Compliance and data residency for AI databases means knowing which rules apply to the data, where that data is stored and processed, who controls the infrastructure, and how personal data can be deleted when required. For AI database systems, this includes more than choosing a cloud region. It also includes embeddings, indexes, metadata, logs, backups, model context, and any replicated copies used for retrieval, search, or analytics.
This guide explains how teams should think about GDPR and regional requirements, what it really means to know where data physically lives, how bring your own cloud deployment models can support residency needs, and how deletion or right-to-be-forgotten requests should be handled in AI database architectures. By the end, readers should understand the main compliance questions to ask before storing sensitive or personal data in a vector database, hybrid search system, or retrieval-augmented generation pipeline.
Why Compliance and Residency Matter in AI Databases
AI databases often store data in forms that are easy to overlook during compliance reviews. A traditional database may hold customer records, documents, or transaction history in a clear table structure. An AI database may hold the original document text, extracted chunks, vector embeddings, metadata fields, search indexes, ranking signals, and cached retrieval outputs. Each layer can affect privacy, residency, security, and deletion obligations.
For example, a customer support knowledge base may contain user-submitted tickets. The retrieval system might split those tickets into chunks, generate embeddings for each chunk, store metadata such as user ID and region, and replicate the index across availability zones for reliability. If a privacy request arrives later, the team needs to know whether deleting the original ticket is enough. In most serious systems, it is not. The derived records and retrieval artifacts also need a clear lifecycle.
Compliance is not only a legal question. It is also an architecture question. The way data flows through ingestion, embedding generation, indexing, retrieval, logging, and backup determines whether a team can prove where data lives and whether it can respond to regional privacy requirements with confidence.
Once that wider data footprint is understood, the next question is which requirements apply. GDPR is often the reference point for privacy and data rights, but many organizations also need to consider national rules, industry rules, customer contracts, and internal governance standards.
Meeting GDPR and Regional Requirements
GDPR does not simply say that all EU personal data must remain inside the European Union. Instead, it sets rules for lawful processing, transparency, minimization, security, data subject rights, and international transfers. If personal data moves outside the European Economic Area, the organization needs a valid transfer basis, such as an adequacy decision or appropriate safeguards. That means a residency decision should be paired with a transfer and processing analysis, not treated as a checkbox on its own.
For AI database systems, the first step is to classify the data. Teams should identify whether the system stores personal data, special category data, confidential business data, regulated industry data, or anonymized information. This matters because embeddings and indexes may still be linked back to people or records, especially when metadata includes user identifiers, account IDs, email addresses, locations, or organization names.
A practical compliance review usually asks several questions:
- What data is stored in the AI database, including raw content, embeddings, metadata, logs, and backups?
- Which people, regions, or customers does that data relate to?
- Where is each data layer stored, processed, replicated, and backed up?
- Which vendors, processors, or subprocessors can access the data or support the system?
- What legal basis applies to the processing, and what transfer mechanism applies if data leaves a regulated region?
- How can the organization fulfill access, correction, deletion, retention, and audit requirements?
Regional requirements may also come from outside GDPR. Some public sector, healthcare, financial services, defense, education, and national cloud policies require data to remain in a particular country or region, or require operational control by specific entities. Even when the law does not strictly require local storage, customer contracts may require regional isolation, encryption controls, or evidence that support access is limited.
The important point is that residency and compliance are related but not identical. A system can store data in the right region while still having weak deletion workflows, excessive logging, unclear processor contracts, or uncontrolled transfers through support tools. The architecture must show both where data lives and how it is governed.
After the regulatory scope is clear, the next practical question becomes physical location. Teams need to understand what “where the data lives” means across the full AI database stack, because the answer is often broader than the primary storage region shown in a cloud console.
