Multi-tenant security is the practice of making sure each customer, workspace, account, or organization can access only its own data, even when many tenants share the same application, database, index, storage layer, or retrieval pipeline. In AI database systems, this is especially important because leakage can happen through ordinary queries, vector search, hybrid search, metadata filters, generated answers, logs, background jobs, or administrative tools. Strong isolation depends on tenant scoping at every access path, database-level controls such as row-level security where appropriate, clear decisions about logical versus physical separation, and audit trails that can prove what was accessed, by whom, and under which tenant context.
This guide explains how to design multi-tenant AI database systems that reduce the risk of cross-tenant leakage. It covers how leaks happen, how tenant scoping should be enforced across application and database layers, how row-level security compares with physical isolation, and what audit evidence teams should collect when they operate shared retrieval systems, vector indexes, and knowledge stores.
Why Multi-Tenant Isolation Matters in AI Database Systems
Multi-tenancy lets one platform serve many customers through shared infrastructure. That shared model is efficient, but it also creates a basic security promise: one tenant should never be able to see, retrieve, infer, modify, or delete another tenant’s data. In a conventional application, the main risk is often a missing authorization check on a record lookup. In an AI database system, the same risk exists, but it can appear in more places because retrieval is often indirect.
An AI application may store raw documents, chunks, embeddings, metadata, access rules, user feedback, prompts, generated responses, and evaluation traces. A user may not request a specific row by ID; they may ask a question, trigger semantic search, and receive content that came from whichever vectors ranked highest. If tenant identity is not part of the retrieval boundary, the system can return information from another tenant even when the user never guessed an object identifier.
This is why tenant isolation should be treated as a data architecture requirement, not only an application feature. Authentication proves who the user is. Tenant isolation proves which customer boundary applies to the request. Authorization decides what that user can do inside that boundary. All three are needed, and they need to survive normal software mistakes such as a forgotten filter, an overly broad query, a background job using a privileged role, or a debugging endpoint left behind during development.
Once tenant isolation is understood as a full data path concern, the next question is where leakage actually occurs. The most useful security designs start by identifying those failure paths before choosing controls.
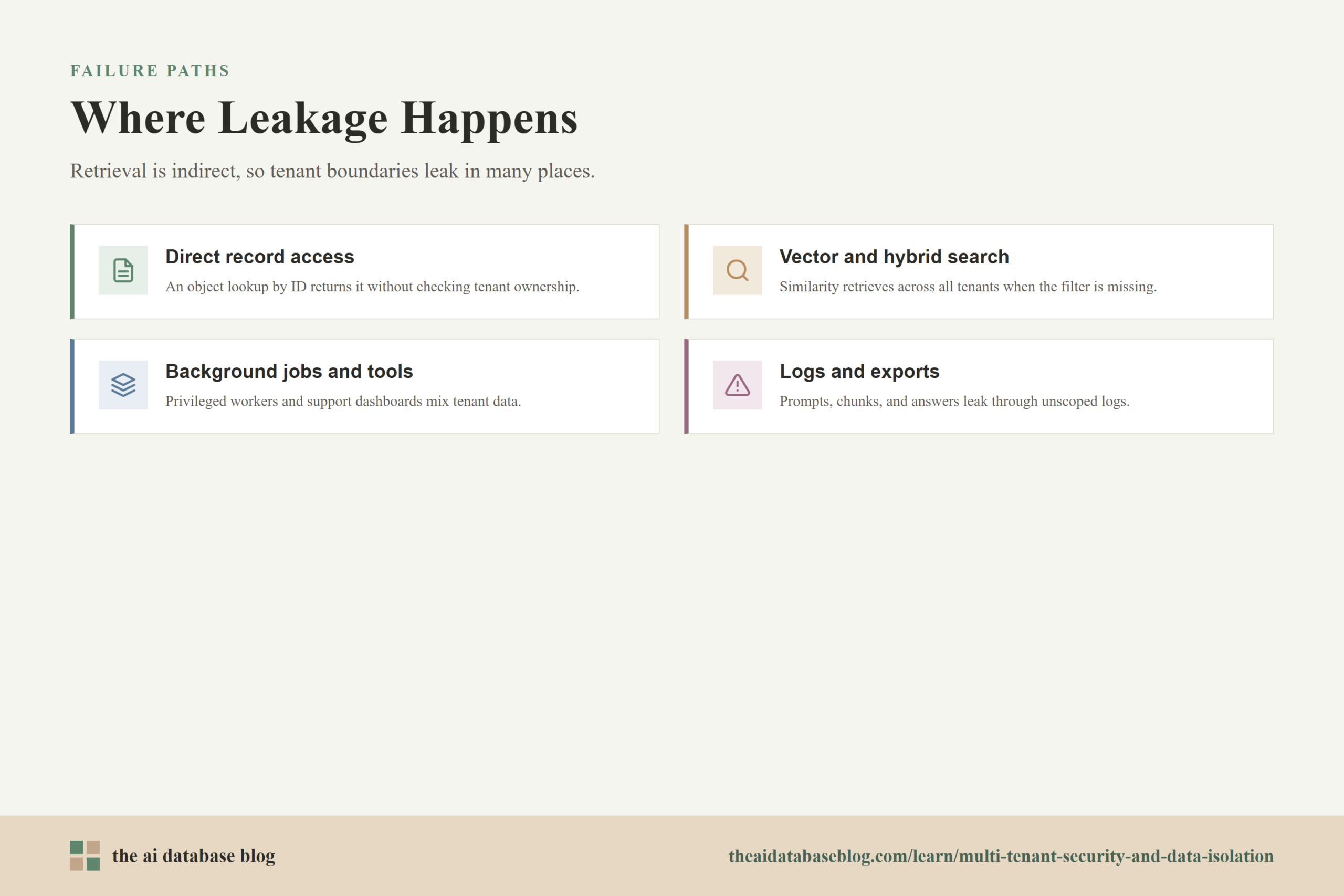
How Cross-Tenant Leakage Happens
Cross-tenant leakage happens when data from one tenant crosses into another tenant’s view, result set, index, answer, export, log, or operational workflow. The cause is usually not a single dramatic failure. More often, it is a missing tenant predicate, an authorization rule that checks user identity but not tenant membership, or an internal service that has broader database access than the request should allow.
