MTEB, short for Massive Text Embedding Benchmark, helps compare embedding models across many tasks such as retrieval, classification, clustering, semantic similarity, reranking, and multilingual matching. It is useful because it gives teams a shared benchmark instead of forcing them to rely on scattered model claims, but the leaderboard should be read as a starting point rather than a final answer. The best model overall is not always the best model for your domain, data shape, latency target, language mix, or retrieval application.
This guide explains what MTEB measures, how to interpret the leaderboard, why overall rank can be misleading for domain-specific AI database work, and how to choose an embedding model practically. By the end, you should understand how to use MTEB to narrow your options while still testing the models against the queries, documents, metadata filters, and relevance expectations that matter in your own system.
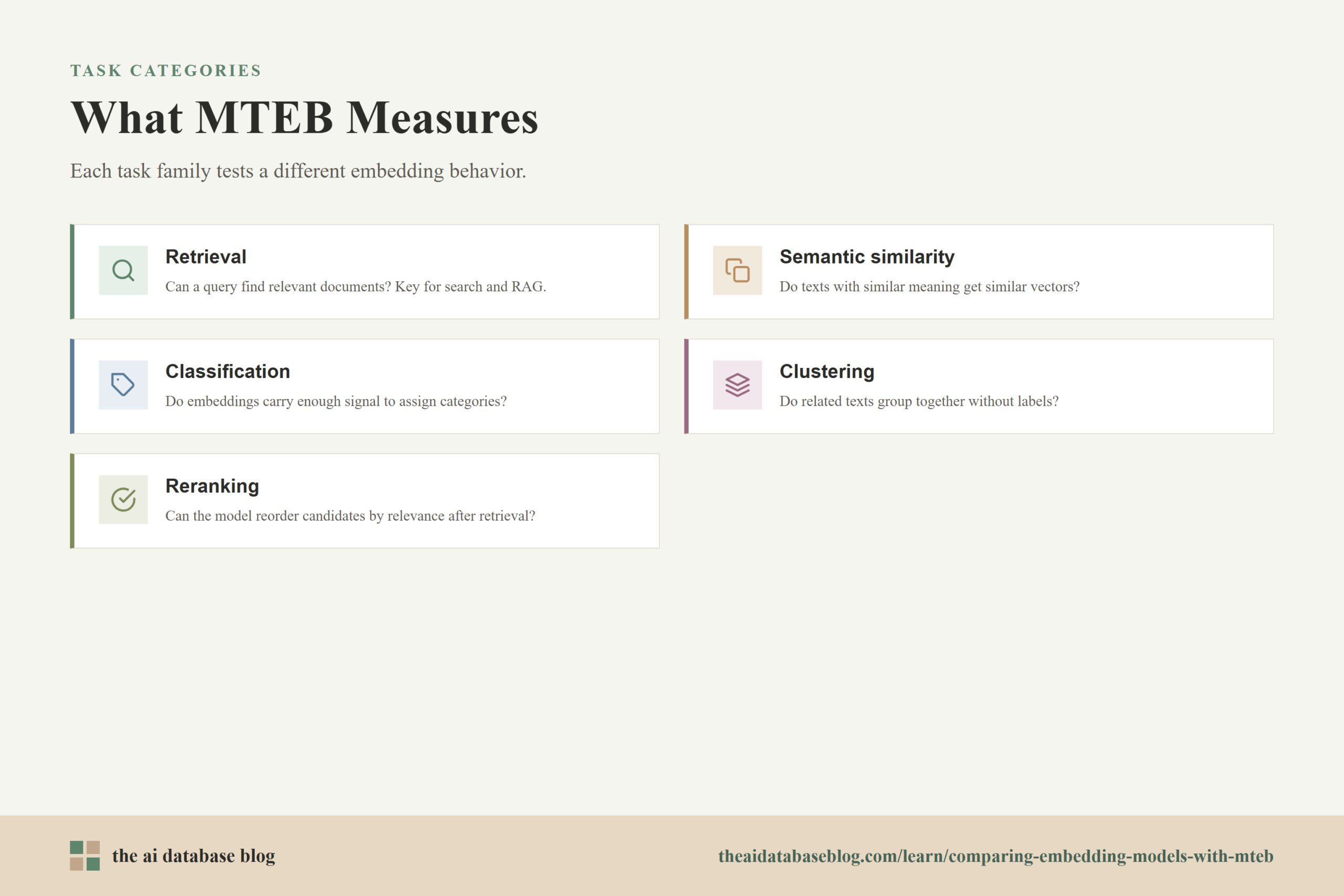
What MTEB Measures
MTEB measures how well text embedding models turn text into vectors that preserve useful meaning for downstream tasks. An embedding model is not judged by whether it produces fluent language, because it does not generate answers. It is judged by whether similar, relevant, or related pieces of text land near each other in vector space in ways that support search, grouping, comparison, and ranking.
