Hybrid search architecture combines keyword search and vector search so an AI application can retrieve results that match exact terms and results that match meaning. The usual pattern is to maintain both a keyword index and a vector index, run both retrieval paths for the same user query, collect candidate results from each path, and fuse the results into one ranked list before optional reranking or answer generation. Score fusion usually happens after the keyword and vector retrievers return their candidate lists, but before the final top results are sent to a reranker, application layer, or retrieval-augmented generation system.
This guide explains how hybrid search is structured, why both index types are maintained, how the two query paths run, and where score fusion fits in the larger retrieval pipeline. By the end, you should understand the moving parts of a hybrid search system well enough to reason about indexing, query execution, result merging, and the tradeoffs between rank-based and score-based fusion methods.
What Hybrid Search Architecture Is
Hybrid search architecture is a retrieval design that uses more than one search method for the same query. In most AI database systems, the two main methods are keyword retrieval and vector retrieval. Keyword retrieval is usually based on sparse signals such as term frequency, inverse document frequency, and lexical matching. Vector retrieval uses embeddings, which are numerical representations of text, images, or other data that place semantically similar items near one another in vector space.
The reason hybrid search exists is that neither method is complete on its own. Keyword search is strong when the user includes exact names, error codes, identifiers, rare terms, product labels, or domain-specific phrases. Vector search is strong when the user describes an idea in different words than the stored content uses. A hybrid system keeps both strengths available and gives the application a way to combine them into a single result list.
For example, a user might search for “database latency during embedding lookup.” A keyword index can find documents that contain “latency,” “embedding,” or “lookup.” A vector index can find documents about slow semantic retrieval, nearest-neighbor search performance, or response-time bottlenecks even if the exact words differ. The architecture is hybrid because both paths contribute evidence before the final ranking is chosen.
Once the purpose of hybrid search is clear, the next question is how the system stores data so both retrieval paths are available. That starts with maintaining two different index views over the same underlying content.
Maintaining Both Vector and Keyword Indexes
A hybrid search system usually stores each document, chunk, or object in a shared data layer while maintaining separate indexes for different retrieval signals. The keyword index stores tokens, term statistics, and fields needed for lexical ranking. The vector index stores embeddings and the structure needed for nearest-neighbor search. These indexes may live inside the same database system or across separate services, but architecturally they represent two different ways to look up the same content.
The keyword index is built from the raw text or selected searchable fields. It may include tokenization, normalization, stemming, stop-word handling, field weights, and document-length statistics. A common scoring approach for keyword retrieval is BM25, which rewards terms that are important in the corpus while accounting for how often they appear and how long the document is. This makes keyword search useful for exact terminology and for content where specific words carry strong intent.
The vector index is built from embeddings generated by an embedding model. The system converts each document or chunk into a vector and stores that vector in an index optimized for similarity search. Many production systems use approximate nearest-neighbor indexing because scanning every vector is too expensive at scale. The vector index is what allows the system to retrieve semantically related content even when the query and document use different wording.
Keeping both indexes current is one of the main operational responsibilities in hybrid search. When content is inserted, updated, deleted, or re-chunked, the system needs to update the keyword representation and the vector representation together. If the text changes but the embedding is stale, semantic search may retrieve outdated meaning. If the keyword index is stale, exact-match behavior may miss or return the wrong documents. Good hybrid architecture treats index synchronization as part of the data pipeline, not as an afterthought.
After both indexes exist, the next stage is query execution. The system has to decide how to transform the user query and how to send it through both retrieval paths without creating unnecessary latency or inconsistent filtering.
Running Both Queries in the Retrieval Pipeline
At query time, the application receives a user query and sends it through two retrieval paths. The keyword path uses the query text directly or after light normalization. The vector path first converts the query into an embedding, then uses that embedding to search the vector index. In a well-designed hybrid pipeline, these two paths often run in parallel because neither path logically depends on the other.
A simple hybrid retrieval flow looks like this:
1. Receive the user query. 2. Apply query preprocessing and metadata filters. 3. Send the query text to the keyword index. 4. Convert the query to an embedding. 5. Send the query embedding to the vector index. 6. Collect candidate results from both retrieval paths. 7. Fuse the candidate lists into one ranked list. 8. Optionally rerank, diversify, or trim the list. 9. Return results or pass them into a RAG system.
