DiskANN is a graph-based approximate nearest neighbor search approach designed to make very large vector indexes searchable from SSD instead of requiring the whole index to live in RAM. Its key idea is to keep the heavy parts of the index, including the graph and full-precision vectors, on disk while keeping a compact in-memory guide that helps each query choose which graph neighborhoods are worth reading. This combination lets DiskANN reduce random SSD reads, preserve high recall, and support billion-scale vector search on hardware that would be too small for a fully in-memory graph index.
This guide explains how DiskANN works from the storage layout up: why a disk-resident graph index matters, how compressed in-memory vectors guide the search, how beam search and caching reduce SSD round trips, and why these design choices make billion-scale search practical on modest single-node systems. By the end, you should understand DiskANN not as a single optimization, but as a coordinated design for balancing memory cost, SSD latency, recall, and throughput in AI database workloads.
Why Billion-Scale Vector Search Is Hard
Vector search systems store embeddings that represent text, images, products, documents, users, or other data as high-dimensional numerical vectors. A query is also converted into a vector, and the system tries to find stored vectors that are closest to it. This is the basis of many AI database workloads, including semantic search, recommendation, retrieval-augmented generation, deduplication, and multimodal retrieval.
The difficulty is scale. A million vectors may fit comfortably into memory on many machines, but a billion vectors changes the economics. If each vector has hundreds or thousands of dimensions, storing all full-precision vectors plus a high-quality graph index in RAM can require far more memory than a practical single server has. Even when it is technically possible, the cost of DRAM-heavy deployments can become the limiting factor.
Approximate nearest neighbor search reduces the work by avoiding a full scan. Instead of comparing the query to every vector, the system uses an index to inspect a small fraction of promising candidates. Graph-based indexes are especially effective because they connect each vector to nearby vectors, allowing a search to start somewhere in the graph and walk toward better candidates. The tradeoff is that traditional graph indexes are usually designed to live in memory, where random access is cheap.
DiskANN addresses the central question that follows from this problem: can a graph index still deliver useful latency and recall if much of it lives on SSD? The answer depends on avoiding the naive version of disk search, where every graph step causes a separate random read and the query spends most of its time waiting on storage.
The Core Idea Behind DiskANN
DiskANN separates the index into two cooperating layers. The large, exact, storage-heavy layer lives on SSD. The smaller, approximate, guidance layer lives in RAM. During search, the in-memory layer helps the system decide which graph nodes are most promising, while the disk layer provides the real graph neighborhoods and full-precision vector data needed to expand and finalize the search.
This design matters because SSDs are much cheaper per byte than RAM, but they are slower for random access. DiskANN does not pretend SSD reads are free. Instead, it treats each read as something valuable and designs the graph, layout, and traversal algorithm around minimizing the number of reads and the number of storage round trips on the critical path of a query.
The result is a hybrid index. It is not a simple compressed index that sacrifices too much accuracy, and it is not a fully in-memory graph that requires expensive hardware at very large scale. It uses compression to guide search, disk storage to hold the full index, and a graph structure that is shaped to reduce the number of hops needed to reach strong candidates.
Once that separation is clear, the next piece is the graph itself. DiskANN depends on a graph that is sparse enough to store efficiently, but navigable enough that a query can reach the right region in only a small number of expansions.
Disk-Resident Graph Index
The disk-resident graph is the backbone of DiskANN. Each vector is represented as a node, and each node stores links to a bounded number of neighboring nodes. At query time, the search expands promising nodes by reading their neighbor lists from SSD. Those neighbor lists tell the search where it can move next in the graph.
