A flat, or brute-force, index is the simplest way to perform vector search: store every vector as-is, compare the query vector against every stored vector, sort by distance or similarity, and return the closest matches. It is called an exact search method because it does not skip candidates, compress vectors, route through graph shortcuts, or rely on probabilistic approximations. That makes it slower at large scale than approximate nearest neighbor indexes, but it also gives perfect recall, requires essentially no index-building step, and serves as a trusted ground-truth baseline when evaluating faster search methods.
This guide explains how a flat index works, why exhaustive search is still useful in AI database systems, when it can be fast enough for production use, and why it remains important even when an application eventually moves to an approximate index. By the end, you should understand the practical tradeoff: flat search is not the most scalable choice for every workload, but it is often the clearest, most reliable way to know what the correct nearest-neighbor results actually are.
What a Flat Index Is
A flat index stores embeddings in their original vector form and searches them directly. In a vector database, each embedding represents a piece of data such as a document chunk, image, product, user profile, code snippet, or other searchable object. When a query arrives, the system converts the query into the same type of vector and compares it with the vectors already stored in the database.
The word “flat” is useful because it describes what the index does not do. It does not build a graph of nearby points, divide the vector space into clusters, quantize vectors into smaller codes, or create a tree structure. It keeps the searchable collection in a direct, uncompressed layout and evaluates all possible candidates at query time.
That simplicity makes the flat index easy to reason about. If the distance metric is cosine similarity, dot product, or Euclidean distance, the flat index applies that metric to every stored vector and ranks the results. The returned top-k results are the actual top-k nearest neighbors according to the selected metric and the stored data available at search time.
Once you understand that a flat index is mostly a direct scan over vectors, the next question is what that scan really means in computational terms. This is where the phrase “brute force” becomes important, because it describes the search behavior rather than a lack of engineering sophistication.
Exhaustive Exact Search
Flat indexing uses exhaustive exact search. For each query, the database compares the query vector against every eligible vector in the collection or filtered subset. If there are 50,000 candidate vectors, the search computes 50,000 similarity or distance scores. If there are 50 million candidates, it computes 50 million scores unless some other filter or partitioning step has already reduced the candidate set.
This differs from approximate nearest neighbor search, often called ANN search. ANN indexes are designed to avoid comparing the query with every vector. They may search through a navigable graph, inspect selected clusters, use compressed representations, or apply other strategies that reduce work. These approaches can be dramatically faster, especially for large collections, but they may miss some true nearest neighbors.
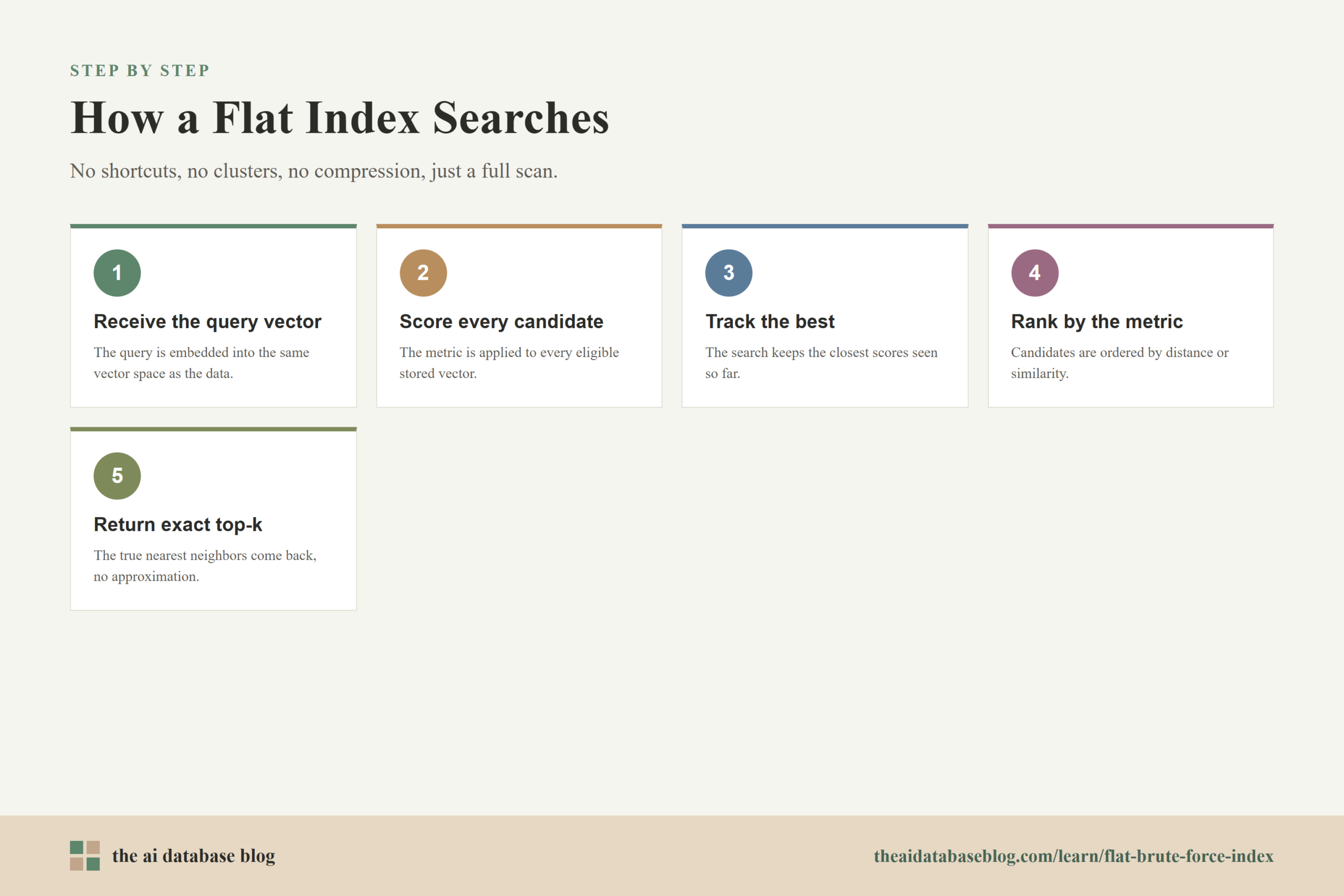
A flat index avoids that uncertainty by doing the full comparison. The process is straightforward:
- The system receives a query vector.
- It compares the query vector with every candidate vector using the configured distance or similarity metric.
- It keeps track of the best-scoring candidates.