Metadata filtering can happen before, during, or after retrieval depending on the database design. In many systems, filters such as tenant ID, document type, publication date, permissions, or language should be applied as early as possible so both keyword and vector retrieval search within the same eligible content. If filtering is applied differently across the two paths, the fusion stage may combine candidates that were not evaluated under the same constraints.
The number of candidates retrieved from each path also matters. A system might ask each retriever for more results than the final output needs, such as retrieving 50 keyword candidates and 50 vector candidates before returning the top 10 fused results. This gives fusion enough room to find documents that are strong in one path, reasonably strong in both paths, or missed by one path entirely. If each retriever only returns a tiny list, fusion has too little evidence to work with.
Once both paths return candidates, the system faces the central hybrid search problem: keyword scores and vector scores are not naturally comparable. That is why fusion is a distinct pipeline stage rather than a simple concatenation of results.

Where Score Fusion Happens
Score fusion happens after the keyword and vector retrievers return their candidate lists and before the final ranking is used by the application. This placement is important because fusion needs access to both retrieval outputs. The keyword retriever contributes a ranked list with lexical relevance scores, while the vector retriever contributes a ranked list with similarity or distance scores. The fusion stage converts those separate signals into one ordering.
In a typical pipeline, fusion is part of the retrieval layer rather than the indexing layer. The indexes are built and maintained before queries arrive. The retrievers search those indexes independently at query time. Fusion then sits downstream of retrieval, taking the two result sets as inputs and producing a unified candidate set as output. If a reranker is used, the reranker usually comes after fusion because it needs a manageable set of candidates to evaluate more deeply.
The fusion stage also handles duplicate candidates. The same document may appear in both the keyword and vector lists. Rather than treating those as two separate results, the system should merge them into one candidate and combine the evidence from both retrieval paths. A document that ranks well in both lists is often a strong result, but a document that ranks highly in only one path may still be valuable depending on the query.
It helps to think of fusion as the point where the system asks, “Given what lexical search found and what semantic search found, what should the combined ranking be?” That question cannot be answered inside the keyword index alone or the vector index alone. It belongs in the layer that can see both outputs at once.
Knowing where fusion happens makes the architecture easier to reason about, but the next question is how the fusion stage should combine scores. The answer depends on whether the system trusts raw scores, normalized scores, ranks, or learned ranking signals.
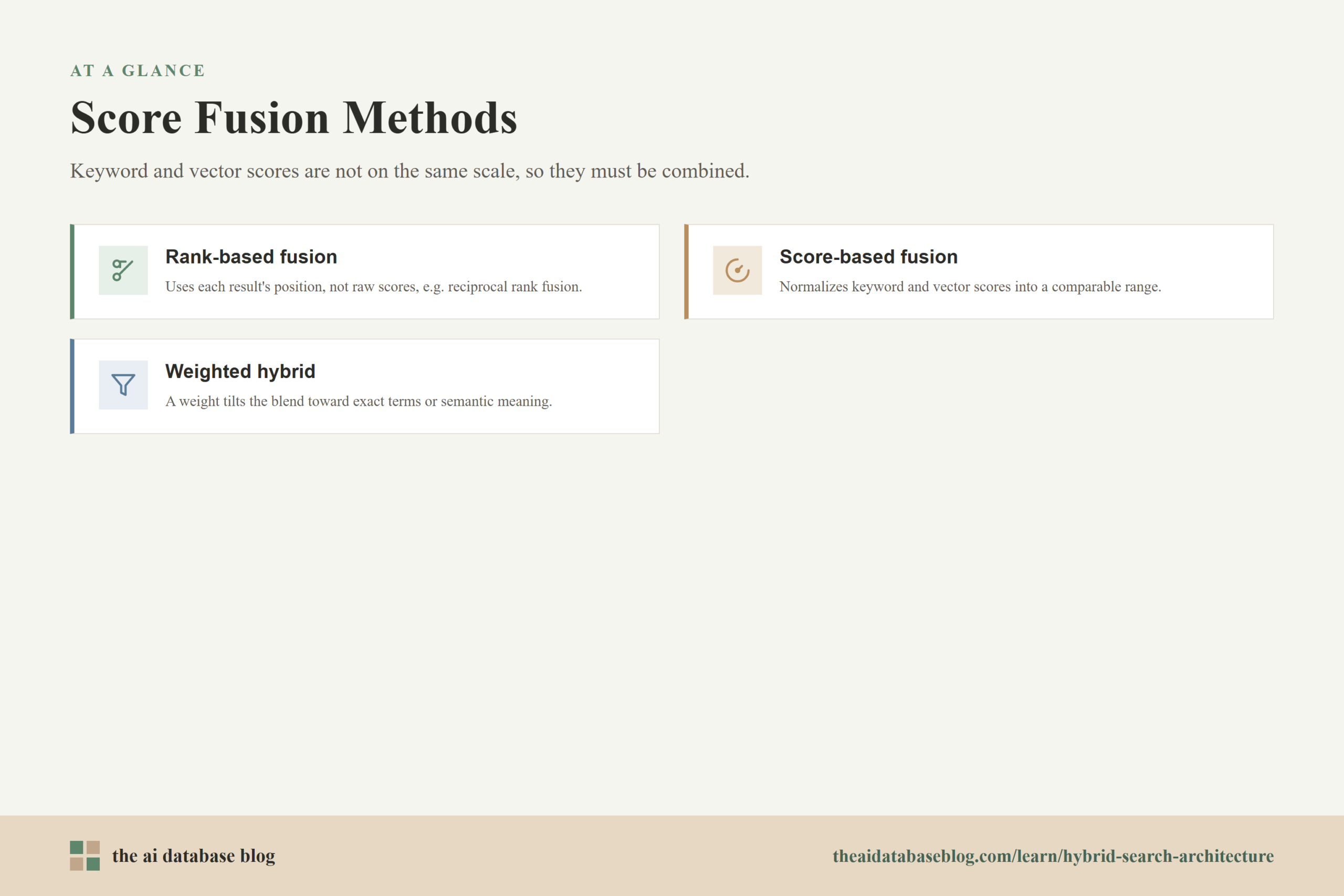
Common Score Fusion Methods