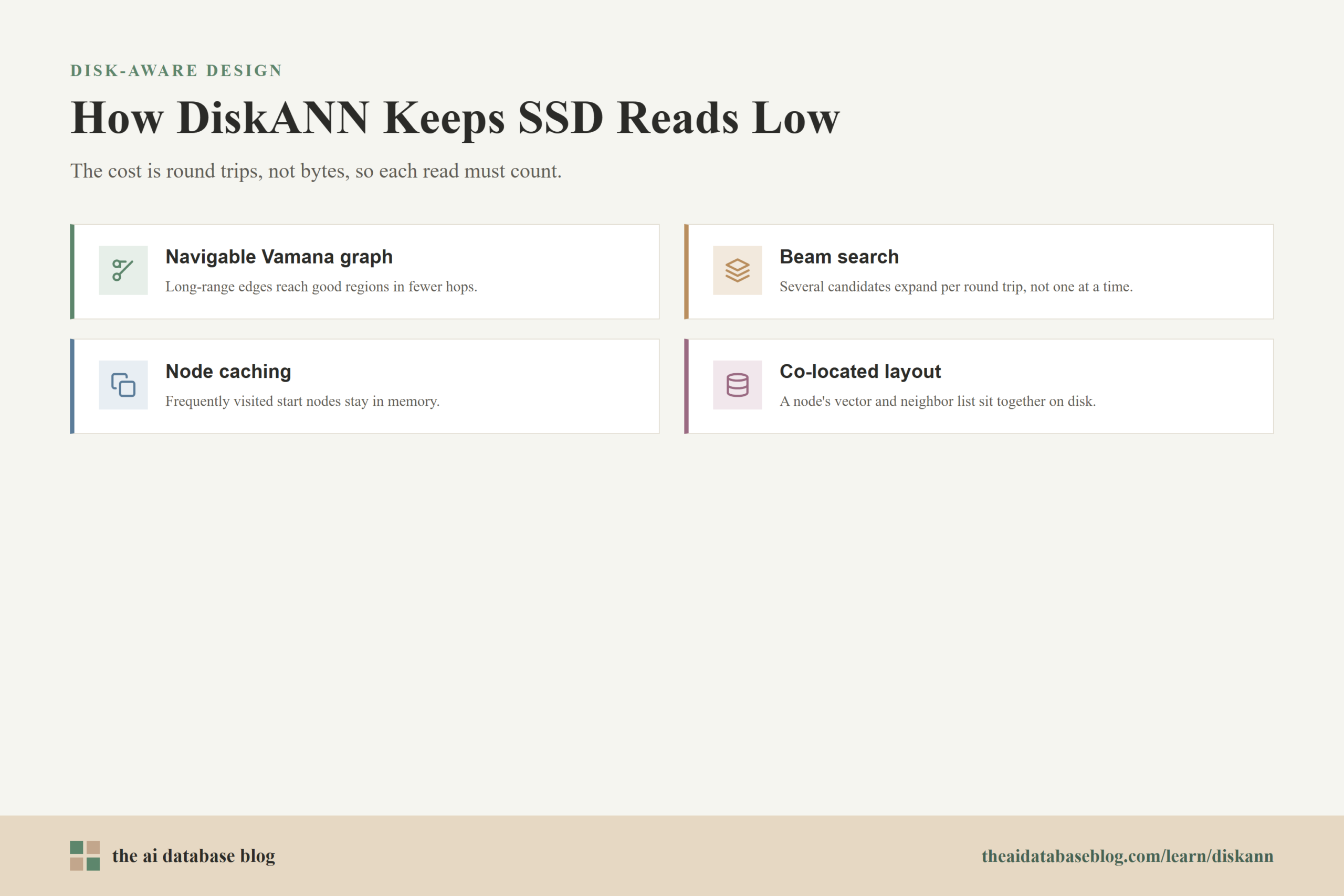
The original DiskANN work introduced the Vamana graph construction approach to make this disk-based traversal practical. Vamana is designed to create a navigable graph with useful long-range connections, not just short local links. Long-range edges reduce the number of graph hops needed to move from a starting point toward the query’s true nearest neighbors. This is especially important on SSD because each hop can involve disk I/O.
