HyDE, short for Hypothetical Document Embeddings, is a retrieval technique that asks a language model to generate a likely answer or passage for a user query, embeds that generated text, and then uses the resulting vector to search an AI database. Instead of embedding only the user’s often-short question, HyDE embeds a richer hypothetical document that is closer in shape and vocabulary to the real documents the system wants to retrieve. This can improve hard queries, especially vague, domain-specific, or vocabulary-mismatched questions, but it also adds cost and latency because the system must make an extra model call before retrieval.
This guide explains what HyDE is, how it fits into vector search and retrieval-augmented generation, why generating a hypothetical answer can improve retrieval quality, and when the extra model call is worth it. By the end, you should understand how HyDE changes the retrieval step, what tradeoffs it introduces, and how to think about using it in an AI database system without treating it as a universal upgrade.
What HyDE Means in AI Database Retrieval
In a typical vector search workflow, a user’s query is turned directly into an embedding. The AI database then compares that query vector against stored document vectors and returns the closest matches. This works well when the query and the relevant documents use similar language, but it can struggle when the user asks a short question and the answer is stored in longer, more technical, or differently worded text.
HyDE changes the query representation before the search happens. Rather than embedding the raw query alone, the system first asks a language model to write a hypothetical document that could answer the query. That generated text may not be factually grounded yet, but it often contains the concepts, terms, and explanatory structure that a relevant real document is likely to contain.
The important point is that HyDE does not use the generated answer as the final truth. The generated text is only an intermediate retrieval aid. The AI database still retrieves real documents from the indexed corpus, and the downstream application should rely on those retrieved documents when producing a final answer.
Once that distinction is clear, HyDE becomes easier to understand. It is not a replacement for retrieval, and it is not a way to let a model invent supporting evidence. It is a way to create a better search vector when the original query is too thin, ambiguous, or unlike the language used in the source data.
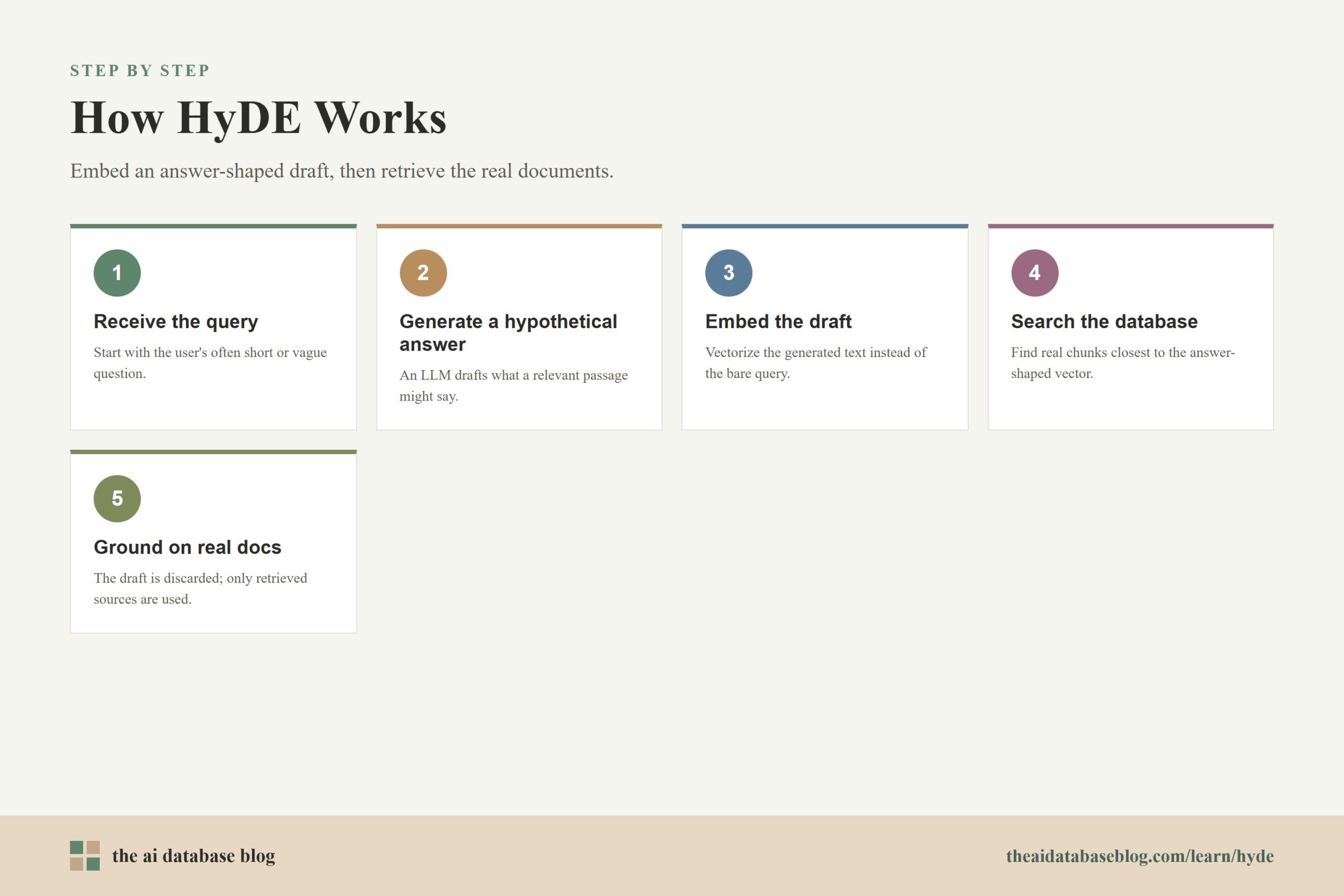
How HyDE Works Step by Step