The original MTEB benchmark was designed to address a common problem in embedding evaluation: models were often tested on a narrow set of tasks, usually semantic textual similarity or one retrieval dataset, which made it hard to know whether a model was generally strong or only tuned for one kind of measurement. MTEB broadened the evaluation by covering multiple task families and many datasets. The MTEB ecosystem has continued to expand since then, including multilingual benchmarks and a continuously updated leaderboard.
The main task categories matter because each one tests a different kind of embedding behavior:
- Retrieval measures whether a query embedding can find relevant documents from a larger collection. This is usually the most important category for AI databases, semantic search, and retrieval-augmented generation.
- Semantic textual similarity measures whether two pieces of text that mean similar things receive similar vector representations.
- Classification measures whether embeddings contain enough signal for a classifier to assign text to the right category.
- Clustering measures whether related texts naturally group together without explicit labels.
- Reranking measures whether a model can help order candidate results by relevance after an initial retrieval step.
- Pair classification measures whether a model can help decide relationships between two texts, such as duplicate or non-duplicate pairs.
- Bitext mining measures whether translated or equivalent texts across languages can be matched.
- Summarization-related evaluation measures whether embeddings can capture similarity between summaries and source content in benchmark-specific ways.
Because these task types are different, a single average score can hide important variation. A model may be excellent for sentence similarity but only average for retrieval. Another model may be strong for English search but weaker for multilingual matching. MTEB is valuable because it exposes those differences, but users still need to inspect the parts of the benchmark that match their application.