In API security terms, many cross-tenant failures are a form of broken object-level authorization. A request may be authenticated, but the system does not verify that the requested object belongs to the tenant associated with the current user or workspace. The same pattern applies to AI retrieval. A query may be valid, but the retrieval layer may search across all embeddings instead of only embeddings owned by the current tenant.
Direct Record Access
The simplest leak happens when a user or service requests an object by ID and the application returns it without checking tenant ownership. This can affect documents, files, projects, conversations, collections, indexes, connectors, API keys, and evaluation datasets. In multi-tenant systems, every object lookup should be treated as a tenant-scoped lookup, not a global lookup.
Vector and Hybrid Search
Vector search introduces another path for leakage because retrieval may be based on similarity rather than exact identifiers. If embeddings for many tenants live in the same collection, the query must include a tenant filter that is enforced before or during retrieval, not merely after results are generated. Post-filtering is sometimes useful for relevance tuning, but it should not be the only security control if unauthorized candidates can already influence ranking, scoring, reranking, or generated output.
Hybrid search can widen the problem because keyword search, vector search, metadata filtering, and reranking may each have their own query path. A secure design ensures the same tenant boundary applies consistently across all retrieval modes. If semantic search is scoped but keyword search is not, the system is still vulnerable.
Background Jobs and Administrative Tools
Data leaks can also come from non-user-facing paths. Indexing workers, migration scripts, analytics jobs, support dashboards, test harnesses, and export tools often run with elevated permissions. If these paths are not tenant-aware, they can mix records during ingestion, write embeddings into the wrong collection, expose another tenant’s data to support staff, or produce aggregate reports that contain tenant-specific details.
These leakage paths show why tenant scoping cannot be an informal convention. It needs to be enforced through data models, query construction, database permissions, and runtime checks that make unsafe access difficult to perform by accident.
Enforcing Tenant Scoping at the Application Layer
Tenant scoping starts with a reliable tenant context. Every request should resolve to a tenant identifier through a trusted source such as a verified session, token claim, organization membership record, or service account mapping. The application should not accept tenant identity blindly from a user-controlled parameter unless that parameter is checked against the authenticated user’s allowed memberships.
Once the tenant context is established, the application should carry it through the full request lifecycle. That includes API handlers, query builders, retrieval calls, background tasks, event handlers, cache keys, object storage paths, and audit events. A common failure is to scope the first database query correctly but lose tenant context in a downstream call, especially when a retrieval service, search service, or worker queue is separated from the main application.