A useful way to think about this is to compare two graph shapes. A graph with only local links may eventually reach the right answer, but it can require many small moves. That is tolerable in RAM, where each access is fast, but painful on SSD. A graph with carefully chosen long-range links can take fewer, more meaningful steps, which reduces the number of times the search needs to wait for storage.
DiskANN stores the graph on disk along with full-precision vector data. For each node, the disk layout can place the node’s full vector and its neighbor identifiers close together. This allows the system to retrieve the information it needs for both graph expansion and later exact scoring without scattering the query across many unrelated disk locations.
A disk-resident graph alone is still not enough. The search also needs a way to rank candidate nodes before deciding which neighborhoods are worth reading. That is where the compressed in-memory guide becomes the practical control layer for the whole system.
Compressed In-Memory Guide
DiskANN keeps compressed representations of the dataset vectors in memory. These compressed vectors are much smaller than the full-precision vectors, so they can fit in RAM even when the complete graph and exact vectors cannot. Product quantization is the common technique associated with this idea: it represents vectors using compact codes that allow approximate distance calculations.
The in-memory guide does not replace the disk-resident index. Instead, it helps the search make fast decisions about which candidates look promising. When the query is compared against compressed vector codes, the system can estimate which candidates are closer without loading every candidate’s full vector from SSD. This keeps the query from wasting disk reads on obviously poor paths.
The important tradeoff is that compressed distances are approximate. Compression saves memory, but it introduces some error. DiskANN handles that by using compressed vectors mainly to guide traversal, while keeping full-precision vectors on SSD for final scoring and reranking. In other words, the compressed guide helps decide where to look, but the final answer can still be judged using the more accurate data.
This division is a major reason DiskANN can offer high recall without keeping everything in RAM. A purely compressed in-memory system may be fast and compact, but it can lose accuracy when the compressed distances blur the true nearest neighbors. DiskANN uses compression for navigation while preserving access to exact vectors when it matters most.
The next question is how the system uses this guide without turning each graph step into a slow disk wait. The answer is in DiskANN’s search procedure, which batches carefully chosen reads instead of walking the graph one storage request at a time.
