database supports that pattern efficiently. Namespace size also matters because many tiny namespaces and a few very large namespaces can behave differently.
Partition by Tenant, Region, or Category
This pattern uses a partition key to route data and queries. It is useful when queries almost always include the same scoping field. For example, a customer-support assistant may always search within one customer account, while a multilingual knowledge base may often search within one language or region.
The advantage is that the database can avoid searching irrelevant data. The risk is that the chosen key may not match future query patterns. If users later need cross-region or cross-category search, the application may need to query multiple partitions and merge results.
Separate Collections for Different Retrieval Workloads
This pattern creates separate collections for data that should be searched differently. For example, document chunks, product records, code snippets, and conversation summaries may each deserve their own collection because they have different metadata, chunking strategies, and relevance signals.
The advantage is clarity. Each collection can be tuned for its retrieval task. The risk is that the application may need a routing layer to decide which collection to search for each user request. In more advanced systems, the application may search multiple collections and combine results with ranking or reranking.
These patterns are starting points, not rigid rules. The best architecture usually combines them in a way that matches how the application retrieves information under real user behavior.

How to Choose Between Namespaces, Collections, and Partitions
The simplest way to choose is to begin with the question the boundary is supposed to answer. If the boundary is about schema or retrieval configuration, choose a collection. If it is about logical isolation inside the same retrieval setup, choose a namespace or tenant-like grouping. If it is about routing queries to a smaller subset of data, choose a partition or partition key.
Choose a separate collection when the data has a different embedding model, vector dimension, distance metric, metadata schema, retention policy, or query workflow. This keeps incompatible retrieval assumptions apart. It also makes testing easier because each collection has a clear purpose.
Choose a namespace when many groups share the same collection-level configuration but need clean logical separation. This is common for multi-tenant RAG systems, internal workspaces, customer accounts, and development environments. A namespace should be easy for the application to include in every write, query, and delete operation.
Choose a partition when a field is both stable and frequently used to narrow search. A good partition key should reduce search cost without creating severe imbalance. It should also match the way users actually ask questions. If the application often needs global search, a partitioning strategy that forces many separate searches may create more complexity than benefit.
Avoid using these structures as substitutes for a clear authorization model. Tenant boundaries, namespaces, and partitions can support access control, but permissions should still be explicit and tested. In AI retrieval, correctness means both finding relevant content and excluding content that should not be available.
It also helps to plan for migration. A small tenant may start in a shared collection with a namespace or metadata filter. A large tenant may later move to a dedicated partition, shard, collection, or cluster. Designing tenant identifiers, document IDs, and metadata consistently from the beginning makes that migration much easier.
Practical Example for a RAG Application
Imagine a retrieval-augmented generation application that answers questions over company documents for many customer accounts. Each document is split into chunks, each chunk is embedded, and each vector record stores metadata such as tenant ID, document ID, source type, creation date, and access level.
A practical design might use one collection for all document chunks embedded with the same model. Each customer account could be represented as a namespace or tenant field. Within that collection, partitions or indexed metadata filters could narrow search by tenant ID, language, or document type. The application would always include the tenant boundary in the retrieval request before sending retrieved context to the language model.
If one customer becomes much larger than the rest, the architecture might promote that customer into a more isolated structure. Depending on the database, that could mean a dedicated shard, partition, namespace strategy, collection, or cluster. The application does not have to start with maximum isolation for every tenant, but it should use stable identifiers and clean query scoping so large-tenant migration is possible.
This example shows why the three terms are best treated as design tools. Collections organize retrieval configuration, namespaces organize logical boundaries, and partitions organize query routing or data placement. Used together, they make the AI database easier to operate and safer to query.
Common Mistakes to Avoid
The most common mistake is creating a separate collection for every small tenant without checking the operational cost. This can look clean at first, but it may create too many indexes and too much management overhead. A shared collection with explicit tenant scoping is often simpler when tenants use the same schema and embedding model.
Another mistake is relying only on post-filtering for tenant isolation. If the system retrieves candidates from a broad shared index and filters afterward, it may reduce recall or return too few results. For tenant-sensitive retrieval, the tenant boundary should be part of the search scope, not an afterthought.
A third mistake is choosing a partition key based on data structure rather than query behavior. A field is not a good partition key just because it exists. It should help the database avoid unnecessary work for the queries the application actually runs.
A fourth mistake is mixing unrelated datasets in one collection because they all contain vectors. Vectors created from different models, chunking strategies, or content types may not behave well in the same retrieval space. Collections should reflect meaningful retrieval compatibility.
The final mistake is treating terminology as portable without checking system behavior. A namespace, tenant, partition, collection, index, and shard may sound similar across products, but they do not always provide the same guarantees. The right question is always what the abstraction does in that specific system.
FAQs
1. Is a namespace the same as a collection?
No. A collection is usually a higher-level container that defines the dataset and its search configuration. A namespace is usually a logical subdivision inside a collection or index. Collections are better for separating different schemas or retrieval workloads, while namespaces are better for separating tenants or projects that share the same retrieval setup.
2. Is a partition the same as a shard?
Not always. A partition is often a logical or query-facing subdivision of data, while a shard is often a physical storage or execution unit. Some systems map partitions to shards, but others keep them separate. If performance or isolation depends on the distinction, check whether the system routes queries, stores data, and balances load at the partition level or the shard level.
3. Should every tenant get a separate collection?
Usually not when tenants share the same schema, embedding model, and retrieval behavior. Separate collections can be useful for a small number of large or highly regulated tenants, but they may create unnecessary overhead for many small tenants. Namespaces, tenant fields, or partitions are often more practical for shared multi-tenant retrieval.
4. Can metadata filters replace namespaces or partitions?
Metadata filters can help separate and narrow data, but they are not always a direct replacement. The key question is how the database applies the filter. If the filter is indexed and used during search, it may perform well. If the system searches broadly and filters afterward, latency and recall may suffer. For tenant isolation, filters should be explicit, reliable, and tested.
5. What is the best partition key for an AI database?
The best partition key is a stable field that appears frequently in queries and divides data into useful, reasonably balanced groups. Tenant ID is often a strong candidate in multi-tenant systems. Region, language, time bucket, or content category can also work when queries commonly use those constraints. A weak partition key is one that rarely appears in queries or creates severe data skew.
6. How do these choices affect RAG quality?
They affect RAG quality by controlling which documents are eligible for retrieval. A well-scoped collection, namespace, or partition helps the system search the right knowledge base and avoid irrelevant or unauthorized context. Poor organization can mix unrelated content, weaken relevance, increase latency, and make generated answers less trustworthy.
Takeaway
Namespaces, collections, and partitions are different tools for organizing AI database data: collections define coherent retrieval containers, namespaces create logical boundaries inside shared structures, and partitions narrow or route data for isolation and performance. This guidance is most useful for teams designing RAG systems, semantic search applications, recommendation systems, or multi-tenant AI products where the same database must stay understandable, secure, and fast as data grows. A practical design starts with collections for distinct retrieval workloads, uses namespaces or tenant fields for shared multi-tenancy, and adds partitions when query patterns justify more targeted routing.