Once you understand what MTEB measures, the next question is how to read the leaderboard without overreacting to the top row. The leaderboard is packed with useful signals, but those signals only become meaningful when you connect them to the kind of AI database workload you are building.
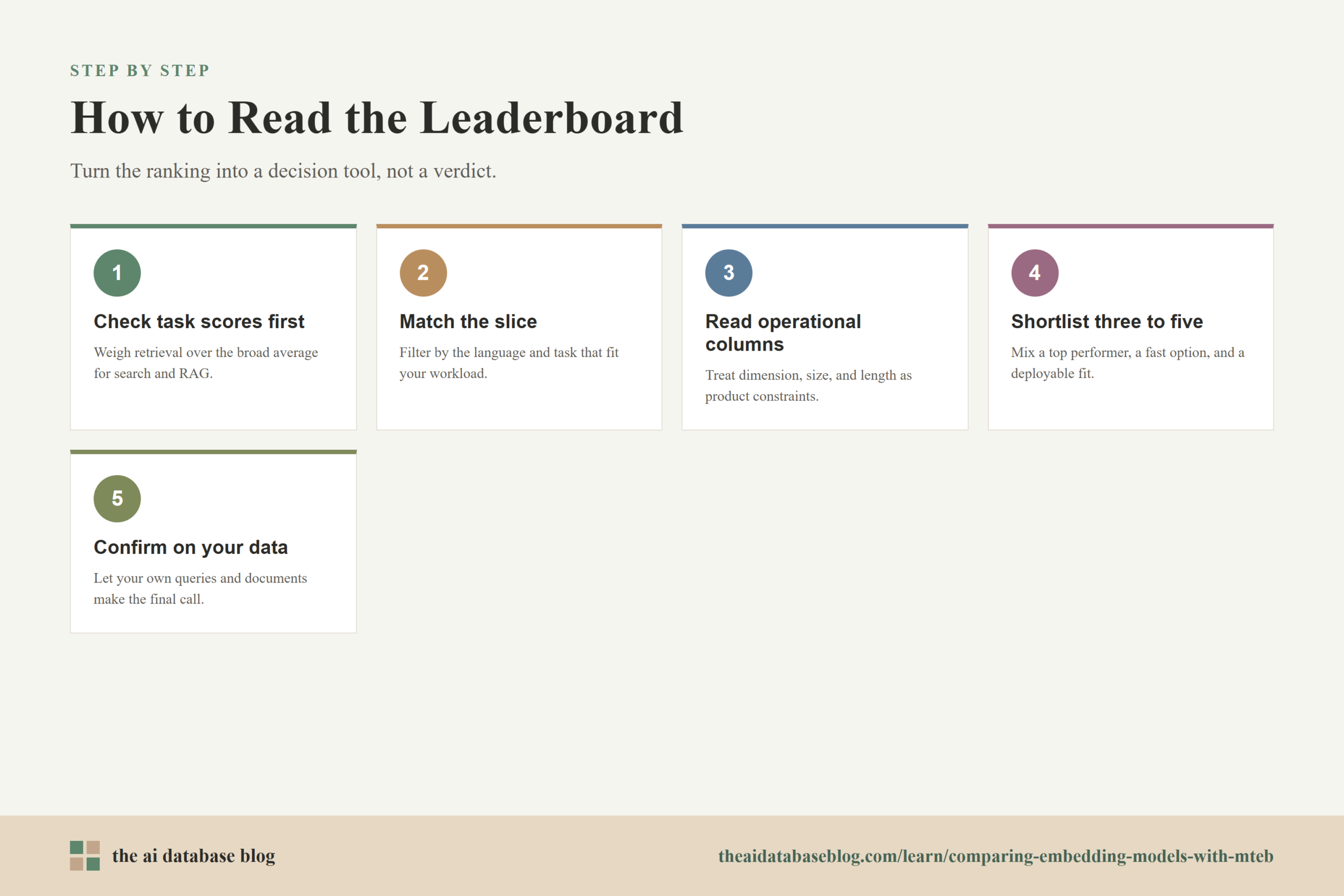
How to Interpret the MTEB Leaderboard
The MTEB leaderboard is best understood as a structured comparison table, not a universal model selector. It gives you model scores across benchmark tasks and often includes practical metadata such as model size, embedding dimensions, sequence length, supported languages, and whether results come from a particular benchmark version. These details can matter as much as the headline score when you are choosing a model for production.
The overall score is typically an average across tasks or task groups. It is helpful for quickly identifying strong general-purpose models, but it does not tell you which model will work best for a specific retrieval system. For AI database use cases, you should look first at retrieval-related scores, then examine the model’s operational fit: embedding dimension, latency, cost, deployment requirements, maximum input length, and support for the languages in your content.
Look at Task-Specific Scores Before Overall Rank
If your system is a semantic search or RAG application, retrieval performance should carry more weight than a broad average. Retrieval tasks usually evaluate whether relevant documents appear high in the ranked results, often using metrics such as normalized discounted cumulative gain at rank 10, commonly written as nDCG@10. In plain terms, nDCG@10 rewards systems that place highly relevant results near the top of the first page of results.
For a support knowledge base, legal search system, research assistant, or product documentation chatbot, top-ranked relevant results are more important than whether the model clusters unrelated benchmark datasets well. Clustering and classification may still indicate useful semantic structure, but they should not dominate the decision if the production workload is retrieval-heavy.