- It returns the top-k results in exact ranked order for that metric.
The cost of this approach grows linearly with the number of candidate vectors and the dimensionality of each vector. Searching 10 times as many vectors usually means doing about 10 times as much comparison work. Searching higher-dimensional vectors also increases the amount of math per comparison.
Exhaustive search gives the flat index its main strength and its main weakness at the same time. It is exact because it checks everything. It can become slow because checking everything eventually becomes expensive. The practical question is not whether flat search is theoretically simple, but when that simplicity is still fast enough.
When a Flat Index Is Fast Enough
A flat index can be fast enough when the candidate set is small, the query rate is moderate, the vectors fit comfortably in memory, and the system can use efficient numeric operations. Many AI applications do not begin with billions of vectors. They start with a few thousand, tens of thousands, or hundreds of thousands of embeddings, often scoped by tenant, project, document set, time range, or metadata filter.
In those smaller or more constrained settings, brute-force search can be surprisingly practical. Modern CPUs can perform vector math efficiently, and GPUs can make dense similarity computation much faster when the workload justifies the added system complexity. Batch queries can also improve throughput because the system can compare many query vectors against the same stored matrix more efficiently than handling each query in isolation.
A flat index is often a reasonable choice in cases such as:
- Small knowledge bases: A support bot, internal assistant, or documentation search system may only need to search thousands or low millions of vectors, especially after filtering by workspace, product area, or language.
- Low-query-volume applications: If users search occasionally rather than continuously, exact search may meet latency goals without the operational overhead of an approximate index.
- Filtered retrieval: Metadata filters can reduce the active candidate set before vector scoring. For example, a query limited to one customer, one repository, or one date range may leave only a small subset to scan.
- Evaluation and prototyping: During early development, teams often value correctness and simplicity more than peak search speed. A flat index makes it easier to validate embeddings, chunking, metadata filters, and ranking logic.
- High-accuracy workflows: Some systems prefer slower exact results when missed neighbors would create unacceptable errors, especially in offline analysis or human-reviewed workflows.
The phrase “fast enough” should always be measured against the actual workload. A flat index that is too slow for a public search endpoint with high traffic may be perfectly acceptable for an offline evaluation job, a developer tool, or a retrieval pipeline that searches a small filtered subset.
Performance also depends on what the system has to do around the vector comparison itself. Fetching metadata, applying filters, joining results with source records, reranking candidates, and sending context to a language model can all affect end-to-end latency. In some applications, vector scoring is not the only bottleneck, so moving to an approximate index may not improve the whole workflow as much as expected.
Once latency, throughput, and memory demands grow beyond what exhaustive search can handle comfortably, approximate indexing becomes more attractive. Before making that move, it helps to understand what is being traded away. The most important thing flat search gives you is perfect recall.