A HyDE pipeline starts with the same input as ordinary retrieval: a user question or search query. The difference is that the query is routed through a generation step before the embedding step. The language model is prompted to produce a short answer, passage, or document that represents what a relevant result might say.
After the hypothetical text is generated, the system embeds that text using the same embedding model or compatible embedding model used for retrieval. The resulting vector becomes the search vector. The AI database then performs nearest-neighbor search against the stored document embeddings, often with the same filtering, ranking, and top-k retrieval logic used in a standard vector search pipeline.
A simple HyDE flow looks like this:
- The user asks a question, such as “How do I reduce irrelevant results in a RAG system?”
- A language model generates a hypothetical answer about improving retrieval relevance, using terms such as query rewriting, metadata filtering, hybrid search, reranking, and evaluation.
- The system embeds that generated answer rather than only embedding the original question.
- The AI database searches for real chunks whose embeddings are close to the hypothetical answer embedding.
- The application uses the retrieved real documents as context for the final response or search result.
Some implementations generate one hypothetical document. Others generate several and average their embeddings, which can smooth out quirks from a single generation. Multiple generations may improve robustness in some cases, but they also increase cost and latency further, so they should be tested against the application’s actual retrieval goals.
This step-by-step view shows why HyDE is best understood as a query transformation technique. The system is not changing the indexed data. It is changing the representation of the user’s information need so the vector search has a stronger signal to work with.
Why Generating a Hypothetical Answer Can Improve Retrieval
Vector search depends heavily on the quality of the embedding being used as the query. A short user query may express intent, but it often leaves out the vocabulary that appears in the documents. HyDE gives the embedding model more context to encode by expanding the query into answer-like text before the vector comparison happens.
This helps because many embedding models are better at comparing document-like text to document-like text than they are at comparing a brief question to a detailed passage. A question such as “Why are my RAG answers off?” is semantically related to documents about retrieval quality, grounding, chunking, reranking, and evaluation, but the query itself may not contain those words. A hypothetical answer can introduce the missing concepts in a natural way.
