Advanced RAG patterns help a retrieval system move beyond one simple vector search followed by one generated answer. Multi-hop retrieval is useful when the answer depends on several pieces of evidence. Parent-document and sentence-window retrieval are useful when small chunks retrieve well but need surrounding context to be useful. Self-querying is useful when a user asks for semantic meaning plus structured constraints such as dates, categories, permissions, or document types. Routing is useful when different questions need different retrievers, indexes, tools, or data sources.
This guide explains how each pattern works, what problem it solves, and when it is worth adding to an AI database-backed RAG system. By the end, you should be able to choose the right retrieval pattern for a specific application instead of adding complexity blindly.

Why Basic RAG Often Stops Being Enough
A basic RAG pipeline usually embeds a user query, searches a vector index for the most similar chunks, places those chunks in the model context, and asks the model to answer. This can work well for direct questions where one passage contains the answer. It is simple, fast, and often the right starting point for product documentation, internal knowledge bases, support articles, and other text-heavy systems.
The limitation is that real questions are not always direct. A user may ask for a comparison across several entities, request information from a specific time period, refer to a narrow sentence that only makes sense inside a larger section, or ask a question that belongs in a different data source from the default one. In those cases, the system may retrieve plausible but incomplete context. The answer may sound confident while missing the evidence needed to be correct.
Advanced RAG patterns are ways to make retrieval more deliberate. They do not replace the AI database; they change how the application queries it, expands context, filters results, or chooses between retrieval strategies. The goal is not to make every query complicated. The goal is to reserve extra steps for cases where a single search is likely to underperform.
Once you see basic RAG as a strong baseline rather than a complete architecture, the next question becomes practical: which failure mode are you trying to fix? The four patterns below each answer a different retrieval problem.
Multi-Hop Retrieval
Multi-hop retrieval is designed for questions that require evidence from more than one place. A single retrieval step may find one useful passage, but it may not find all the supporting facts needed to answer the full question. Multi-hop retrieval decomposes, expands, or iterates the search so the system can gather several related pieces of evidence before generation.
A typical multi-hop question has dependencies. For example, a user might ask, “Which supplier had the highest defect rate among products launched after a policy change?” Answering that may require retrieving the policy change date, finding relevant product launches, connecting those products to suppliers, and then comparing defect rates. No single chunk is guaranteed to contain the complete answer.
How Multi-Hop Retrieval Works
There are several ways to implement multi-hop retrieval, but most systems use one of three approaches. The first is query decomposition, where the model turns the original question into smaller sub-questions and retrieves evidence for each one. The second is iterative retrieval, where the system retrieves an initial result, uses that result to form the next query, and repeats until it has enough evidence. The third is graph-like retrieval, where entities, relationships, or citations guide the next retrieval step.
In an AI database setting, multi-hop retrieval often means issuing several searches against the same index, several indexes, or a combination of vector search, keyword search, and metadata filters. The results are usually merged, deduplicated, reranked, and trimmed before they are passed to the model. This matters because multi-hop retrieval can improve evidence coverage while also increasing noise if every sub-query contributes too many weak matches.
When to Reach for Multi-Hop Retrieval
Use multi-hop retrieval when users ask questions that compare, combine, trace, or infer across multiple records or documents. It is especially useful for analytical questions, incident investigations, research assistants, compliance review, financial document search, scientific literature search, and knowledge bases where facts are distributed across many sources.
Do not use multi-hop retrieval as the default for every query. It usually adds latency, model calls, ranking complexity, and evaluation burden. If most questions are direct lookups, start with strong chunking, hybrid search, metadata filtering, and reranking before adding multi-step reasoning. Multi-hop retrieval earns its cost when the system must assemble evidence that basic top-k retrieval consistently misses.
Multi-hop retrieval solves the “not enough evidence” problem. But even when the right evidence is found, another problem remains: the retrieved chunk may be too small to explain itself. That is where parent-document and sentence-window retrieval become useful.
