Locality Sensitive Hashing, or LSH, is an approximate nearest neighbor technique that uses special hash functions to place similar items in the same buckets with high probability. Instead of comparing a query vector with every vector in a database, LSH narrows the search to likely candidate buckets, enabling sub-linear lookups when the index is tuned well. It is especially useful for understanding the foundations of vector search because it shows how similarity can be turned into a candidate-generation problem, although modern AI databases often prefer graph methods such as HNSW when they need very high recall across large embedding collections.
This guide explains how LSH works, why similar vectors can collide in the same buckets, how sub-linear lookup is achieved, why LSH schemes are tied to specific similarity metrics, and how random projection and MinHash fit into the broader family of methods. It also compares LSH with graph-based vector search so readers can understand where LSH is still useful, where it becomes harder to tune, and how it relates to retrieval systems used in AI applications.
What Locality Sensitive Hashing Means
Locality Sensitive Hashing is built around a simple idea: a hash function can be designed so that nearby items are more likely to receive the same hash value than distant items. Ordinary hashing tries to spread values evenly and avoid collisions. LSH does something different. It intentionally makes collisions meaningful, so a collision becomes a signal that two items may be similar.
In vector search, each object is usually represented as an embedding: a high-dimensional vector that captures semantic, visual, behavioral, or other learned features. A brute-force nearest neighbor search compares the query vector against every stored vector, which can become expensive as the collection grows. LSH reduces that work by hashing vectors into buckets and then comparing the query only against vectors that land in the same bucket or in a small set of related buckets.
The result is approximate rather than exact. LSH does not guarantee that every true nearest neighbor will be found in a single bucket lookup. Instead, it gives a probabilistic way to make likely neighbors easier to find. This probability-based behavior is the core tradeoff: LSH can reduce search work, but it must be tuned carefully to balance recall, speed, memory use, and false matches.
Once LSH is understood as probability-aware bucketing, the next question is how a hash function can preserve similarity at all. The answer depends on the distance or similarity measure the search system cares about.
How LSH Hashes Similar Vectors Into the Same Buckets
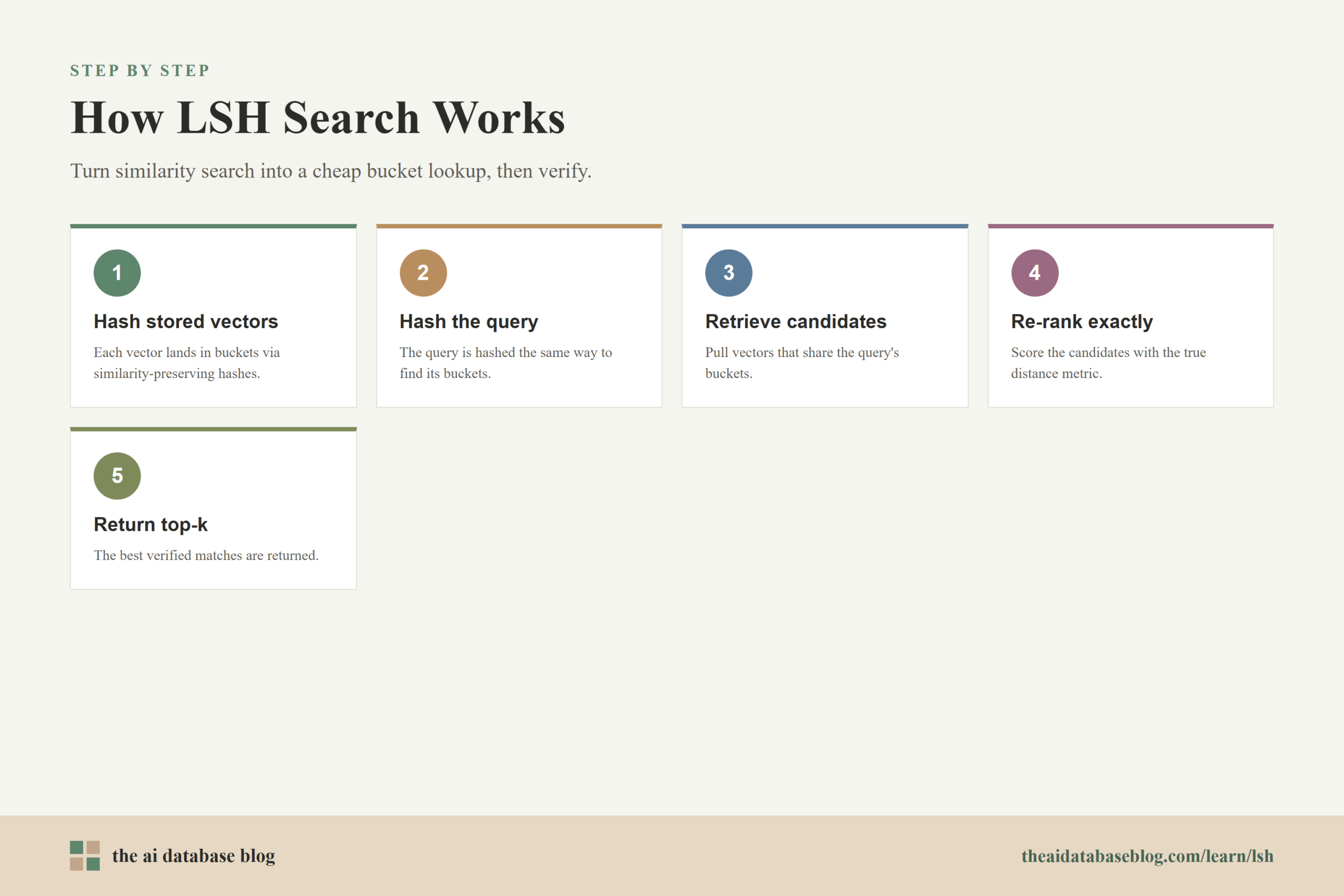
LSH works by choosing a family of hash functions where similarity affects collision probability. If two vectors are close according to the chosen metric, they should be likely to share a hash bucket. If they are far apart, they should be unlikely to collide. A single hash function is usually too weak to be reliable, so practical LSH indexes often use multiple hash functions, multiple hash tables, or both.
Think of each hash function as a rough test that asks, “Do these two items look similar from this particular angle?” One test may be noisy, but many tests together can create a useful signature. During indexing, each stored vector is hashed into one or more buckets. During querying, the query vector is hashed in the same way, and the system retrieves candidates from the matching buckets.