HyDE can also help with the question-answer gap. In many AI database applications, users ask questions while stored documents contain explanations, policies, product details, reports, or troubleshooting notes. The query is written in the language of a request, but the corpus is written in the language of answers. HyDE bridges that gap by creating an answer-shaped embedding target.
The benefit is usually strongest when the query is difficult for ordinary retrieval. These are often queries where the user knows what they need but does not know the exact terminology, or where the content lives in a specialized domain with vocabulary that differs from everyday phrasing. HyDE gives the retrieval system a chance to search using the language that relevant documents are more likely to contain.
However, better recall is not automatic. If the generated hypothetical answer is too broad, too specific, or pointed in the wrong direction, it can pull retrieval toward plausible but irrelevant documents. This is why HyDE should be evaluated as part of the retrieval system, not assumed to improve every query.
Where HyDE Fits in a RAG Pipeline
In retrieval-augmented generation, the retrieval step determines what evidence the model sees before it writes the final answer. If retrieval misses the right documents, even a strong generation model may produce a weak or unsupported answer. HyDE sits before retrieval and tries to improve the quality of the candidate documents that enter the rest of the RAG pipeline.
A common RAG pipeline without HyDE embeds the user’s query, retrieves the nearest chunks, optionally reranks them, and then passes the selected context to the language model. With HyDE, the system inserts a generation step before the embedding search. The language model first produces a hypothetical answer, and that answer is embedded for retrieval.
HyDE can be combined with other retrieval methods. It may be used before vector search, alongside hybrid search, or before a reranking stage. For example, a system might retrieve candidates using both keyword search and a HyDE-generated vector, merge the results, and then rerank the combined set based on relevance to the original query.
The original user query still matters. It should usually be preserved for final answer generation, evaluation, logging, and reranking. The hypothetical document helps find candidates, but the system should still judge final usefulness against what the user actually asked.
This placement matters because it keeps HyDE’s role narrow and controlled. It improves the search representation, while the corpus, metadata filters, rerankers, and final prompt remain responsible for grounding the result in real information.