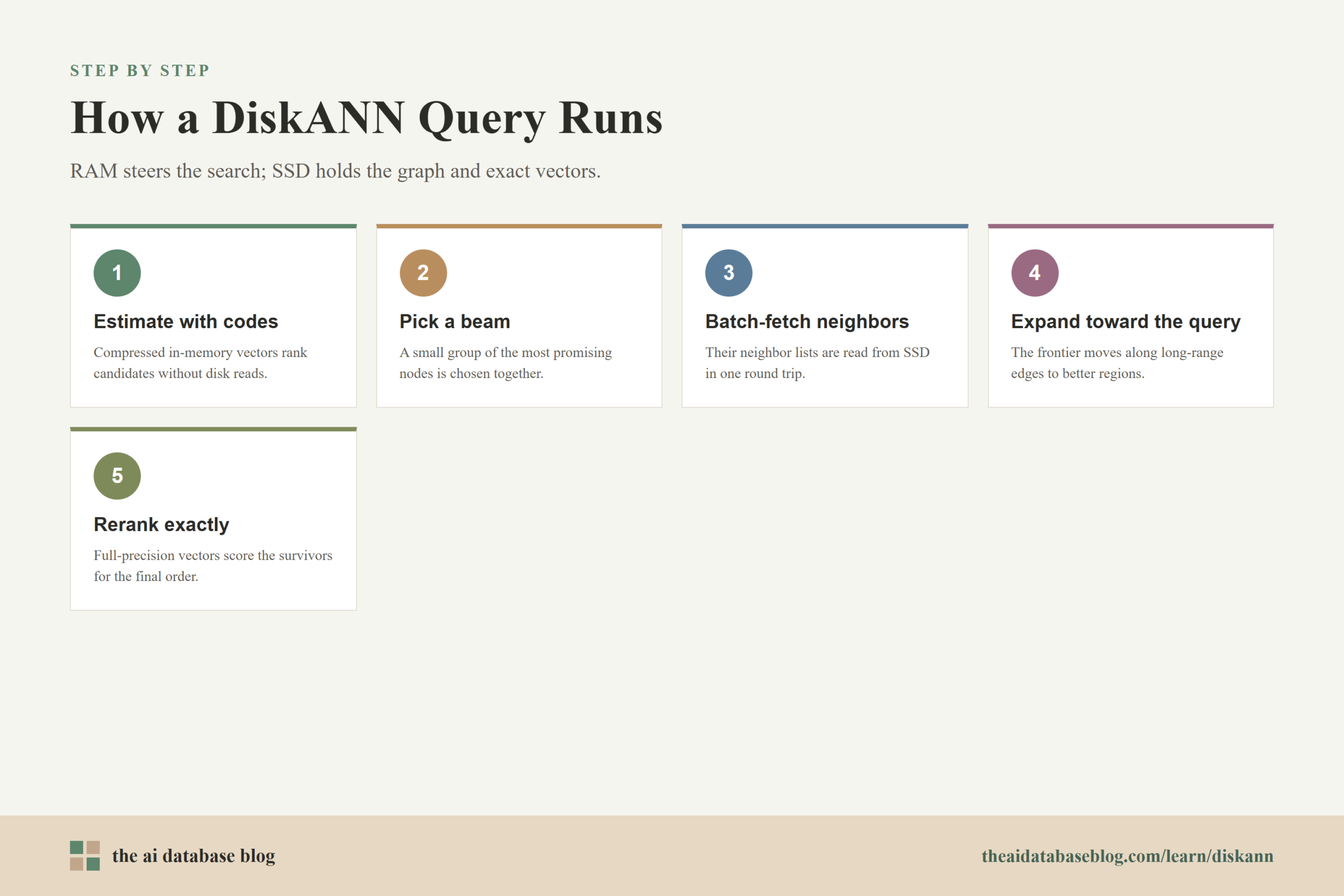
How DiskANN Minimizes SSD Reads
SSD performance is not only about how much data is read. For graph search, the bigger issue is often how many random reads and round trips the query requires. A naive graph traversal might read one node’s neighborhood, update its candidate list, read the next node’s neighborhood, and repeat this many times. Even on a fast SSD, that pattern can make latency unacceptable.
DiskANN reduces this cost through beam search. Instead of expanding only one candidate at a time, it selects a small group of promising candidates from the search frontier and fetches their neighborhoods together. This increases the amount of useful work done per storage round trip. The beam width has to be tuned carefully: too small, and the search waits on too many sequential reads; too large, and it wastes SSD bandwidth and CPU work on candidates that are unlikely to help.
The graph structure also reduces reads. Because Vamana is built to lower the number of hops needed for search convergence, DiskANN can reach useful neighborhoods with fewer graph expansions. That means fewer rounds where the query has to ask the SSD for more neighbor lists. The graph design and the search algorithm are therefore linked: the graph makes short paths possible, while beam search makes each path expansion more efficient.
Caching adds another layer of read reduction. DiskANN can keep frequently visited nodes in memory, especially nodes near the search starting point or nodes that are likely to appear in many queries. These cached nodes let early search steps happen without disk access, which is valuable because many graph traversals begin from the same small area before moving toward query-specific regions.
Disk layout matters too. By storing each node’s full vector close to its neighbor list, DiskANN can fetch data that supports both traversal and later reranking in the same read pattern. This avoids a separate wave of random reads just to recover exact vector values for candidates that have already been visited.
These techniques work together to change the cost model. DiskANN still uses SSD, and SSD is still slower than RAM for random access. But the system is arranged so each query performs a small, controlled number of useful reads rather than an uncontrolled chain of storage misses.
How Full-Precision Reranking Preserves Accuracy
Approximate distance estimates are good enough to guide the search, but they are not always good enough to decide the final top result. Two candidate vectors may look nearly tied under compression even though one is clearly closer under full precision. If the system returned results using only compressed distances, recall could suffer, especially in high-recall applications.