Make Tenant Identity Part of the Data Model
Most shared-data multi-tenant systems need a tenant identifier on tenant-owned records. In an AI database, that may include documents, chunks, embeddings, vector collection entries, metadata records, conversations, generated answers, feedback events, and connector sync states. The tenant field should be required for data that belongs to a tenant, and the system should reject writes that do not have a valid tenant association.
Tenant identity should also appear in relationships. For example, if a chunk belongs to a document, and the document belongs to a tenant, the system should prevent a chunk from being attached to a document from another tenant. These integrity rules matter because retrieval systems often operate on derived data. If the derived data is tenant-confused, retrieval will be tenant-confused too.
Scope Every Query by Default
The safest application pattern is to make tenant scoping the default behavior of the data access layer. Instead of asking developers to remember a tenant filter every time, shared query helpers should require tenant context and automatically include it in reads, writes, updates, deletes, and search requests. Raw queries should be rare, reviewed carefully, and tested for tenant boundaries.
For vector and hybrid search, the tenant filter should be part of the retrieval request itself. The system should not retrieve globally and then remove unauthorized results after the fact. A tenant-scoped retrieval call should include tenant metadata filters, collection boundaries, namespace boundaries, or database policies that ensure only eligible tenant data can become a candidate result.
Separate Authentication, Tenant Membership, and Authorization
A user can be authenticated and still not be authorized for a specific tenant. A user can belong to a tenant and still lack permission for a sensitive document, project, connector, or administrative action. Strong multi-tenant systems separate these checks clearly: identity establishes the user, membership establishes the tenant boundary, and authorization establishes what the user can access inside that boundary.
This distinction is especially important for AI applications that support multiple workspaces, shared projects, external collaborators, or service accounts. The retrieval layer should receive not only a user ID, but also the tenant and policy context needed to decide which data can be searched.
Application-level tenant scoping is necessary, but it should not be the only protection. The next layer is database-level enforcement, which can catch mistakes that slip through application code.
Using Row-Level Security as Defense in Depth
Row-level security, often shortened to RLS, is a database feature that restricts which rows a role can read or modify based on a policy. In a multi-tenant design, an RLS policy can require that each query only sees rows whose tenant identifier matches the current tenant context. This moves part of the isolation rule into the database engine, where it can protect against missed filters in application queries.
RLS is most commonly discussed in relational databases, but the principle is broader: security rules should be enforced as close to the data as practical. If a table, collection, index, or storage system supports policy enforcement, tenant isolation becomes less dependent on every caller doing the right thing manually.
What RLS Protects Against
RLS can reduce the blast radius of common mistakes. If a developer forgets a tenant condition in a query, the database policy can still prevent rows from other tenants from being returned. If an update statement is too broad, the policy can limit which rows are eligible for modification. If a service uses a shared application role, the policy can use session context to decide which tenant is active for that request.
For AI databases that store relational metadata around vectors, RLS can protect source documents, chunk records, permissions, collection metadata, and retrieval logs. It is particularly useful when the relational metadata determines which vector records are eligible for retrieval.
What RLS Does Not Automatically Solve
RLS is not a complete authorization system by itself. It does not decide which users belong to which tenants unless that information is modeled and passed correctly. It does not protect paths that bypass the database policy, such as superuser access, privileged maintenance roles, unsafe security-definer functions, external object storage, or vector indexes that are queried outside the protected relational path.
RLS also needs careful operational design. Database owners and privileged roles may bypass policies unless the system is configured to force row-level security where appropriate. Connection pools must set and clear tenant context safely so one request cannot inherit another request’s tenant. Indexes should support the tenant predicate so security checks do not create avoidable performance problems.
Practical RLS Design Rules
A practical RLS design starts with simple, testable policies. For tenant-owned tables, the policy should usually compare the row’s tenant identifier to the tenant context set for the current session or transaction. Write policies should check not only which existing rows can be modified, but also whether new or updated rows are allowed to carry the tenant identifier being written.
Teams should test RLS with both allowed and forbidden tenants. The tests should include reads, inserts, updates, deletes, joins, views, stored procedures, background workers, and migration paths. A policy that works for a simple select query but fails through a function or maintenance role is not enough for production isolation.
RLS is strongest when it complements, rather than replaces, application authorization. The application still needs to know who the user is, what tenant they are acting in, and what permissions they have. The database policy provides an additional guardrail if the application makes a mistake.
RLS is one point on the isolation spectrum. Some tenants, workloads, or regulatory environments need stronger separation than shared rows in a shared database can provide.