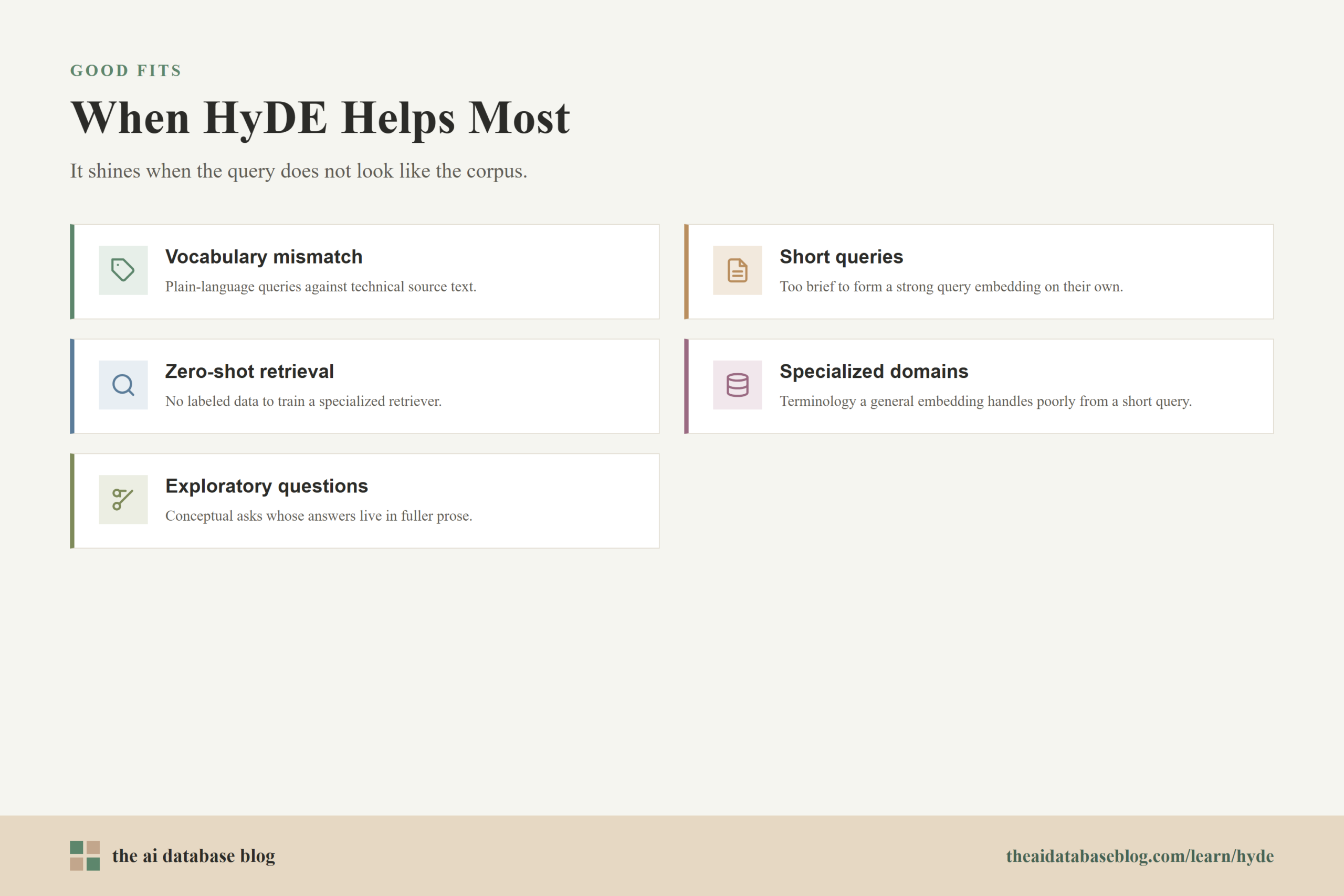
Why HyDE Helps with Hard Queries
Hard queries are not always long or complex. Many are hard because they are underspecified, indirect, or phrased differently from the source material. A user may ask, “How do I stop my chatbot from making things up?” while the relevant documents discuss context grounding, hallucination reduction, retrieval recall, citation quality, and answer faithfulness.
HyDE can improve these queries by making the implicit information need explicit. The generated hypothetical answer may mention the concepts and relationships that the user did not name. When that richer text is embedded, the vector search has more semantic surface area to match against the indexed documents.
HyDE can be especially useful for:
- Vocabulary mismatch: The user asks in plain language, while the documents use technical terms or domain-specific phrasing.
- Short queries: The original query is too brief to produce a strong embedding, such as “metadata in RAG” or “bad retrieval results.”
- Zero-shot or low-label retrieval: The system does not have enough relevance-labeled data to train or tune a specialized retriever.
- Specialized domains: The corpus uses terminology that general-purpose retrieval may not handle well from a short query alone.
- Exploratory questions: The user asks a conceptual question where relevant documents may explain the answer in fuller prose.
The underlying idea is simple: a generated answer can act like a semantic sketch of the document the system hopes to find. Even if some details in the sketch are imperfect, the embedding may still point toward the right neighborhood of documents in the AI database.
The next question is practical: if HyDE can help with difficult retrieval, why not use it for every query? The answer depends on cost, latency, reliability, and whether simpler retrieval improvements already solve the problem.
The Cost of the Extra Model Call
HyDE adds at least one language model call before retrieval. That call has a direct financial cost if the model is accessed through an API, and it has an infrastructure cost if the model is self-hosted. It also adds latency because the system must wait for the hypothetical document before it can create the search embedding and query the AI database.
The added latency can be noticeable in interactive applications. A standard retrieval flow may only need an embedding call and a database search before generation begins. A HyDE flow adds a generation step first, which means the retrieval stage becomes slower even before the final answer model starts producing a response.