DiskANN avoids this by using full-precision vectors stored on SSD for final reranking. As beam search visits graph nodes, it can retrieve full vector data along with the node’s neighborhood information. That means the system can collect exact vector values for candidates it has already touched without needing a large extra set of random reads at the end.
This design is subtle but important. Many large-scale vector search systems use compression, but compression alone creates an accuracy ceiling because the system never sees the true distances for enough candidates. DiskANN uses compressed vectors as a fast steering mechanism, then brings full-precision data back into the decision path for the candidates that survived traversal.
For AI database users, this means DiskANN’s value is not just lower memory usage. It is the ability to combine a compact memory footprint with high-quality final ranking. That combination is what makes it useful for workloads where the nearest neighbor quality affects downstream application behavior, such as retrieving grounding passages for generation or finding semantically similar records.
With the search path and reranking behavior in place, the remaining question is scale. DiskANN becomes especially interesting because these techniques are aimed at billion-vector collections that would otherwise push teams toward much larger memory-heavy clusters.
How DiskANN Enables Billion-Scale Search on Modest Hardware
The original DiskANN evaluation showed that a billion-point dataset could be indexed, stored, and searched on a single workstation with limited RAM and SSD storage. The reported results are important because they challenge the assumption that high-recall graph-based vector search must keep the entire graph and all vectors in memory. DiskANN makes the SSD part of the serving path while keeping the number of SSD operations low enough for millisecond-level search in the evaluated setting.
The modest-hardware advantage comes from moving the largest structures out of RAM. Full-precision vectors and graph neighborhoods dominate storage at billion scale, so placing them on SSD dramatically reduces the amount of DRAM required. The in-memory compressed guide remains large, but it is much smaller than the complete full-precision dataset plus graph.
DiskANN also supports large index construction by building smaller graph indexes over overlapping partitions and then merging their edges into one graph. This avoids requiring the full billion-point build to happen entirely in memory on the target serving machine. The overlapping partitions preserve enough connectivity that search can still move across the merged graph effectively.
For AI database architecture, this changes deployment choices. A team may not need to shard a billion-vector collection across many RAM-heavy nodes just to make graph search possible. Depending on workload, recall target, dimensionality, update pattern, and SSD performance, a disk-aware index can support much larger collections per machine than a conventional in-memory graph index.
This does not make hardware irrelevant. SSD quality, CPU parallelism, memory bandwidth, vector dimensionality, query concurrency, and target recall all still matter. DiskANN’s point is more practical: when the index is designed for SSD access from the beginning, billion-scale search can become a single-node or small-cluster engineering problem rather than an automatic large-memory-cluster problem.
Where DiskANN Fits in AI Database Design
DiskANN is best understood as an indexing strategy for large-scale approximate nearest neighbor search, not as a complete AI database by itself. An AI database still needs ingestion, metadata handling, filtering, durability, replication, query planning, access control, observability, and operational tooling. DiskANN contributes a way to make vector index storage and search more efficient at very large scale.
It is especially relevant when the vector collection is too large for comfortable in-memory serving, but the application still needs high recall and low latency. Examples include semantic search over very large document collections, recommendation catalogs with many embeddings per item, image similarity search, and retrieval systems where exact candidate quality matters for downstream ranking or generation.
DiskANN is less obviously ideal for every workload. If the collection is small enough to fit easily in memory, an in-memory graph index may be simpler. If the workload needs extremely frequent updates, the system must handle freshness carefully because graph indexes have to maintain useful connectivity as vectors are inserted, changed, or deleted. If metadata filtering is central to every query, the database must combine vector traversal with predicate evaluation in a way that preserves both speed and recall.
The practical lesson is that storage hierarchy should shape index design. RAM is excellent for fast navigation, SSD is economical for large persistent structures, and compression is useful when it guides decisions without becoming the only source of truth. DiskANN combines those ideas into a retrieval architecture that is particularly relevant for large AI data systems.