The candidates are then usually re-ranked with the actual distance or similarity function. This re-ranking step matters because a bucket collision is not the final answer. It is a shortcut for finding a smaller candidate set that is worth checking more carefully. In an AI database, that candidate set may then be combined with metadata filters, keyword signals, reranking models, or retrieval rules depending on the application.
Why Multiple Hash Tables Are Common
Multiple hash tables help reduce the chance of missing good neighbors. If a relevant vector fails to collide with the query in one table, it may collide in another. This increases recall, but it also increases memory usage and index maintenance work because vectors must be stored across more hash structures.
Why Longer Hash Signatures Are Common
Longer hash signatures can make buckets more selective. When several hash bits or hash functions are combined into one bucket key, fewer unrelated vectors collide with the query. This can improve speed because each bucket contains fewer candidates, but it may reduce recall if the signature becomes too strict.
These two tuning levers show why LSH is not just “hash and search.” It is a careful balance between broad buckets that catch more neighbors and narrow buckets that reduce unnecessary comparisons. That balance is what allows LSH to support sub-linear lookup behavior.
How LSH Enables Sub-Linear Lookups
A lookup is sub-linear when the search system does not need to examine every stored vector as the dataset grows. In brute-force search, a query over one million vectors may require one million distance calculations. In an LSH index, the query hashes into a small number of buckets, and the system compares only the candidates found there. If the buckets are well balanced and selective, the number of comparisons can be much smaller than the full dataset.
This is the main performance promise of LSH. The index front-loads work during insertion by computing hash signatures. At query time, those signatures guide the system toward a smaller search region. The database still performs exact distance calculations on the candidate set, but the candidate set is intended to be small enough that the query finishes faster.
Sub-linear lookup is not automatic, however. Bucket sizes depend on the data distribution, the hash family, the number of tables, the signature length, and the similarity threshold the application needs. If buckets are too large, query-time comparisons can approach brute-force behavior. If buckets are too small, true neighbors may be scattered across missed buckets. Good LSH design is about creating enough collisions to preserve useful similarity without creating so many collisions that the index stops filtering effectively.
This is also where LSH differs from many newer vector index designs. LSH relies heavily on pre-defined hash families and probabilistic collisions, while graph methods build navigable relationships among the vectors themselves. Before comparing those approaches, it helps to understand why LSH schemes are metric-specific.
Why LSH Schemes Are Metric-Specific
An LSH family must match the similarity measure used by the retrieval problem. A hash function that preserves angular similarity is not the same as one that preserves Jaccard similarity. This matters because embeddings, documents, sets, binary fingerprints, and sparse features may all use different definitions of “near.” The hash scheme has to make collisions likely under the same notion of similarity that the application uses for ranking.