The cost grows further when the system generates multiple hypothetical documents. Multiple generations can improve coverage, but each extra generation consumes more tokens and may increase response time. In high-volume applications, even a small per-query increase can become meaningful at scale.
There is also an operational cost. HyDE introduces another prompt to maintain, another model behavior to monitor, and another potential source of variance. If the hypothetical answer drifts from the user’s intent, the retrieval results can drift too. Teams using HyDE should log the original query, the generated hypothetical document, the retrieved results, and the final answer so they can debug failures.
This does not mean HyDE is too expensive to use. It means the technique should earn its place. If it significantly improves recall or answer quality for important hard-query categories, the added cost may be justified. If ordinary vector search, hybrid search, metadata filtering, better chunking, or reranking already performs well, HyDE may add complexity without enough benefit.
When to Use HyDE
HyDE is most useful when the retrieval system is missing relevant documents because the user’s query does not look like the corpus. This is common in AI database applications where users ask conversational questions but the indexed content contains formal explanations, technical documentation, long reports, or domain-specific terminology. In those cases, generating an answer-shaped search vector can make the retrieval step more forgiving.
It is also a good candidate when the application has limited relevance labels. If there is not enough labeled query-document data to train or fine-tune a retriever, HyDE can provide a zero-shot way to improve the query representation. It lets the language model contribute semantic expansion without requiring the database to be rebuilt or the retriever to be trained from scratch.
HyDE is worth testing when you see patterns such as:
- Users ask broad questions that require explanatory documents, but retrieval returns fragments that match only surface-level words.
- Relevant documents exist in the corpus, but they use different terminology than users naturally type.
- Short queries perform worse than longer, more descriptive queries.
- Domain-specific content is hard to retrieve with a general embedding model.
- Improving recall is more important than minimizing every millisecond of retrieval latency.
HyDE should be tested with real queries, not only with hand-picked examples. A small evaluation set of common, difficult, and failure-prone queries can show whether the technique improves retrieval enough to justify its cost.
If HyDE improves only a narrow category of queries, it does not need to run on every request. Many systems can use it selectively, triggering HyDE only when the query is short, ambiguous, low-confidence, or part of a known hard-query pattern.
When HyDE May Not Be the Right Choice
HyDE is not always the first retrieval improvement to try. If documents are poorly chunked, missing metadata, duplicated, stale, or indexed with an unsuitable embedding model, generating a hypothetical answer will not fix the underlying data problem. The generated vector can only search the corpus that exists.
It may also be unnecessary when simpler techniques already work well. Hybrid search can help when exact terms matter. Metadata filters can narrow retrieval to the right category, date range, user permission, or content type. Reranking can improve the final ordering of candidates after a broad first-stage retrieval.
HyDE can be risky for queries that require exact constraints. If a user asks for a specific identifier, policy clause, error code, product number, or date, a generated hypothetical answer may introduce language that distracts from the exact match. In those cases, keyword search, metadata filtering, or structured lookup may be more reliable.
Another limitation is sensitivity to prompting. A hypothetical document that is too long can dilute the search signal. One that is too confident can over-specify the wrong answer. One that uses a generic tone may retrieve generic documents instead of domain-specific ones. The prompt should guide the model to generate concise, answer-like text that reflects the user’s question without adding unnecessary assumptions.
These limitations do not make HyDE weak. They make it situational. It is most valuable when the main retrieval problem is semantic mismatch, not when the main problem is data quality, access control, exact lookup, or missing source content.
How to Evaluate HyDE in an AI Database System
The best way to evaluate HyDE is to compare retrieval results against a baseline. Start with the current retrieval pipeline, then run the same queries through a HyDE version and compare whether the relevant documents appear more often, appear higher in the result list, and improve final answer quality. The evaluation should include both typical queries and known hard queries.
Useful retrieval metrics include recall at k, mean reciprocal rank, and normalized discounted cumulative gain when relevance judgments are available. If formal labels are not available, human review can still be useful. Reviewers can inspect whether the retrieved documents actually answer the query, whether irrelevant documents were promoted, and whether the final answer became more grounded.