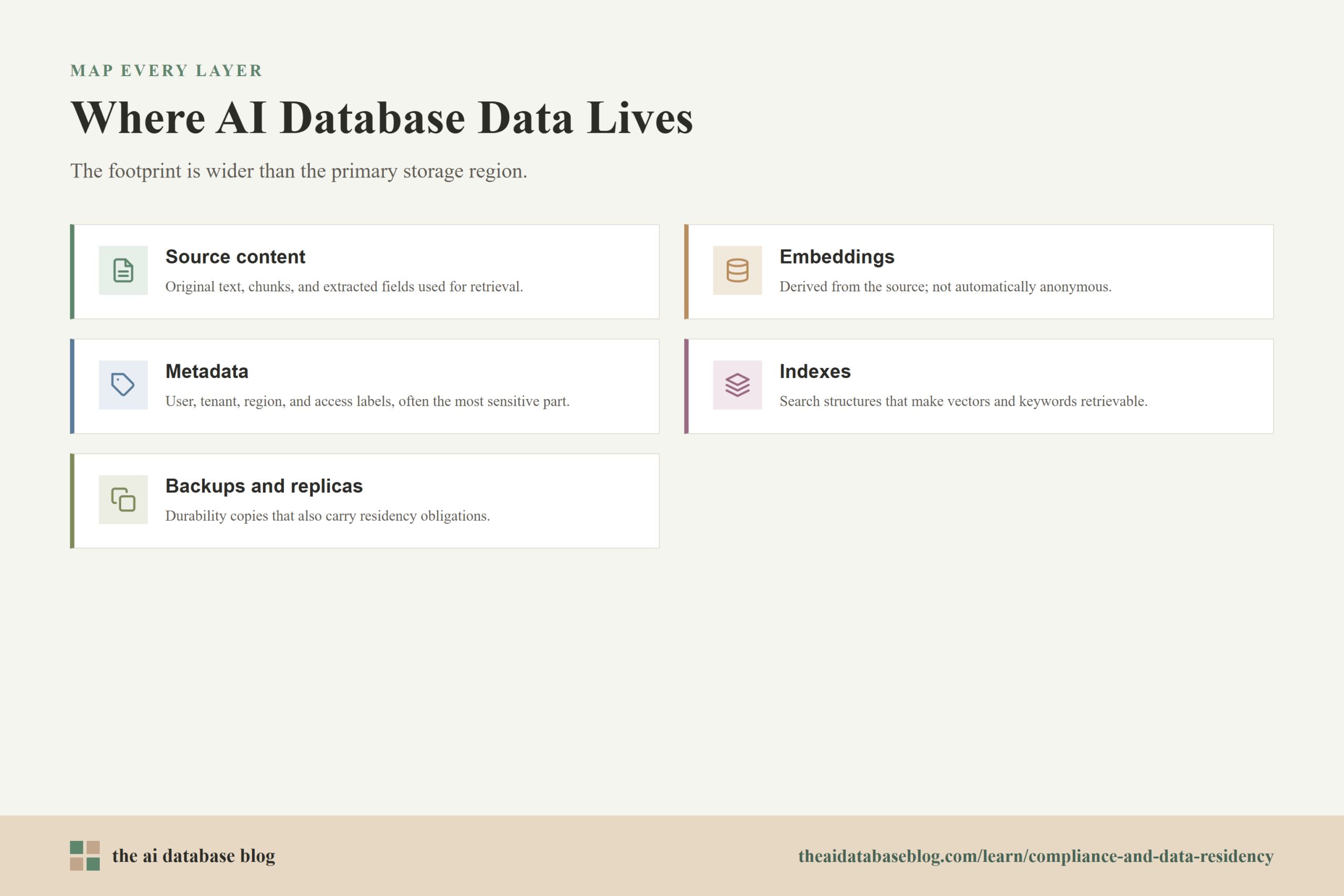
Where Data Physically Lives in an AI Database System
Data residency refers to the geographic location where data is stored and, in many cases, processed. In AI database architecture, that location can include the primary database region, replicated storage, object storage, embedding generation services, observability pipelines, backups, search replicas, and temporary processing queues. A complete answer must account for each of these components rather than only the main cluster.
The physical data footprint usually starts at ingestion. Documents may arrive through an application server, file upload service, message queue, or batch pipeline. Before they reach the AI database, they may be parsed, cleaned, chunked, enriched, and sent to an embedding model. If any of those steps runs in another region, the system may create a cross-region processing event even if the final vector index is stored locally.
The AI database itself may store several kinds of data:
- Source content: original text, document chunks, records, or extracted fields used during retrieval.