For dense embedding search, common metrics include cosine similarity, inner product, and Euclidean distance. For set-like data, such as shingles from documents or collections of tokens, Jaccard similarity is often more natural. LSH can support several of these settings, but it does not use one universal hash function for all of them.
If the wrong scheme is used, the buckets may preserve the wrong relationships. Two items could collide because they look similar under one metric while being poor matches under the metric the application actually cares about. That is why LSH should be selected based on the retrieval objective, not just on the fact that the data is high-dimensional.
Random Projection for Vector Similarity
Random projection LSH is often used to explain LSH for dense vectors. One common version uses random hyperplanes. A vector is projected against a randomly chosen direction, and the sign of that projection becomes a hash bit. Vectors that point in similar directions are more likely to fall on the same side of the hyperplane, so they are more likely to share hash bits.
By using several random projections, the system creates a compact signature for each vector. Similar vectors should have similar signatures, and the query can retrieve vectors with matching or nearby signatures. This approach is closely connected to angular similarity and cosine-style search, which makes it relevant to many embedding retrieval problems.
MinHash for Jaccard Similarity
MinHash is a locality sensitive hashing scheme for estimating similarity between sets. It is commonly associated with Jaccard similarity, which compares how much two sets overlap relative to their union. Instead of dense numerical vectors, MinHash is useful when each item can be represented as a set, such as document shingles, tokens, or other discrete features.
The basic idea is to apply hash functions to the elements of a set and keep a compact signature based on minimum hash values. Sets with high overlap are likely to produce similar MinHash signatures. This makes MinHash useful for near-duplicate detection, document clustering, and retrieval problems where set overlap is a better signal than geometric vector distance.
Other Metric-Specific Families
There are also LSH families for other distance measures, including schemes related to Euclidean distance and Hamming distance. The important point is not to memorize every family, but to recognize the pattern: each LSH design encodes a particular similarity assumption. The index works well only when that assumption matches the data and the retrieval task.
Metric-specific design gives LSH its theoretical clarity, but it also makes implementation choices more sensitive. A modern AI database often has to support dense vectors, filters, updates, reranking, and high-recall retrieval at the same time. That wider system context is one reason graph methods are so common today.
How LSH Compares With Graph Methods
Graph-based approximate nearest neighbor methods organize vectors as nodes connected to other nearby nodes. At query time, the search starts from one or more entry points and walks through the graph toward increasingly similar vectors. HNSW, one of the best-known graph methods, adds a hierarchical structure so the search can move quickly across broad regions before refining at denser lower layers.
The difference between LSH and graph search is easiest to understand through their retrieval strategies. LSH asks, “Which bucket does this query fall into, and which stored vectors share that bucket?” Graph search asks, “Starting from a navigable set of vector relationships, which path leads toward the nearest neighbors?” Both avoid full brute-force scans, but they do so in different ways.
Graph methods often perform well for high-recall vector search because they adapt to the actual neighborhood structure of the dataset. Instead of relying only on random hash functions, they use links among nearby vectors. This can make them more effective across many dense embedding workloads, especially when the goal is to retrieve highly relevant top results with predictable recall.
LSH still has strengths. It is conceptually simple, parallel-friendly, and grounded in clear probability guarantees for certain near-neighbor formulations. It can be attractive when the metric-specific scheme is a strong fit, when insertions need to be straightforward, or when the application can tolerate approximate candidate generation followed by re-ranking. It is also valuable as a teaching model because it reveals the basic candidate-generation problem underneath vector search.