Compare Models Within the Right Benchmark Slice
MTEB has expanded beyond its original English benchmark into broader multilingual and task-specific evaluations. That means a model’s position can change depending on the leaderboard view, benchmark version, language selection, and task filter. A model that looks excellent on English-only tasks may not be the best choice for a multilingual customer support system. A model that performs well on broad multilingual averages may not be the best fit for one specialized language or domain.
When comparing models, use the leaderboard filters deliberately. Match the benchmark slice to your use case before interpreting rank. For example, compare retrieval scores for English documentation search if that is your application. Compare multilingual retrieval or bitext mining if your content crosses languages. Compare classification only if your embedding layer will feed a classifier or routing system.
Read Operational Columns as Product Constraints
The model with the highest score can still be a poor fit if it is too large, slow, expensive, or difficult to deploy. Embedding dimensions affect storage size and vector search memory usage. Model size affects latency and infrastructure cost. Maximum token length affects how much text can be embedded in one pass. Licensing and hosting requirements affect whether the model can be used in your environment.
In an AI database, these constraints compound. A larger embedding dimension can increase index size and search cost across millions of objects. A slower model can make ingestion pipelines lag behind source data updates. A model with a short context window may require more aggressive chunking, which can change retrieval behavior. Leaderboard performance is only one piece of the system design.
Interpreting the leaderboard this way turns MTEB from a ranking contest into a decision tool. The next step is understanding why a model that wins broadly may still lose on your own documents, queries, and relevance judgments.
Why Top Overall Is Not Always Best for Your Domain
The top overall model on MTEB is the model that performs best across the benchmark’s selected mix of tasks, datasets, and metrics. Your application is almost never that exact mix. A production AI database usually has its own document types, query patterns, metadata rules, chunking strategy, language distribution, and definition of relevance. Those differences can easily change which embedding model performs best.
This is not a flaw in MTEB. It is a reminder that benchmarks are compressed representations of reality. They help you avoid weak choices, but they cannot fully simulate your data. A benchmark score is most useful when it tells you which models deserve local evaluation, not when it replaces local evaluation altogether.
Domain Vocabulary Can Change the Ranking
Specialized domains often use words differently than general datasets do. In medicine, finance, law, engineering, security, and scientific research, small wording differences can carry major meaning. A general embedding model may understand ordinary semantic similarity well while missing the distinctions that domain experts care about.
For example, a model may treat two technical phrases as close because they share general wording, even though one refers to a procedure, another refers to a risk, and a third refers to a regulatory requirement. In a domain-specific retrieval system, those distinctions affect whether users trust the results. MTEB can identify broadly capable models, but domain evaluation is needed to test this kind of precision.
Your Query Pattern May Not Match the Benchmark
Many benchmark queries are clean, self-contained, and paired with known relevance labels. Real users often ask messy questions. They use abbreviations, incomplete references, internal terminology, long natural-language questions, pasted error messages, or vague descriptions of what they need. In RAG systems, queries may also be rewritten by another model before retrieval, which changes the embedding task again.
A model that performs well on benchmark retrieval may still struggle if your users ask long, multi-part questions or if your content contains tables, code snippets, transcripts, contracts, or semi-structured records. The gap is not simply about model quality. It is about whether the benchmark task resembles the work your embedding model will actually do.
Chunking and Metadata Filtering Affect Results
Embedding models do not operate alone inside an AI database. They are part of a retrieval pipeline that includes chunking, metadata filtering, indexing, similarity search, hybrid search, reranking, and response generation. A model that looks slightly better in isolation may perform worse after chunking changes the document context or metadata filters narrow the candidate set.
For example, if your documents are long and the model has a limited input length, you may need smaller chunks. Smaller chunks can improve precision but lose context. Larger chunks can preserve context but dilute the signal in the vector. MTEB does not know your chunking policy, so local testing must evaluate the model as part of the full retrieval pipeline.
Latency, Cost, and Storage Can Matter More Than a Small Score Difference
A small leaderboard score difference may not justify a large operational penalty. If two models perform similarly on the relevant MTEB slice, the better production choice may be the one that embeds faster, costs less, uses fewer vector dimensions, supports your deployment environment, and keeps retrieval quality stable after compression or quantization.