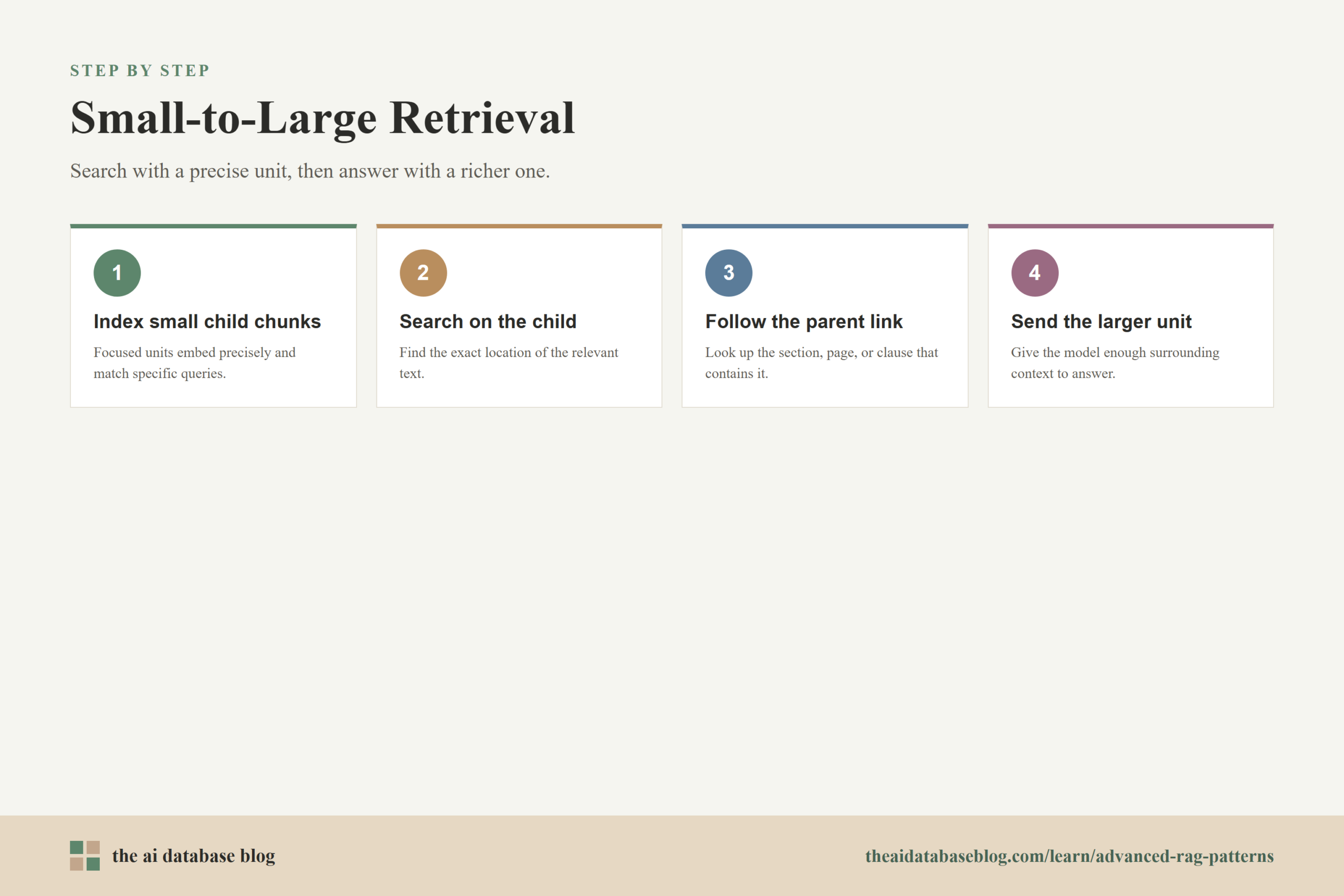
Parent-Document and Sentence-Window Retrieval
Parent-document retrieval and sentence-window retrieval both address a common chunking tradeoff. Smaller chunks often embed more precisely because each vector represents a narrower idea. Larger chunks often provide better context because they include definitions, qualifiers, examples, and surrounding details. These patterns try to get the best of both sides: retrieve with smaller units, then give the model a larger context window for answering.