Why Flat Search Has Perfect Recall
Recall measures how many of the true nearest neighbors a search method returns. If the correct top 10 nearest vectors are known and a search method returns all 10 of them, its recall at 10 is 100 percent for that query. If it returns 8 of those 10, recall at 10 is 80 percent. This metric is central to evaluating vector search because speed is not useful if the system is consistently missing the best matches.
A flat index has perfect recall because it evaluates every candidate vector. There is no routing decision that might send the query to the wrong cluster, no graph traversal that might stop before reaching the best neighborhood, and no compressed representation that might distort the distance calculation. Given the same data, metric, and filters, flat search returns the exact nearest neighbors.
Perfect recall does not mean the results are always semantically perfect. Vector search quality still depends on the embedding model, text chunking strategy, data cleanliness, metadata filters, and the chosen distance metric. If the embeddings do not represent meaning well, exact search will exactly return the nearest vectors in a flawed embedding space. The flat index guarantees correctness relative to the vectors and metric, not correctness relative to human judgment.
This distinction matters in AI database design. A flat index can tell you whether an approximate index is missing mathematically nearest vectors, but it cannot by itself tell you whether those vectors are the best answers for a user. Relevance evaluation often needs both exact nearest-neighbor comparison and human or task-specific quality checks.
Perfect recall is useful, but it is not the only reason flat indexes remain attractive. They also avoid one of the most operationally annoying parts of many search systems: building and maintaining a more complex index structure.
No Build Step and Simple Updates
A flat index usually has little or no meaningful build step. Adding data means storing the vector and its associated identifier or payload. The system does not need to train clusters, construct a graph, tune search layers, create compressed codes, or wait for a large index construction job before exact search can work.
This simplicity is valuable during ingestion and iteration. When new embeddings arrive, they can often become searchable immediately after insertion. When a team changes a chunking strategy, embedding model, or metadata schema, a flat representation is easier to rebuild because there is less derived index structure to recreate. For small and medium datasets, this can make development cycles much faster.
The lack of a complex build step also reduces tuning burden. Approximate indexes often expose parameters that affect memory usage, build time, recall, and query latency. Those parameters are powerful, but they require measurement and adjustment. A flat index has fewer knobs because the search behavior is direct: compare the query to the candidates and return the closest vectors.
There is still operational work involved. The system must store vectors efficiently, choose the right distance metric, handle filters correctly, manage memory, and keep identifiers aligned with source data. But compared with graph-based or clustered approximate indexes, the flat index has a smaller set of moving parts.
That smaller operational surface makes flat search especially useful when teams are still learning what their retrieval workload looks like. Once the system has real queries, measured latency, and a clear relevance target, the flat index can become more than a simple implementation choice. It can become the reference point for evaluating every faster method.
Using a Flat Index as a Ground-Truth Oracle for Benchmarking
In vector search benchmarking, a flat index is often used as a ground-truth oracle. That means it produces the exact nearest-neighbor results that other indexes are judged against. If an approximate index returns results quickly, the benchmark still needs to answer a basic question: how many of the true nearest neighbors did it find?
The flat index provides that reference set. A benchmark can run exact search for a group of test queries, store the true top-k neighbors for each query, and then compare approximate index results against those exact results. This makes it possible to measure recall at k, latency, throughput, memory use, and build time in a structured way.
For example, suppose exact flat search says the true 10 nearest vectors for a query are A, B, C, D, E, F, G, H, I, and J. An approximate index returns A, B, D, E, F, G, H, K, L, and M. It returned 7 of the true 10, so recall at 10 is 70 percent for that query. Across many queries, the team can calculate average recall and compare it with search latency.
This benchmarking role is one reason flat indexes remain important even in systems that cannot use them for every production query. They help teams tune approximate search parameters, test new embedding models, compare indexing strategies, evaluate filtering behavior, and detect regressions after changes to infrastructure or ranking logic.
Without an exact baseline, it is easy to mistake speed for quality. An approximate index might return results very quickly, but if it misses too many true nearest neighbors, downstream retrieval-augmented generation or recommendation quality may suffer. Flat search gives teams a stable way to separate retrieval speed from retrieval correctness.
Once a benchmark reveals the tradeoff between speed and recall, the remaining design question is practical: should a production system keep the flat index, move to an approximate index, or use both in different parts of the workflow?
Flat Indexes Compared With Approximate Indexes
Flat indexes and approximate indexes solve the same basic problem, but they optimize for different priorities. A flat index optimizes for correctness, simplicity, and easy evaluation. Approximate indexes optimize for speed and scale by reducing the number of vector comparisons needed per query.