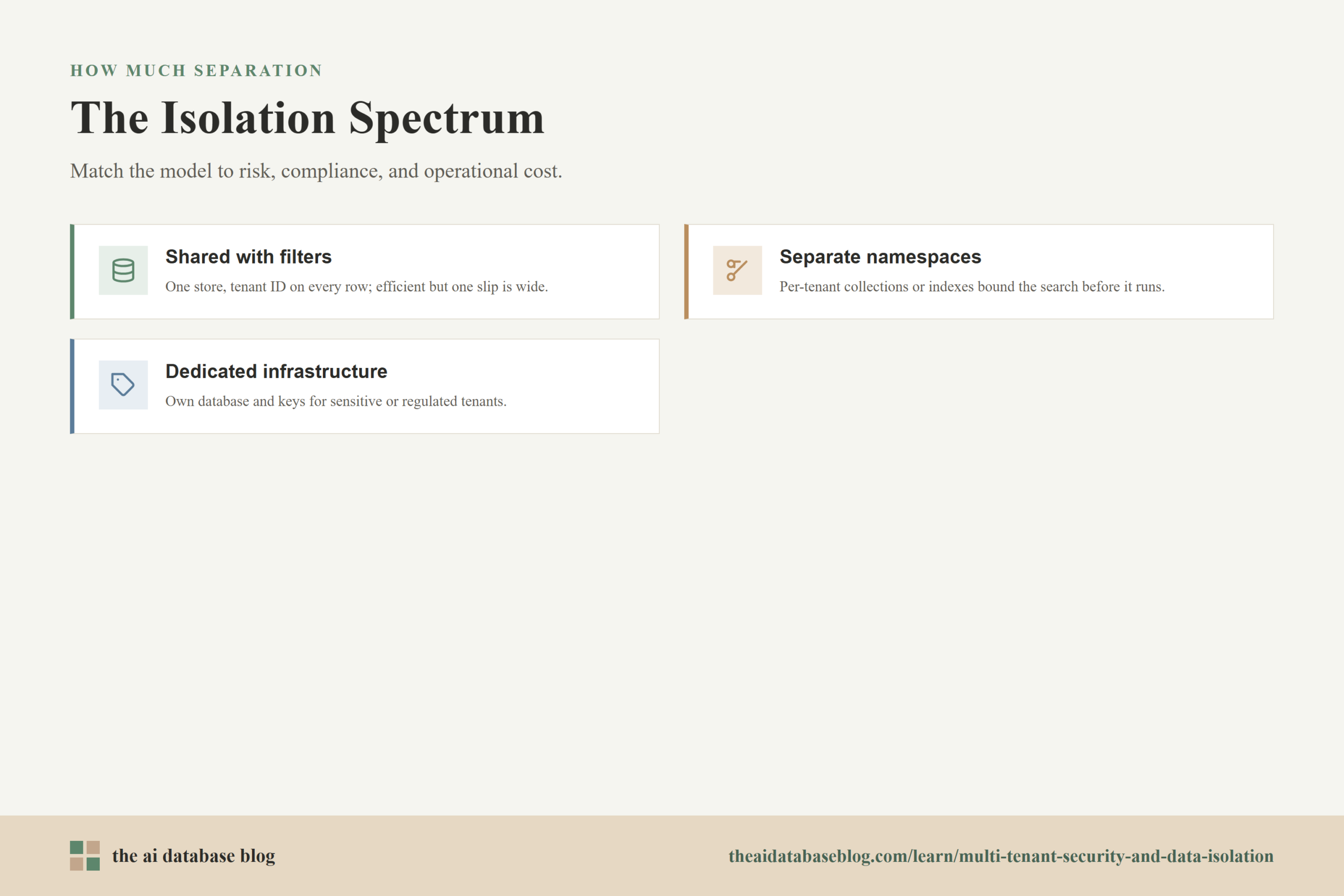
Logical Isolation Versus Physical Isolation
Multi-tenant systems can isolate data in several ways. Logical isolation usually means tenants share infrastructure but are separated by tenant identifiers, policies, schemas, namespaces, or collections. Physical isolation means each tenant has more dedicated infrastructure, such as a separate database, separate index, separate storage bucket, separate encryption keys, or even separate compute environments.
There is no universally best model. The right choice depends on risk, customer expectations, compliance requirements, operational complexity, cost, performance, and scale. AI database systems often mix isolation models. A platform might use shared application services, separate vector namespaces, tenant-scoped relational rows, and dedicated storage or indexes for high-risk tenants.