Hybrid search systems use fusion methods to combine two result lists whose scoring systems behave differently. A keyword score may be based on term frequency and document statistics, while a vector score may be based on cosine similarity, dot product, or distance. These values do not share the same scale by default. A BM25 score of 12 and a vector similarity of 0.82 are not directly comparable without some method for blending or ranking them.
Rank-Based Fusion
Rank-based fusion ignores raw score magnitudes and focuses on where each document appears in each result list. Reciprocal rank fusion is a common example. A document receives credit based on its rank in the keyword list, its rank in the vector list, or both. The advantage is that the system does not need to normalize different score scales. This can be useful when the keyword and vector score distributions vary sharply across queries.
Score-Based Fusion
Score-based fusion combines normalized retrieval scores. The system may scale keyword and vector scores into a comparable range, then apply a weight to each retrieval path. For example, a system might give more weight to vector similarity for broad natural-language questions and more weight to keyword matching for queries with exact identifiers. Score-based fusion can preserve more detail from the original retrievers, but it depends on careful normalization and tuning.
Weighted Hybrid Fusion
Many hybrid systems use a weighting parameter to control the balance between keyword and vector results. A higher semantic weight makes the final ranking lean toward vector similarity. A higher keyword weight makes it lean toward exact lexical matches. Some systems keep this weight static, while more advanced systems adjust it based on query characteristics such as length, presence of quoted terms, use of IDs, or whether the query looks like a natural-language question.
The fusion method should match the application’s retrieval goals. Rank-based fusion is often a practical default when scores are hard to calibrate. Score-based fusion can work well when the system can normalize scores reliably and wants finer control over the blend. Weighted fusion is especially useful when different query types need different balances between exactness and semantic breadth.
Fusion produces one ranked list, but that does not always mean the retrieval pipeline is finished. Many AI applications add reranking, diversification, or context assembly after fusion so the final results are more useful for the user or the language model.
What Happens After Fusion
After fusion, the system has a unified set of candidate results. This fused list may be returned directly to a search interface, but in AI applications it is often passed through additional steps. A reranker can evaluate the query and candidate text together to produce a more precise ordering. A diversification step can reduce near-duplicates. A context assembly step can choose which chunks are included in a retrieval-augmented generation prompt.
Reranking is especially common when the first-stage retrievers are optimized for speed and broad recall. Keyword and vector search can quickly gather plausible candidates, while a reranker can spend more computation on a smaller set. This division of labor keeps the system efficient: first retrieve widely, then evaluate deeply. Fusion sits between those stages because it determines which candidates deserve the more expensive downstream attention.