The difference is easiest to understand as a tradeoff table:
| Factor | Flat Index | Approximate Index |
|---|---|---|
| Search behavior | Compares against every candidate vector | Searches a selected subset or structure |
| Recall | Perfect recall for the chosen metric and candidate set | Usually less than perfect, depending on tuning |
| Build step | Minimal or none beyond storing vectors | Often requires graph construction, clustering, training, or compression |
| Query speed at large scale | Slower because work grows with candidate count | Usually faster because fewer candidates are checked |
| Operational complexity | Lower | Higher because parameters and rebuild behavior matter |
| Best use | Small datasets, filtered subsets, evaluation, and exact baselines | Large-scale, high-throughput, latency-sensitive retrieval |
In many real systems, the best answer is not purely one or the other. A team may use flat search during development, keep it for small tenants or highly filtered queries, and use approximate search for large collections. They may also keep a flat path offline to generate ground truth for regression tests and benchmark reports.
Choosing between these options is easier when the decision is tied to measurable requirements rather than assumptions. The next section turns the tradeoff into practical guidance for AI database projects.
Practical Guidance for AI Database Teams
A flat index is a strong default when correctness, simplicity, and observability matter more than maximum scale. It is especially helpful early in a project because it gives teams a clean baseline for understanding retrieval behavior. If exact search is already fast enough, an approximate index may add complexity without improving the user experience in a meaningful way.
Start by measuring the actual candidate set size after filters. Many applications do not search the entire database for every query. A multi-tenant system may search only one customer at a time. A coding assistant may search one repository or one branch. A document assistant may search one workspace, one folder, or one access-control group. If filtering reduces the active set enough, flat search may remain practical longer than expected.
Next, measure end-to-end latency rather than vector scoring alone. Retrieval pipelines often include embedding generation, metadata filtering, result hydration, reranking, prompt construction, and language model calls. If those steps dominate latency, replacing flat search with ANN search may produce only a small visible improvement.
When approximate search becomes necessary, keep exact search in the evaluation workflow. Use flat results to measure recall, tune index parameters, and monitor whether changes to embeddings or indexing logic affect retrieval quality. This prevents the system from optimizing only for speed while silently reducing the quality of retrieved context.
Finally, remember that perfect nearest-neighbor recall is not the same as perfect application relevance. A healthy evaluation process should include exact recall against a flat baseline and task-level relevance checks that reflect what users actually need from the system.
With these ideas in place, the flat index becomes less like a primitive fallback and more like a dependable tool. It is simple, exact, and useful both for production workloads that fit its limits and for evaluating the approximate methods used when those limits are exceeded.
FAQs
1. What is a flat index in vector search?
A flat index is a vector search method that stores vectors directly and compares each query vector against every candidate vector. It does not use graph shortcuts, clustering, compression, or probabilistic routing. Because it checks all candidates, it returns the exact nearest neighbors for the chosen distance metric and candidate set.
2. Why is a flat index called brute force?
It is called brute force because it solves nearest-neighbor search by exhaustive comparison. Instead of trying to narrow the search space with an index structure, it computes the similarity or distance between the query and every eligible stored vector, then ranks the results.
3. Does a flat index always have perfect recall?
A flat index has perfect recall relative to the stored vectors, selected metric, and active filters because it evaluates every eligible candidate. However, perfect recall does not guarantee perfect semantic relevance. If the embeddings, chunking, or source data are poor, exact search can still return results that are mathematically nearest but not useful to the user.
4. When is brute-force vector search fast enough?
Brute-force search can be fast enough for small or medium candidate sets, low-query-volume systems, filtered retrieval, prototypes, offline evaluation, and workflows where exactness matters more than very low latency. The best way to decide is to measure latency and throughput using realistic query volume, vector dimensions, filters, and hardware.
5. Why do teams use flat search for benchmarking?
Teams use flat search for benchmarking because it produces the exact nearest-neighbor results. Those results become the ground truth for measuring approximate indexes. By comparing approximate results with flat results, teams can calculate recall, tune parameters, and understand the tradeoff between speed and quality.
6. Should production AI applications use flat indexes?
Some production AI applications can use flat indexes successfully, especially when datasets are small, filters reduce the candidate set, or query volume is modest. Larger, high-traffic systems often use approximate indexes for speed, while still keeping flat search for testing, evaluation, and ground-truth comparisons.
Takeaway
A flat brute-force index is the most direct form of vector search: it compares the query with every candidate, returns exact nearest neighbors, and avoids complex index-building steps. It is most useful for teams working with small or filtered datasets, early-stage retrieval systems, high-accuracy workflows, and benchmark pipelines that need a trustworthy ground-truth oracle. For large-scale RAG, recommendation, semantic search, or AI memory systems, flat search is often the baseline that teaches you what correct retrieval looks like before you decide how much approximation you can safely introduce.
Watch this video to learn more