This matters especially at scale. If you embed millions of documents, re-embed frequently, or serve low-latency search, the operational profile becomes part of model quality. A model that is easier to run can enable more frequent updates, broader testing, and faster iteration, which may produce better real-world retrieval than choosing the largest model solely because it ranks higher overall.
The practical lesson is that MTEB should narrow the field, not end the decision. Once you have a shortlist, the best selection process combines leaderboard evidence with small, realistic evaluations from your own AI database workload.
Practical Selection Advice for AI Database Teams
The most reliable way to choose an embedding model is to move from general evidence to local evidence. MTEB gives you the general evidence. Your own retrieval tests provide the local evidence. This approach keeps you from choosing blindly while also avoiding the trap of assuming that public benchmark rank automatically predicts production success.
A practical selection process does not need to be complicated at first. Start by defining the task, choosing a small group of candidates, testing them against representative queries, and measuring whether the results are useful to users. The goal is not to build a perfect benchmark immediately. The goal is to make the model choice visible, testable, and connected to application behavior.
Start With the Retrieval Job You Actually Need
Before looking at model names, describe the retrieval job in plain language. Are users searching product documentation, internal policies, research papers, tickets, contracts, code, support conversations, or mixed enterprise records? Are queries short keyword-like searches, full questions, multilingual requests, or natural-language descriptions of a problem?
This description tells you which MTEB scores matter most. For a RAG system over documentation, retrieval should be weighted heavily. For a deduplication workflow, pair classification or similarity may matter more. For multilingual search, language coverage and multilingual benchmark performance should be part of the shortlist. A good model choice starts with the job, not the leaderboard rank.
Build a Shortlist Instead of Picking One Winner
Use MTEB to identify three to five serious candidates. Include at least one high-performing model from the relevant task slice, one smaller or faster model, and one model that fits your deployment constraints especially well. This gives you room to compare quality against cost and latency instead of treating accuracy as the only variable.
When shortlisting, avoid comparing models only by overall rank. Check retrieval score, language support, embedding dimension, maximum input length, model size, licensing, and whether the model is practical to run where your system needs it. If the difference between two models is small on the relevant benchmark, operational fit may be the deciding factor.
Evaluate With Your Own Queries and Documents
Create a small evaluation set from real or realistic usage. A useful starting point might include 50 to 200 queries, the documents or chunks that should be retrieved, and notes about what counts as a good result. If exact labels are hard to create, start with a smaller manually reviewed set. It is better to have a modest evaluation that reflects your application than a large evaluation that measures the wrong thing.
Measure whether the right results appear near the top. For retrieval, useful metrics include recall at a chosen cutoff, precision at a chosen cutoff, mean reciprocal rank, and nDCG when you have graded relevance. Also inspect failures manually. The failure patterns often teach you more than a single score: the model may miss acronyms, overmatch generic wording, struggle with long chunks, or confuse related but distinct concepts.
Test the Full Retrieval Pipeline
Do not evaluate the embedding model in isolation if production will use hybrid search, metadata filters, reranking, or generated query rewriting. Test the model inside the same kind of pipeline users will experience. A model that performs well with pure vector search may behave differently when combined with keyword matching or a reranker.
For AI databases, also test ingestion and indexing behavior. Track embedding throughput, vector size, index build time, query latency, and memory usage. These numbers help you decide whether a slightly higher relevance score is worth the operational tradeoff. In many systems, the best choice is the model that gives strong enough relevance while keeping the retrieval pipeline fast, affordable, and easy to maintain.
Revisit the Choice as Data Changes
Embedding model selection is not a one-time decision. Your content changes, user behavior changes, benchmarks change, and new models appear. The MTEB leaderboard is updated over time, but your own evaluation set should also evolve as you learn where retrieval succeeds and fails.