For RAG systems, the fused and possibly reranked results become the grounding context for a generated answer. This makes fusion quality directly important to answer quality. If fusion overweights semantic similarity, the model may receive context that sounds relevant but misses exact facts. If fusion overweights keywords, the model may receive exact matches that do not answer the user’s real intent. The best architecture gives the retrieval system enough flexibility to balance both signals.
Post-fusion stages are useful, but they cannot fully rescue poor indexing or weak first-stage retrieval. That is why the practical design choices around indexing, candidate counts, filtering, and fusion strategy remain central to hybrid search architecture.
Practical Design Considerations
Designing hybrid search is less about choosing one perfect formula and more about building a retrieval pipeline that can be evaluated and adjusted. The right architecture depends on the content type, query patterns, latency budget, and quality target. A support knowledge base with many product codes may need stronger keyword behavior than a research assistant that handles broad conceptual questions. A legal or compliance system may need strict filtering and exact references before any semantic expansion is allowed.
One important consideration is chunking. Vector search often works best when documents are split into chunks that preserve coherent meaning, while keyword search may benefit from field-level structure and exact terms. If chunks are too small, semantic retrieval may lose context. If chunks are too large, keyword scores and embeddings may become less specific. Hybrid search works best when the indexed units are appropriate for both retrieval paths.
Another consideration is evaluation. Teams should test keyword-only, vector-only, and hybrid retrieval separately instead of assuming hybrid search always improves results. Evaluation can reveal whether one path is weak, whether fusion weights are wrong, or whether the system retrieves too few candidates before merging. Useful metrics may include recall at a chosen candidate depth, precision of the final top results, answer faithfulness in RAG, and latency across the full pipeline.
Finally, observability matters. A hybrid system should make it possible to inspect which retriever found a result, what its original rank was, what score or normalized score it received, and how fusion changed the final ordering. Without this visibility, teams may struggle to debug why exact matches disappeared, why semantically similar but incorrect results rose to the top, or why certain query types perform inconsistently.
These considerations show that hybrid search is both an architecture and an ongoing tuning problem. The system needs separate retrieval paths, a clear fusion point, and enough measurement to decide whether the combined ranking is actually better for the application.
FAQs
1.
1. What is the main purpose of hybrid search?
The main purpose of hybrid search is to combine exact keyword matching with semantic similarity. This helps the system find results that contain important terms and results that match the user’s meaning even when the wording is different.
2.
2. Why does hybrid search need both a keyword index and a vector index?
Hybrid search needs both indexes because they support different retrieval signals. The keyword index handles lexical matching and term-based ranking, while the vector index handles embedding similarity. Maintaining both lets the system search the same content from two complementary angles.
3.
3. Do keyword and vector queries run at the same time?
They often run in parallel because the keyword query and vector query are independent once the user query is available. The vector path may require an embedding step first, but after that both retrieval paths can search their indexes and return candidate lists for fusion.
4.
4. Where does score fusion happen in the pipeline?
Score fusion happens after the keyword and vector retrievers return candidate results and before the final list is returned, reranked, or passed into a RAG system. It is the stage that merges separate ranked lists into one combined ranking.
5.
5. Is reciprocal rank fusion the same as score normalization?
No. Reciprocal rank fusion is rank-based, so it uses the position of each result in each list rather than the raw score values. Score normalization is score-based, so it rescales keyword and vector scores before combining them.
6.
6. Should hybrid search always outperform vector-only search?
Not always. Hybrid search often improves retrieval when both exact terms and semantic meaning matter, but its quality depends on indexing, chunking, candidate depth, fusion method, weighting, and query patterns. Teams should evaluate hybrid, vector-only, and keyword-only retrieval against real queries before deciding what works best.
Takeaway
Hybrid search architecture works by maintaining separate keyword and vector indexes, running both retrieval paths for the same query, and fusing their candidate results into one ranked list. The fusion stage belongs after first-stage retrieval and before reranking, final result display, or RAG context assembly. This guidance is most useful for teams building AI search, knowledge retrieval, or retrieval-augmented generation systems where users need both exact matches and semantic understanding, such as a technical documentation assistant that must retrieve both precise error codes and conceptually related troubleshooting guidance.
Watch this video to learn more