Shared Database with Tenant Filters
A shared database with tenant filters is operationally efficient and common in early and mid-stage systems. It can work well when the tenant identifier is mandatory, queries are scoped by default, RLS or equivalent database policies are enabled, and tests cover cross-tenant access. The main risk is that a single missed control can affect many tenants because data lives in the same logical space.
This model is often appropriate for lower-risk workloads, small to medium tenants, and systems where the team has mature authorization practices. It becomes less attractive when customers require strict separation, when data sensitivity is high, or when noisy-neighbor performance problems become difficult to control.
Separate Schemas, Namespaces, Collections, or Indexes
A middle-ground model separates tenants into different schemas, namespaces, collections, or indexes while keeping them on shared infrastructure. This can reduce the chance of accidental search across tenants because the retrieval path is bounded before the query is executed. It can also make tenant-specific backups, migrations, and deletion workflows easier than a fully shared table or collection.
The tradeoff is operational complexity. More schemas, collections, or indexes mean more objects to provision, monitor, migrate, and tune. In vector search systems, too many small indexes may also affect performance or resource efficiency. The design should account for tenant count, data volume, query patterns, and lifecycle operations before choosing this model.
Dedicated Databases or Infrastructure
Physical isolation gives each tenant its own database or infrastructure boundary. This model can provide stronger security separation, clearer compliance evidence, simpler tenant-level backup and deletion, and better performance isolation for large customers. It is often used for high-value tenants, regulated data, sensitive internal knowledge bases, or contractual commitments that require dedicated environments.
The tradeoff is cost and complexity. Dedicated infrastructure requires provisioning, monitoring, migrations, capacity planning, incident response, and upgrades across more environments. It can be the right choice, but teams should choose it deliberately rather than assuming it removes the need for authorization. Even with physical isolation, users inside the tenant still need role checks, document permissions, audit logs, and secure retrieval rules.
The isolation model sets the outer boundary, but day-to-day safety still depends on operational controls. That is where auditing, logging, and evidence become important.
Audit Considerations for Multi-Tenant AI Databases
Auditability is the ability to reconstruct what happened in the system and prove that tenant boundaries were enforced. For multi-tenant AI database systems, audit logs should cover more than login events and administrative actions. They should capture data access, retrieval decisions, policy decisions, configuration changes, index operations, and exceptional access paths such as support tooling.
Good audit logs help with security investigations, compliance reviews, customer trust, and engineering diagnosis. They also make isolation controls testable. If a system cannot show which tenant context was used for a query, it will be harder to prove that the query was properly scoped.
What to Capture
At minimum, audit events should include the actor, tenant, action, target resource, timestamp, request source, and outcome. For AI retrieval, the event should also record the collection, namespace, index, or filter context used for retrieval. The goal is not to store sensitive prompt or document content unnecessarily, but to preserve enough structured evidence to understand whether access was allowed, denied, or mis-scoped.
Important audit event types include tenant membership changes, role changes, document ingestion, chunk creation, embedding writes, vector index updates, search requests, generated answer access, exports, deletes, administrative impersonation, support access, policy changes, failed authorization checks, and unusual cross-tenant query attempts.
Protect the Audit Trail Itself
Audit logs are sensitive because they can reveal tenant names, user behavior, document titles, query patterns, and operational details. They should be access-controlled, tamper-resistant, retained according to policy, and separated from ordinary application logs where practical. Administrative access to audit logs should itself be logged.
Teams should also avoid turning audit logs into a new leakage path. If prompts, retrieved chunks, or generated answers are logged, those logs must be tenant-scoped and protected with the same seriousness as source data. In many cases, structured metadata is safer and more useful than storing full content in every event.
Use Audits to Improve Controls
Audit data should feed security reviews and automated detection. Repeated denied access attempts, queries without tenant context, support access outside approved workflows, or retrieval requests that return unexpected tenant metadata should trigger investigation. Audit reviews should also check whether all major data paths produce events consistently.
Auditability closes the loop between design and operation. The architecture may state that every retrieval is tenant-scoped, but the audit trail should help prove that the rule is actually followed in production.
Security Checklist for Tenant-Isolated Retrieval Systems
A secure multi-tenant AI database system should make tenant isolation visible in architecture, code, data, operations, and audits. The following checklist can help teams evaluate whether their design has enough protection across the full retrieval lifecycle.
- Resolve tenant context from trusted identity. Do not trust a tenant ID supplied by the client unless it is verified against the authenticated user’s memberships.