This is sometimes called small-to-large retrieval. The search unit and the generation unit are intentionally different. The system uses a fine-grained chunk to find the right location, then expands to a parent section, page, document, or sentence window so the model can answer with enough surrounding meaning.
How Parent-Document Retrieval Works
Parent-document retrieval stores relationships between small child chunks and larger parent units. The child chunks are embedded and searched because they are focused enough to match specific queries. When a child chunk is retrieved, the system follows its parent identifier and returns the larger parent text to the model.
The parent does not always need to be the full document. In many systems, the parent should be a section, subsection, page, policy clause, support article segment, or other coherent unit. Returning the entire document can waste context and introduce irrelevant text. Returning the right parent section often gives the model enough context without flooding the prompt.
How Sentence-Window Retrieval Works
Sentence-window retrieval is a more fine-grained version of the same idea. The index may store individual sentences or very small nodes for precise retrieval. At answer time, the system replaces or expands the matched sentence with a fixed number of sentences before and after it. For example, it might retrieve one sentence but send that sentence plus three neighboring sentences on each side to the model.
This pattern is useful when exact details matter and the best matching text is often a single sentence buried inside a long document. The surrounding sentences help preserve local context, such as what “it,” “this policy,” or “the exception” refers to. It can be especially helpful for legal clauses, technical manuals, research papers, medical guidelines, and product documentation where one sentence may be precise but not self-contained.
When to Reach for Parent Documents or Sentence Windows
Use parent-document retrieval when users need answers from sections or documents that have meaningful internal structure. It works well when the answer depends on a paragraph, subsection, table explanation, or policy block rather than a single isolated sentence. It is also useful when citations should point back to a broader source unit instead of tiny fragments.
Use sentence-window retrieval when you need very precise matching but still want enough local context for generation. It is a good fit for dense documents where the relevant evidence is easy to miss with large chunks but hard to interpret when returned alone. If your retrieved chunks are usually correct but the model misreads them because they lack surrounding context, sentence windows are worth testing.
Avoid oversized parent expansion. A common mistake is to retrieve a precise child chunk and then send an enormous parent document that buries the signal. Measure how much context is actually needed. The best parent size or sentence window is the smallest one that consistently preserves meaning.
Context expansion helps when the issue is chunk granularity. A different problem appears when the query itself contains structured intent, such as “only from 2024,” “for enterprise customers,” or “excluding archived policies.” That is where self-querying becomes useful.
Self-Querying
Self-querying is a retrieval pattern where the system interprets a natural language question and converts part of it into a structured query. Instead of treating the whole user request as one semantic search string, the system separates semantic meaning from filters, sorting, limits, or other structured constraints. The AI database can then combine vector similarity with metadata filtering or structured search.
For example, a user might ask, “Find troubleshooting notes about failed sync jobs from customer-facing incidents after March 2025.” A plain vector search may understand “failed sync jobs” but ignore or weakly represent the date and document-type constraints. A self-querying retriever can translate the request into a semantic query such as “failed sync jobs” plus filters such as date greater than March 2025 and source type equals customer-facing incident.
How Self-Querying Works
A self-querying system usually depends on a metadata schema. The retriever needs to know which fields exist, what values they can contain, and which operations are allowed. The model or query parser then produces a structured representation that the application translates into the AI database’s query format.
The important design choice is that self-querying should be constrained. The system should not invent fields or filters that do not exist. Strong implementations validate generated filters against an allowed schema, handle ambiguous values carefully, and fall back gracefully when the user asks for a constraint that the database cannot support.
When to Reach for Self-Querying
Use self-querying when users naturally combine meaning-based search with structured constraints. This is common in enterprise knowledge systems where documents have metadata such as department, author, publication date, region, access level, product line, customer segment, source type, status, or version. It is also useful when search quality depends on excluding irrelevant slices of the corpus before semantic ranking happens.
Self-querying is less useful when your metadata is sparse, inconsistent, or untrusted. It can also fail if users ask for filters that are not represented in the data model. Before adding self-querying, invest in clean metadata, predictable field names, and clear indexing rules. The pattern works best when the database has structured information worth using.