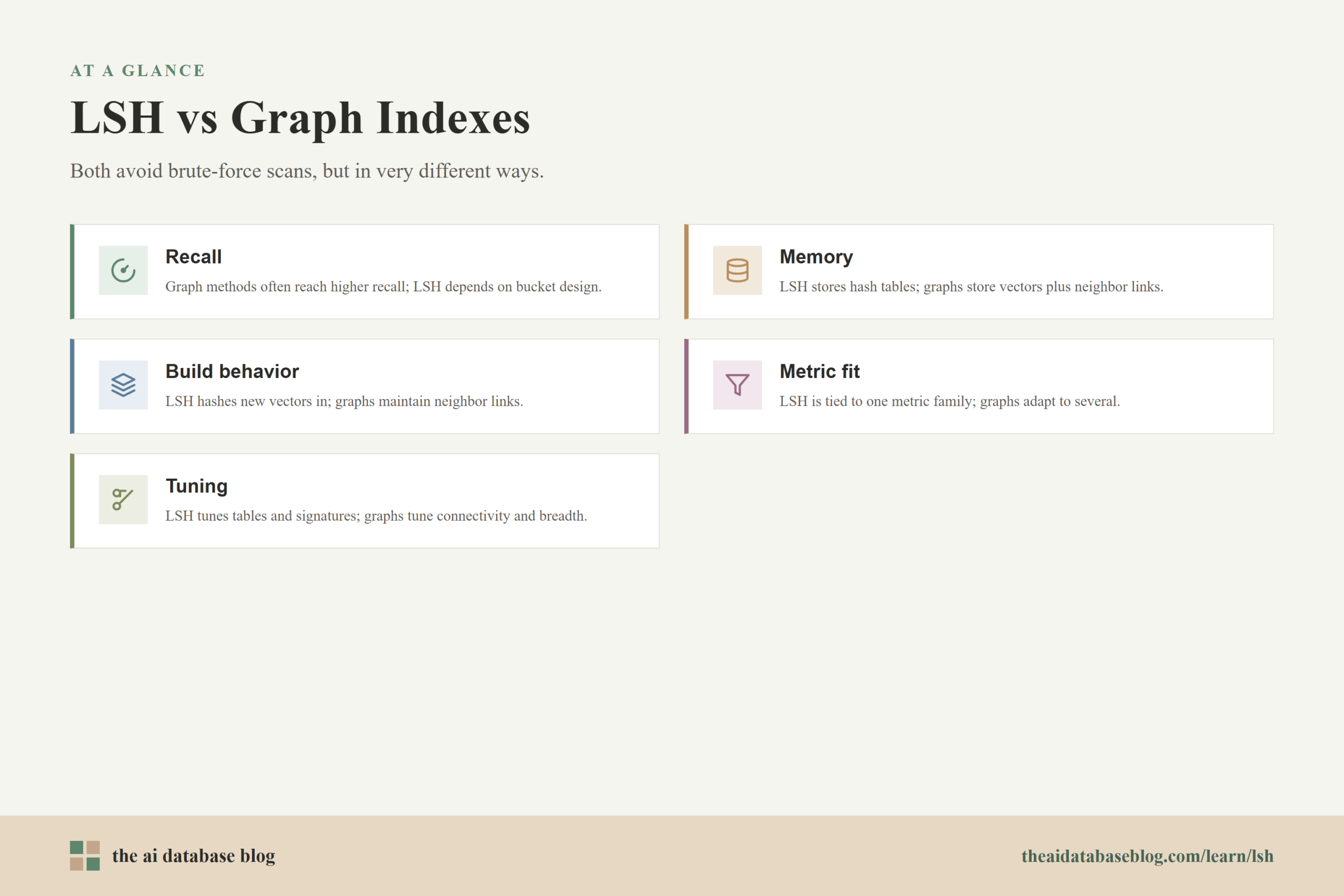
Tradeoffs Between LSH and Graph Indexes
- Recall: Graph methods often reach higher recall for dense vector search at practical latency targets, while LSH recall depends heavily on bucket design, table count, and candidate expansion.
- Memory: LSH uses memory for hash tables and bucket entries. Graph methods use memory for vectors and neighbor links, and high-recall configurations can require substantial graph storage.
- Build behavior: LSH insertion is often easier to reason about because new vectors are hashed into buckets. Graph indexes may require neighbor selection and graph maintenance, which can make build and update behavior more complex.
- Metric fit: LSH is strongly tied to the selected metric family. Graph methods can often be implemented for several distance functions, though performance still depends on the metric and data distribution.
- Tuning: LSH tuning focuses on hash functions, signature length, number of tables, and bucket probing. Graph tuning focuses on connectivity, candidate exploration, construction parameters, and search breadth.
These tradeoffs do not mean one approach is universally better. They mean the index should match the retrieval goal. A duplicate-detection system over sets may be a natural MinHash use case, while a semantic search system over dense embeddings may benefit more from a graph index. The right choice depends on the data shape, recall target, latency budget, memory budget, and update pattern.
Where LSH Fits in AI Database Retrieval
In AI database systems, LSH is best understood as one member of a larger family of approximate nearest neighbor techniques. It is not the only way to make vector search fast, and it is not always the production default for dense embedding retrieval. However, it remains important because many retrieval systems still rely on the same high-level idea: generate a candidate set cheaply, then spend more computation on ranking the most promising items.