Latency and cost should be measured alongside quality. A HyDE pipeline may improve retrieval but still be unsuitable for a real-time product if it slows down every query too much. The right question is not simply whether HyDE improves retrieval; it is whether the improvement is worth the added model call for the application’s users and usage volume.
Logging is especially important. Store the original query, hypothetical document, embedding search results, filters applied, reranker scores if used, and final selected context. This makes it easier to understand whether a failure came from the generated hypothetical answer, the embedding model, the AI database search, the ranking layer, or the corpus itself.
A practical rollout can start selectively. Try HyDE on low-confidence retrieval results, short natural-language questions, or specific domains where baseline retrieval underperforms. If the measured gain is consistent, expand from there. If the gain is inconsistent, keep HyDE as a targeted fallback rather than a default path.
Practical Design Tips for HyDE
A good HyDE implementation keeps the hypothetical document focused. The prompt should ask for a concise answer or passage that would help find relevant documents, not a final user-facing response. This keeps the generated text close to the retrieval task and reduces the chance that unrelated details shape the embedding.
Use the original query throughout the rest of the system. Even when the HyDE vector retrieves candidates, the reranker and final answer generator should still know what the user actually asked. This helps prevent the hypothetical answer from becoming the system’s new source of truth.
It is also useful to combine HyDE with guardrails in the retrieval layer. Metadata filters can keep the search inside the right tenant, product area, permission boundary, language, or time range. Hybrid retrieval can preserve exact keyword matches while HyDE improves semantic coverage. Reranking can then compare candidates more directly against the original query.
For cost control, consider using HyDE only when it is likely to help. A query classifier, confidence threshold, or retrieval fallback strategy can decide when to run the extra model call. For example, if ordinary retrieval returns high-confidence results, HyDE may be skipped. If ordinary retrieval returns weak or scattered results, HyDE can be triggered as a second attempt.
The most reliable systems treat HyDE as one retrieval tool among several. It is powerful when the problem is semantic expansion, but it works best when paired with clean data, sensible chunking, good metadata, appropriate filters, and careful evaluation.
FAQs
1. What does HyDE stand for?
HyDE stands for Hypothetical Document Embeddings. It refers to a retrieval technique where a language model generates a hypothetical answer or document for a query, and that generated text is embedded and used for vector search.
2. Does HyDE use the hypothetical answer as the final answer?
No. The hypothetical answer is used to create a better search embedding. The system should still retrieve real documents from the AI database and use those documents as the grounding context for any final answer.
3. Why can HyDE improve hard queries?
HyDE can improve hard queries because it expands a short or vague query into richer answer-like text. That text often contains concepts and vocabulary that are closer to the relevant documents, which can help vector search find better matches.
4. What is the main downside of HyDE?
The main downside is the added model call before retrieval. This increases cost, adds latency, and introduces another generated artifact that needs to be monitored and evaluated.
5. Should HyDE be used for every query?
Not necessarily. HyDE is often most useful for short, ambiguous, domain-specific, or low-confidence queries. If ordinary retrieval already performs well, running HyDE on every query may add cost without enough quality improvement.
6. How is HyDE different from query rewriting?
Query rewriting usually reformulates the user’s query into a clearer or more searchable query. HyDE generates a hypothetical answer or document instead, then embeds that generated document to search for real documents with similar semantic content.
Takeaway
HyDE is a practical retrieval technique for AI database systems that struggle with hard semantic queries. By generating a hypothetical answer and embedding it for search, HyDE can bridge the gap between how users ask questions and how relevant documents are written. It is most useful for teams building RAG systems, semantic search, or knowledge retrieval over specialized content, especially when short or vocabulary-mismatched queries often miss the right sources. The tradeoff is clear: HyDE can improve recall and retrieval quality, but it adds an extra model call, so it should be measured against cost, latency, and simpler retrieval improvements before becoming part of the default pipeline.
Watch this video to learn more