Self-querying helps one retriever understand structured intent. But some systems have a broader challenge: different questions need entirely different retrieval paths. For that, routing is often the cleaner pattern.
Routing
Routing is the pattern of sending a query to the retrieval path most likely to answer it well. A route may choose a data source, index, retriever type, query engine, tool, or retrieval strategy. Instead of forcing every question through the same pipeline, the system classifies the request and sends it to the right place.
Routing can be simple or advanced. A simple router might use rules: billing questions go to billing documents, developer questions go to API docs, and policy questions go to compliance documents. A more advanced router might use a model to inspect the query and choose between semantic search, keyword search, SQL lookup, graph traversal, summarization, or multi-hop retrieval.
How Routing Works
A router needs a set of choices and a way to select among them. Each choice should have a clear description, such as what data it contains, what questions it answers, and what retrieval method it uses. The router compares the user query against those descriptions and selects one or more routes.
In larger systems, routing can happen at several levels. The first level may choose the corpus, such as product docs versus support tickets. The second level may choose the retrieval strategy, such as hybrid search versus multi-hop retrieval. The third level may choose post-processing, such as reranking, context compression, or parent expansion. This layered approach can be powerful, but it should be observable so teams can understand why the system chose a route.
When to Reach for Routing
Use routing when your corpus, query types, or answer workflows are meaningfully different. It is a strong fit for systems that combine documentation, tickets, tables, logs, transcripts, policies, and product data. It is also useful when some questions need low-latency direct retrieval while others justify slower multi-hop reasoning.
Routing is not a cure for poor retrieval quality inside each route. If every retriever is weak, the router only chooses among weak options. Build routes that are individually useful, then add routing when the system needs to choose among them. Evaluate routing accuracy separately from answer quality so you can tell whether failures come from the route choice or from the retriever behind it.
These four patterns can be combined, but they should not be stacked casually. The best architecture usually starts with the failure mode, then adds the smallest retrieval behavior that fixes it.
How to Choose the Right Pattern
The easiest way to choose an advanced RAG pattern is to name the retrieval failure you are seeing. If the system lacks enough evidence, consider multi-hop retrieval. If it finds the right text but loses context, consider parent-document or sentence-window retrieval. If it ignores dates, types, categories, or permissions, consider self-querying. If different questions belong in different places, consider routing.
The patterns are not mutually exclusive. A routed system may send some queries to a self-querying retriever and others to a multi-hop retriever. A multi-hop system may use parent-document expansion after each sub-query. A sentence-window retriever may be one route among several. The key is to combine patterns only where the product experience justifies the extra complexity.
| Pattern | Main problem it solves | Reach for it when | Watch out for |
|---|---|---|---|
| Multi-hop retrieval | Evidence is spread across multiple sources or reasoning steps. | Users ask comparative, investigative, or compositional questions. | Higher latency, more noise, and harder evaluation. |
| Parent-document retrieval | Small chunks retrieve well but need broader section context. | Documents have coherent sections, pages, clauses, or articles. | Returning parents that are too large for the answer task. |
| Sentence-window retrieval | Precise sentence matches need nearby sentences for meaning. | Relevant evidence is narrow, dense, and locally contextual. | Windows that are too small to resolve references or too large to stay focused. |
| Self-querying | Natural language contains structured filters or constraints. | Metadata such as date, region, type, status, or permissions affects relevance. | Invalid generated filters, weak metadata, and schema drift. |
| Routing | Different queries need different data sources or retrieval methods. | The system spans multiple corpora, tools, or query workflows. | Misrouting and lack of observability into route decisions. |
This choice is easier when the AI database is modeled with retrieval behavior in mind. Metadata, chunk relationships, source identifiers, and evaluation labels all affect whether these patterns work well in practice.
Design Considerations for AI Database Systems
Advanced RAG patterns depend on the data model behind retrieval. The AI database should not only store vectors; it should preserve the structure needed to retrieve, filter, expand, cite, and debug results. A system that loses parent-child relationships, source metadata, timestamps, or document boundaries will struggle to support these patterns reliably.