Practical Tradeoffs to Understand
DiskANN offers a strong design for billion-scale search, but it is still governed by tradeoffs. The most important one is recall versus latency. Higher recall usually requires a wider or deeper search, which can mean more candidate expansions, more distance calculations, and more SSD reads. Lower latency usually means tightening those limits, which can miss some true nearest neighbors.
Memory usage is another tradeoff. The compressed in-memory guide is much smaller than full-precision storage, but it is not free. At billion scale, even compact codes can occupy substantial RAM. Additional caches for frequently visited nodes also improve latency at the cost of memory. The right balance depends on query volume, desired latency, and the cost profile of the hardware.
Build complexity is also part of the picture. Creating a high-quality graph over a very large dataset is more involved than building a simple flat file or inverted list. Partitioning, overlapping assignments, graph construction parameters, merge behavior, compression settings, and search parameters all affect quality. DiskANN works because these parts are coordinated, which also means tuning matters.
Finally, SSD behavior matters in practice. The system depends on keeping storage reads controlled and useful. A deployment with slower storage, noisy I/O, poor queue behavior, or competing disk workloads may not match research-paper latency. DiskANN reduces SSD dependence, but it cannot eliminate the physical cost of storage access.
These tradeoffs do not weaken DiskANN’s usefulness. They clarify why it is important. DiskANN gives AI database builders a principled way to use SSD as part of the search path, but the best results come from matching the index configuration to the workload rather than treating disk-resident search as a drop-in replacement for every in-memory index.
FAQs
1. What is DiskANN?
DiskANN is a graph-based approximate nearest neighbor search approach designed for very large vector collections. It stores the main graph index and full-precision vectors on SSD while keeping compressed vector representations and selected cached data in memory. This lets it search collections that are much larger than RAM while still aiming for high recall and low latency.
2. Why does DiskANN use SSD instead of keeping everything in RAM?
At billion-vector scale, keeping full-precision vectors and a graph index entirely in RAM can be expensive or impractical. SSD storage is much cheaper per byte, so DiskANN moves the largest structures to disk. It then uses careful graph construction, compressed in-memory guidance, caching, and batched reads to avoid the worst latency problems of random SSD access.
3. What is the compressed in-memory guide in DiskANN?
The compressed in-memory guide is a compact representation of dataset vectors, often based on product quantization. It allows the system to estimate distances between the query and candidate nodes without reading every candidate’s full vector from disk. These approximate distances guide the graph traversal, while full-precision vectors can still be used later for reranking.
4. How does DiskANN reduce SSD reads?
DiskANN reduces SSD reads by using a graph with fewer search hops, expanding several promising candidates together through beam search, caching frequently visited nodes in memory, and laying out node data so neighbor lists and full vectors can be fetched efficiently. The goal is to make each disk read useful and to keep the number of storage round trips small.
5. Is DiskANN accurate if it uses compressed vectors?
DiskANN uses compressed vectors mainly for navigation, not as the only basis for final answers. During traversal, approximate distances help choose promising graph nodes. For final ranking, full-precision vectors stored on SSD can be used to score candidates more accurately. This helps preserve recall while still reducing memory usage.
6. When is DiskANN most useful?
DiskANN is most useful when a vector collection is too large to serve comfortably with a fully in-memory graph index, but the application still needs strong recall and low query latency. It is a good fit for large semantic search, recommendation, image retrieval, and retrieval-augmented generation systems where storage cost and search quality both matter.
Takeaway
DiskANN shows how billion-scale vector search can be made practical by designing the index around the storage hierarchy instead of assuming everything must live in RAM. The disk-resident graph stores the heavy structure, the compressed in-memory guide steers queries toward promising regions, beam search and caching minimize SSD reads, and full-precision reranking protects result quality. This guidance is most useful for AI database builders, search engineers, and retrieval system designers working with very large embedding collections, especially use cases such as semantic document retrieval or large catalog recommendation where high recall, predictable latency, and hardware efficiency all matter.
Watch this video to learn more