- Require tenant ownership in the data model. Tenant-owned records, embeddings, chunks, documents, conversations, and retrieval logs should carry a valid tenant association.
- Make scoped access the default. Query builders, repository methods, vector search calls, and background jobs should require tenant context instead of treating it as optional.
- Enforce policies near the data. Use row-level security, collection namespaces, metadata filters, storage policies, or separate indexes where they fit the system’s risk profile.
- Test negative cases. Automated tests should prove that users and services cannot read, update, retrieve, export, or delete another tenant’s data.
- Control privileged paths. Administrative tools, support workflows, migrations, and service accounts should be tenant-aware and heavily logged.
- Choose isolation by risk. Use logical isolation where it is sufficient, and consider physical isolation for sensitive data, high-value tenants, strict compliance needs, or strong contractual requirements.
- Audit retrieval and access decisions. Logs should show the actor, tenant, action, target, policy context, retrieval boundary, and result of the access decision.
This checklist is useful because multi-tenant security fails most often in gaps between layers. The final step is to understand how these controls work together in practical AI database architecture.
How These Controls Work Together
The strongest multi-tenant designs use layered controls. The application establishes tenant context and authorization. The data model makes tenant ownership explicit. The database or search layer enforces tenant boundaries. The retrieval system keeps tenant filters attached to vector, keyword, and hybrid search. The audit layer records enough evidence to detect and investigate mistakes.
No single control should carry the entire security promise. Application checks are flexible but easy to forget. RLS is powerful but depends on correct roles, session context, and bypass management. Physical isolation reduces shared-data risk but increases operational overhead and still requires user-level authorization. Audit logs do not prevent leaks by themselves, but they help teams verify controls and respond quickly when something looks wrong.
For AI databases, the main design principle is simple: tenant boundaries should be applied before data becomes eligible for retrieval. If unauthorized data can enter the candidate set, influence ranking, appear in logs, or reach a generation step, the system is already too permissive. Tenant isolation should be part of the retrieval contract, not a cleanup step after retrieval has happened.
FAQs
1. What is multi-tenant data isolation?
Multi-tenant data isolation is the set of controls that keeps each tenant’s data separate from every other tenant’s data inside a shared system. In an AI database, this includes source documents, embeddings, chunks, metadata, search results, generated answers, logs, and administrative workflows.
2. Why is cross-tenant leakage especially risky in AI database systems?
Cross-tenant leakage is especially risky because AI systems often retrieve information indirectly. A user may ask a natural language question, and the system may search across embeddings, metadata, and documents to produce an answer. If retrieval is not tenant-scoped, another tenant’s data can appear in search results or generated responses without the user directly requesting that data by ID.
3. Is row-level security enough for multi-tenant isolation?
Row-level security can be a strong defense-in-depth control, but it is not enough by itself. The application still needs correct authentication, tenant membership checks, role-based authorization, safe connection handling, protected privileged roles, and secure retrieval design. RLS is best used as a database-level backstop that reduces the risk of missed tenant filters.
4. When should a system use physical isolation?
Physical isolation is useful when tenants have highly sensitive data, strict compliance requirements, large workloads, performance isolation needs, or contractual expectations for dedicated infrastructure. It can mean separate databases, indexes, storage buckets, encryption keys, or compute environments. The tradeoff is higher operational cost and complexity.
5. How should vector search be tenant-scoped?
Vector search should be scoped before or during retrieval using tenant-specific namespaces, collections, metadata filters, database policies, or dedicated indexes. The system should avoid searching globally and filtering unauthorized results only afterward, because unauthorized data may already influence ranking, reranking, logs, or generated output.
6. What should audit logs include for tenant isolation?
Audit logs should include the actor, tenant, action, target resource, timestamp, request source, policy context, retrieval boundary, and outcome. For AI database systems, logs should also cover document ingestion, embedding writes, vector index updates, search requests, generated answer access, exports, deletes, support access, and failed authorization checks.
Takeaway
Multi-tenant security in AI databases depends on making tenant boundaries explicit, enforced, and auditable across the full data path. Readers should now understand how cross-tenant leakage happens, why tenant scoping must apply to vector and hybrid retrieval as well as ordinary database queries, how row-level security and physical isolation fit into the isolation spectrum, and why audit logs are essential for proving that controls work. This guidance is most useful for teams building shared AI applications, retrieval-augmented generation systems, internal knowledge platforms, or SaaS products where many tenants rely on the same infrastructure but expect their data to remain private.
Watch this video to learn more