For parent-document retrieval, store child chunks with stable parent identifiers and enough metadata to trace results back to the source. For sentence-window retrieval, preserve sentence order and neighboring text. For self-querying, define metadata fields carefully and keep values normalized. For routing, maintain clear descriptions of each index, table, retriever, or corpus so the router can make meaningful choices.
Latency also matters. Multi-hop retrieval and model-based routing may add extra model calls. Self-querying may add a query construction step. Parent expansion may increase prompt size. These costs can be acceptable when they improve answer quality, but they should be measured rather than assumed. In production systems, it is often useful to apply advanced patterns conditionally instead of on every query.
After the architecture is in place, the next challenge is proving that the pattern actually improves retrieval. Advanced RAG should be evaluated at the retrieval layer, not only by reading final answers.
How to Evaluate Advanced RAG Patterns
Evaluation should begin with examples of real user questions and known useful evidence. For each pattern, ask whether the system retrieved better evidence, not only whether the final generated answer sounded better. This distinction matters because a model can sometimes produce a plausible answer despite weak retrieval, and it can also fail to use good retrieval correctly.
For multi-hop retrieval, measure whether all necessary supporting facts appear in the final context and whether reranking removes irrelevant sub-query results. For parent-document and sentence-window retrieval, compare answer quality and citation usefulness across different parent sizes or window sizes. For self-querying, inspect the generated filters and measure how often they match the user’s intent. For routing, track route selection accuracy and the quality of each route independently.
Useful evaluation signals include retrieval recall, precision, ranking position of relevant evidence, citation accuracy, filter correctness, route correctness, latency, token usage, and human review of groundedness. The best metric depends on the use case. A compliance assistant may care more about complete evidence and citations, while a support assistant may care more about fast answers with enough context to solve a problem.
Good evaluation keeps advanced RAG honest. These patterns are valuable because they solve specific retrieval failures, not because they make the architecture look more sophisticated.
FAQs
1. What makes a RAG pattern advanced?
A RAG pattern becomes advanced when it changes the retrieval process beyond a single query against a single vector index. Advanced patterns may decompose the question, expand retrieved context, translate natural language into structured filters, or choose among several retrieval paths. The goal is to improve evidence quality for questions that basic retrieval does not handle well.
2. Should every RAG system use multi-hop retrieval?
No. Multi-hop retrieval is useful when the answer requires several pieces of evidence, but it adds latency and complexity. If most user questions can be answered from one well-matched passage, basic retrieval with good chunking, metadata filtering, hybrid search, and reranking may be enough.
3. Is parent-document retrieval better than larger chunks?
Parent-document retrieval is often better when small chunks improve search precision but larger chunks improve answer context. Simply making every chunk larger can reduce embedding specificity and make retrieval less accurate. Parent-document retrieval separates the unit used for search from the unit used for generation.
4. When is sentence-window retrieval better than parent-document retrieval?
Sentence-window retrieval is better when the relevant evidence is usually a precise sentence or small local passage. Parent-document retrieval is better when the useful context is a larger section, page, or clause. The right choice depends on how your documents are structured and how much surrounding text the model needs to answer correctly.
5. What metadata do self-querying systems need?
Self-querying systems need reliable metadata fields that match how users ask questions. Common fields include date, source type, department, product, region, author, access level, version, status, and customer segment. The fields should be normalized and validated so generated filters can be executed safely.
6. How do routing and self-querying differ?
Self-querying improves how one retriever interprets a query by adding structured filters or constraints. Routing chooses which retriever, index, data source, or tool should handle the query. In practice, a router may send some questions to a self-querying retriever and other questions to a different retrieval workflow.
Takeaway
Advanced RAG patterns are best understood as targeted fixes for specific retrieval failures. Multi-hop retrieval helps when evidence is distributed, parent-document and sentence-window retrieval help when chunk-level matches need more context, self-querying helps when natural language contains structured constraints, and routing helps when different questions need different retrieval paths. This guidance is most useful for teams building AI database-backed applications that must answer real knowledge questions reliably, such as support assistants, research tools, compliance systems, and internal knowledge search.
Watch this video to learn more