- Vector embeddings: numerical representations that capture semantic meaning and are used for similarity search.
- Metadata: filters and attributes such as tenant ID, region, language, access group, timestamps, or retention category.
- Indexes: search structures that make vector, keyword, or hybrid retrieval fast enough for production use.
- Operational data: logs, metrics, traces, query history, error reports, audit events, and temporary caches.
- Backups and replicas: copies used for durability, recovery, failover, and disaster recovery.
Embeddings deserve special attention. They are not the same as the original text, but they are derived from it. In some cases, an embedding may not reveal meaningful personal information on its own. In other cases, when combined with metadata or access to the original corpus, it can still be tied to a person or sensitive record. For compliance planning, teams should avoid assuming that embeddings are automatically anonymous. They should be governed according to the sensitivity of the source data and the realistic risk of re-identification or linkage.
Metadata can be even more sensitive than the vector itself. A vector may represent a support ticket, while metadata may reveal the user, account, country, product, issue type, contract tier, or internal access permissions. If regional rules apply to customer data, metadata fields often need the same residency, retention, and deletion treatment as the content they describe.
Because the physical footprint is distributed across many services, organizations need a data map. This map should show each storage and processing location, the purpose of each component, the categories of data stored there, and how long each copy is retained. Without that map, it is difficult to answer a customer, regulator, or internal reviewer who asks where a specific person or tenant’s data resides.
Once the data map reveals where the system stores and processes information, teams can choose deployment patterns that match their residency needs. One increasingly common option is bring your own cloud, especially when a managed AI database is useful but standard multi-tenant SaaS hosting does not fit the organization’s regional controls.
How BYOC Supports Data Residency
Bring your own cloud, often shortened to BYOC, is a deployment model where software is operated in a customer’s cloud account or a dedicated cloud environment selected by the customer. The goal is to combine managed software operations with more customer control over network boundaries, cloud region, encryption settings, private connectivity, and data location. For AI databases, BYOC can be useful when teams need regional control without running every database operation manually.
BYOC can support residency because the data plane can be placed inside a chosen region or cloud account. In many architectures, the data plane is where customer data is stored, indexed, queried, replicated, and backed up. If designed well, this can keep source content, embeddings, metadata, and search indexes within the customer’s approved region. The vendor or service operator may still manage upgrades, monitoring, or orchestration, but the storage and query workloads run inside the customer’s selected environment.
However, BYOC should not be treated as automatic compliance. The architecture still needs a clear split between the control plane and the data plane. The control plane may handle account management, deployment orchestration, billing, telemetry, support access, or software updates. If the control plane receives logs, query samples, metadata, or diagnostic payloads from a different region, that can create a data movement issue. Teams should understand exactly what information leaves the customer environment and whether that information is personal, confidential, or regulated.
A careful BYOC review should include these checks:
- Confirm the region where source data, embeddings, indexes, and backups are stored.
- Verify whether embedding generation, reranking, monitoring, or support tooling processes data outside that region.
- Review whether logs and traces include prompts, queries, document snippets, user IDs, or other sensitive metadata.
- Define who can access the environment, under what conditions, and how access is approved and audited.
- Confirm encryption key ownership, rotation practices, and whether customer-managed keys are available when required.
- Document subprocessors, support locations, and any cross-border access paths.
BYOC is especially relevant for organizations that want managed AI database capabilities but must keep workloads close to existing regulated data. A healthcare system, government agency, bank, or multinational enterprise may already have approved regional cloud environments. Running the AI database data plane there can reduce the number of places sensitive data travels and make governance easier to explain.
Still, residency alone does not solve data rights. A system that stores everything in the correct region can still fail a compliance review if it cannot delete records reliably. That is why deletion and right-to-be-forgotten workflows need to be designed into the AI database from the start.

Handling Deletion and Right-to-Be-Forgotten Requests
Deletion requests become more complex in AI database systems because one original record may produce many derived artifacts. A customer profile, support message, document, or chat transcript may be chunked into multiple pieces, embedded into vectors, linked to metadata, added to several indexes, copied into backups, and referenced in logs. When a valid deletion request applies, the system should remove or make inaccessible the relevant personal data across this full chain.