For retrieval-augmented generation, recommendation, semantic search, or multimodal search, the database usually needs to find relevant items quickly while preserving enough recall that important context is not missed. LSH can support that goal when its hash scheme fits the data and when approximate candidate generation is acceptable. In other cases, graph indexes, inverted-file indexes, quantization, or hybrid combinations may be more practical.
LSH can also work alongside other retrieval signals. For example, a system might use metadata filters to restrict the search space, then use an approximate vector index to generate candidates, and finally use a reranker or exact scoring step to improve final relevance. In that architecture, LSH is not the whole retrieval system; it is one possible candidate-generation layer.
Thinking about LSH this way makes the practical decision clearer. The question is not simply whether LSH is fast. The question is whether its buckets produce the right candidates for the application, at the right recall, with acceptable memory and maintenance costs.
Practical Guidance for Choosing LSH
LSH is a reasonable option when the retrieval problem has a clear similarity metric and the matching LSH family is well understood. It can be especially useful for near-duplicate detection, set similarity, exploratory candidate generation, and systems where approximate recall is acceptable. It is also useful when explainability matters, because the index behavior can often be described in terms of bucket collisions and probability.
LSH is less attractive when the system requires consistently high recall over dense embeddings, when data distributions are difficult to bucket evenly, or when tuning many hash tables becomes operationally expensive. In those cases, graph-based indexes may be easier to tune for strong search quality, even if their internal structure is more complex.
A practical evaluation should test recall, latency, memory, and update behavior on the actual dataset. Synthetic assumptions can be misleading because LSH performance depends on how vectors distribute across buckets. A well-designed benchmark should compare candidate quality and final relevance, not just raw query speed.
After the index is chosen, the final retrieval quality still depends on the surrounding system. Metadata filters, hybrid keyword and vector search, reranking, chunking strategy, and evaluation datasets can matter as much as the index family itself. LSH can help make lookup cheaper, but it does not replace relevance engineering.
FAQs
1. What is Locality Sensitive Hashing in simple terms?
Locality Sensitive Hashing is a way to group similar items together using special hash functions. Unlike ordinary hashing, where collisions are usually treated as something to avoid, LSH makes collisions useful. If two vectors or sets are similar, they are more likely to land in the same bucket, which lets the search system inspect fewer candidates.
2. Why is LSH approximate instead of exact?
LSH is approximate because similar items are likely, but not guaranteed, to collide in the same bucket. A true nearest neighbor may fall into a different bucket, and an unrelated item may collide with the query by chance. Practical systems handle this by using multiple hash functions, multiple tables, candidate expansion, and exact re-ranking after candidate retrieval.
3. How does LSH make vector search faster?
LSH makes vector search faster by reducing the number of vectors that need full distance calculations. The query is hashed into buckets, and the system compares it mainly with candidates from those buckets. When the index is tuned well, this can produce sub-linear lookup behavior because the query does not scan the full collection.
4. What is the difference between random projection LSH and MinHash?
Random projection LSH is commonly used for dense vectors and angular or cosine-style similarity. It uses random directions to create hash bits that similar vectors are likely to share. MinHash is used for set similarity, especially Jaccard similarity, and is useful for problems such as near-duplicate documents or overlapping token sets.
5. Is LSH still useful if graph methods are common in vector databases?
Yes, LSH is still useful, but its role is more specific. Graph methods are often preferred for high-recall dense vector search, while LSH remains useful for certain metric-specific workloads, set similarity, candidate generation, and educational understanding of approximate nearest neighbor search. It is also a good option to evaluate when the data and metric fit the hash scheme well.
6. When should an AI database avoid LSH?
An AI database should be cautious with LSH when it needs high and predictable recall across dense embeddings, when buckets become uneven, or when tuning many hash tables creates too much operational overhead. In those cases, graph indexes or other approximate nearest neighbor methods may provide a better balance of recall, latency, and maintainability.
Takeaway
Locality Sensitive Hashing is a probabilistic indexing method that turns similarity search into a bucket lookup problem: similar vectors or sets are designed to collide more often than dissimilar ones, making sub-linear candidate retrieval possible when the scheme is well matched to the metric. Readers building or evaluating AI database systems should understand LSH because it clarifies the tradeoff between speed and recall, especially for use cases such as near-duplicate detection, set similarity, and candidate generation before re-ranking. For many dense embedding workloads, graph methods may be more practical today, but LSH remains an important foundation for understanding how approximate retrieval systems reduce search cost without scanning every stored item.
Watch this video to learn more