A practical habit is to keep a small regression set of important queries. When you change the embedding model, chunking strategy, metadata schema, vector index settings, or reranker, rerun the same queries and compare results. This keeps model selection tied to user value rather than benchmark excitement.
With this process in place, MTEB becomes most useful as an external signal that feeds an internal evaluation loop. It helps you know where to look, while your own data tells you what to choose.
Common Mistakes When Using MTEB
MTEB is easy to misuse because the leaderboard is clear and tempting. A ranked table gives the impression that the decision has already been made for you. In practice, embedding model selection still requires judgment, especially when the model will sit inside an AI database where retrieval quality, system cost, and user trust all interact.
The most common mistakes come from reading a broad benchmark as if it were a production test. Avoiding these mistakes makes MTEB much more useful and reduces the risk of choosing a model that looks impressive in public results but underperforms in your application.
- Choosing only by overall rank. Overall rank is useful for discovery, but task-specific scores usually matter more for real systems.
- Ignoring retrieval metrics. For RAG and semantic search, retrieval performance should usually be the first benchmark slice you inspect.
- Forgetting operational constraints. Embedding dimension, latency, model size, and deployment requirements can outweigh small score differences.
- Assuming benchmark language coverage matches your users. Multilingual performance should be checked against the specific languages and scripts your application supports.
- Skipping local evaluation. Public benchmarks cannot fully represent your documents, queries, chunking, filters, and relevance standards.
- Testing embeddings apart from the pipeline. The final user experience depends on chunking, indexing, hybrid search, reranking, and generation, not embeddings alone.
These mistakes all point to the same conclusion: MTEB is strongest when it is part of a selection workflow. It helps identify likely candidates, but the final decision should be based on how those candidates behave in the actual retrieval environment.
FAQs
1. What does MTEB stand for?
MTEB stands for Massive Text Embedding Benchmark. It is a benchmark and leaderboard for evaluating text embedding models across many tasks, datasets, and languages. Its purpose is to make embedding model comparison more standardized and less dependent on isolated claims from individual model releases.
2. Is the highest-ranked MTEB model always the best embedding model?
No. The highest-ranked model is the strongest according to the selected benchmark view and scoring method, but that does not guarantee it is best for your domain. Your application may care more about retrieval, multilingual performance, latency, storage cost, maximum input length, or specialized terminology than the overall average score.
3. Which MTEB scores matter most for RAG?
For retrieval-augmented generation, retrieval scores usually matter most because the embedding model’s main job is to find the right source chunks before an answer is generated. Metrics such as nDCG@10, recall at a chosen cutoff, and mean reciprocal rank are especially relevant when evaluating whether useful results appear near the top.
4. How many embedding models should I test after checking MTEB?
A practical starting point is three to five models. Include strong performers from the relevant MTEB task slice, a smaller or faster option, and any model that fits your deployment requirements especially well. This gives you enough comparison range without making the evaluation process too large to manage.
5. Why might a lower-ranked model perform better on my data?
A lower-ranked model may understand your domain vocabulary better, handle your query style more effectively, work better with your chunking strategy, or fit your language mix more closely. Public benchmarks use shared datasets, while your production system has its own documents, users, filters, and relevance expectations.
6. Should I fine-tune an embedding model instead of choosing from MTEB?
Fine-tuning can help when your domain has specialized language or when off-the-shelf models consistently fail on important retrieval cases. However, it is usually best to start by comparing strong existing models, improving chunking and retrieval settings, and building a clear evaluation set. Fine-tuning becomes more useful once you know exactly what failure patterns you are trying to fix.
Takeaway
MTEB is one of the most useful tools for comparing embedding models because it evaluates them across a broad set of tasks instead of relying on a single narrow test. For AI database teams, the best use of MTEB is to shortlist models by relevant task performance, especially retrieval, and then test those models on real documents, real queries, and real operational constraints. This guidance is most useful for teams building semantic search, RAG, support search, research assistants, or knowledge retrieval systems where the right model is the one that retrieves the most useful context reliably, not simply the one with the highest overall leaderboard score.
Watch this video to learn more