Under GDPR-style erasure rights, organizations may need to delete personal data when it is no longer needed, when processing is unlawful, when consent is withdrawn in applicable circumstances, or when another qualifying condition applies. The right is not absolute. Some data may need to be retained for legal obligations, public interest reasons, legal claims, or other recognized exceptions. For AI database teams, the engineering task is to make those decisions enforceable at the record level instead of relying on manual guesswork.
A strong deletion workflow begins with stable identifiers. Each chunk, embedding, metadata object, and index entry should be traceable back to the source record, user, tenant, or deletion domain. If the system cannot find all derived objects for a record, it cannot confidently delete them. This is why ingestion pipelines should assign durable IDs and preserve lineage from the original content through every retrieval artifact.
Deletion should usually cover several layers:
- Primary records: remove or anonymize the original personal data from the source system when required.
- Document chunks: delete segmented text or structured fields created from the original record.
- Embeddings: remove vector records linked to the deleted content.
- Indexes: update vector, keyword, and hybrid search indexes so deleted content cannot be retrieved.
- Metadata: delete personal identifiers, access labels, and regional attributes that remain tied to the person.
- Caches and retrieval logs: expire cached answers, query traces, or snippets that include the deleted data.
- Backups: follow a documented backup retention process and prevent deleted data from being restored into active use.
Backups require a practical policy. Many systems cannot instantly rewrite every backup snapshot. A common approach is to delete data from live systems promptly, mark backup copies as beyond normal use, restrict restoration paths, and allow the data to age out under a defined retention schedule. If a restore occurs, the deletion request should be replayed before the restored system is returned to production. The policy should be clear enough that privacy, security, and engineering teams all understand what happens after a request is fulfilled.
Teams should also consider downstream recipients. If personal data has been disclosed to another system, processor, or service that is still processing it, the organization may need to notify that recipient of the erasure. In an AI database architecture, downstream systems could include analytics tools, labeling systems, evaluation datasets, model monitoring pipelines, or separate retrieval services used by another product team.
The most reliable deletion systems are not one-off scripts. They are repeatable workflows with request intake, identity verification when appropriate, scope determination, deletion execution, exception handling, audit logging, and confirmation. The workflow should record what was deleted, what was retained, why any exception applied, and when remaining copies will expire.
With deletion handled as an architecture requirement, compliance becomes much easier to maintain over time. The final step is connecting residency, access control, retention, and deletion into a practical operating model that can survive product changes and new AI features.
Practical Architecture Patterns for Compliant AI Data Systems
Compliant AI database design works best when governance is built into the data model and retrieval pipeline. Instead of storing vectors as isolated records, teams should treat every vector, chunk, and metadata object as part of a governed data product. That means each object should carry enough information to enforce tenant boundaries, regional restrictions, access permissions, retention rules, and deletion workflows.
One useful pattern is regional partitioning. Data from a particular region or customer group is ingested, embedded, stored, searched, and backed up within an approved location. Queries from that region are routed to the matching regional index, and cross-region retrieval is blocked unless a clear legal and contractual basis exists. This pattern can reduce accidental transfers and make audits easier because the system boundary is easier to explain.
Another important pattern is metadata-driven access control. Each object should include fields that support authorization, such as tenant ID, user group, document classification, region, retention category, and deletion status. Retrieval should filter on these fields before results are returned to an application or language model. This matters because a technically strong vector search system can still create a compliance problem if it retrieves data for the wrong user, tenant, or region.
Teams should also design for data minimization. Not every AI database needs to store full original documents. In some cases, the system can store only the chunks needed for retrieval, redact sensitive fields before indexing, or keep source documents in a separate controlled repository while the AI database stores references. The right approach depends on the application, but the principle is consistent: store what the retrieval system needs, avoid unnecessary copies, and keep sensitive fields out of logs and diagnostics when possible.
Retention rules should be automated. AI database records should not live forever by default unless there is a justified reason. If customer data must be retained for a defined period, the same period should apply to derived chunks, embeddings, and relevant metadata. If some data is needed for evaluation or analytics, teams should consider whether it can be aggregated, anonymized, or separated from identifiable records.
Finally, every major architecture choice should be auditable. A team should be able to answer where the data is stored, who can access it, how it is encrypted, how deletion works, what subprocessors are involved, and what happens during backup restoration. These answers should not depend on one engineer’s memory. They should be reflected in system design, documentation, tests, and operational runbooks.
These patterns turn compliance from a late-stage review into a design discipline. The remaining question for many teams is how to evaluate whether an AI database deployment is ready for real regulated or regionally constrained data.
Questions to Ask Before Choosing or Deploying an AI Database
Before an organization stores personal, regulated, or contractually restricted data in an AI database, it should ask detailed questions about residency, processing, deletion, and operational control. These questions are useful whether the system is self-managed, hosted as SaaS, deployed through BYOC, or built from several components across a retrieval pipeline.
The most useful questions are specific. Instead of asking whether a system is “GDPR compliant,” ask what data the system stores, where each copy lives, whether any processing crosses borders, how long logs are retained, and how deletion requests propagate through derived artifacts. Specific questions produce answers that engineers, privacy teams, and procurement reviewers can verify.
- Can the deployment guarantee that source content, embeddings, metadata, indexes, logs, and backups remain in a selected region?
- Does the embedding or reranking step process data in the same region as the database?
- Are query logs, error traces, and monitoring data scrubbed of personal or sensitive content?
- Can records be deleted by user, tenant, document, region, or retention category?
- Does deletion remove derived chunks and embeddings as well as original records?
- How are backup copies handled after an erasure request?
- What happens if a backup is restored after data has already been deleted?
- Who has administrative or support access to the environment, and is that access logged?
- Are encryption keys controlled by the customer, the provider, or both?
- What subprocessors, support teams, or external services may access data or metadata?
The answers do not always need to be identical for every organization. A public website search index may have different requirements from a medical record retrieval system. The goal is to make the risk visible and choose controls that match the data’s sensitivity, the legal environment, and the business need.
FAQs
1. Is data residency the same as GDPR compliance?
No. Data residency is about where data is stored or processed, while GDPR compliance includes lawful processing, transparency, minimization, security, data subject rights, processor contracts, and transfer rules. Keeping data in a specific region may support compliance, but it does not prove compliance by itself.
2. Do embeddings count as personal data?
Embeddings can count as personal data when they are derived from personal data and can be linked back to a person directly or indirectly. The risk depends on the source content, metadata, access controls, and whether the embedding can be associated with identifiable records. Teams should avoid assuming embeddings are anonymous without a careful assessment.
3. What does BYOC solve for data residency?
BYOC can help place the AI database data plane inside a customer’s chosen cloud account or region. This can give the customer more control over storage location, network access, encryption settings, and operational boundaries. It does not remove the need to review control-plane telemetry, support access, subprocessors, logging, and cross-region processing.
4. Should AI database backups be deleted immediately after an erasure request?
Live systems should generally be updated promptly when a valid erasure request applies, but backups may follow a documented retention and overwrite schedule if immediate deletion is not technically practical. The key is to keep backup data out of normal use, prevent it from being restored without reapplying deletion requests, and explain the backup treatment clearly.
5. Why does metadata matter for compliance?
Metadata often contains identifiers, region labels, access groups, timestamps, account information, or document classifications. Even when the main content is removed or minimized, metadata can still reveal personal or regulated information. It should be included in residency, access control, retention, and deletion planning.
6. What is the safest way to design deletion in an AI database?
The safest approach is to preserve lineage from source records to chunks, embeddings, metadata, indexes, caches, logs, and backups. Each derived object should be traceable to the record, user, tenant, or deletion category that produced it. This makes deletion repeatable, auditable, and much less dependent on manual investigation.
Takeaway
Compliance and data residency for AI databases require a full view of the retrieval system, not just the primary database region. Teams need to understand how GDPR and regional requirements apply, where source content and derived artifacts physically live, how BYOC can support stronger regional control, and how deletion requests move through chunks, embeddings, indexes, logs, and backups. This guidance is most useful for engineering, privacy, security, and procurement teams designing AI search or retrieval-augmented generation systems that store customer, employee, healthcare, financial, or other sensitive data.
Watch this video to learn more