RAG systems usually fail for practical reasons: the right information is split badly, retrieved weakly, packed into the prompt poorly, outdated in the knowledge base, or ignored by the model during generation. The most reliable fixes are not vague prompt tweaks. They are specific improvements to chunking, retrieval, ranking, context assembly, freshness controls, and answer-grounding checks.
This guide explains the most common failure modes in retrieval-augmented generation systems and shows how to recognize and fix each one. It covers bad chunking, weak retrieval, context overflow, lost-in-the-middle behavior, stale data, and ignored context, with symptoms that help teams diagnose the problem before changing the wrong part of the system.

Why RAG Fails Even When the Model Looks Capable
A RAG system has more moving parts than a simple language model call. It has to ingest documents, split them into useful chunks, create searchable representations, retrieve the right evidence, rank that evidence, fit it into the model context, and instruct the model to answer from that context. A failure in any one of those steps can make the final answer look careless, incomplete, or fabricated.
The confusing part is that the final symptom often appears at the generation layer. A user sees a wrong answer and assumes the model failed. In many cases, however, the model never received the right evidence, received too much weak evidence, received evidence in an unhelpful order, or was asked a question that the retrieved material did not actually answer.
This is why RAG debugging should start by separating retrieval problems from generation problems. Before changing prompts or models, inspect whether the correct source document exists, whether it was indexed, whether the relevant chunk was retrieved, whether it was ranked high enough, and whether it survived the final context assembly step.
Once that diagnostic flow is clear, each failure mode becomes easier to isolate. The first place to look is usually chunking, because chunking determines what the retrieval system is even allowed to find.
Bad Chunking
Bad chunking happens when source content is split into units that are too small, too large, or disconnected from the way users ask questions. Since retrieval systems usually search chunks rather than full documents, chunk design affects both what gets retrieved and how useful the retrieved evidence is once it reaches the model.
Chunks that are too small may contain the answer but lack the surrounding definition, condition, table header, or exception needed to interpret it. Chunks that are too large may include the answer, but bury it among unrelated material. Fixed-size chunking can work for simple text, but it often breaks down when documents have headings, tables, policy exceptions, code blocks, legal clauses, product specifications, or multi-step procedures.
Symptoms of Bad Chunking
- The answer appears in the source document but not in the retrieved context. This often means the relevant text was split away from the terms or heading that would make it searchable.
- The retrieved chunk contains only half the answer. For example, it may include a rule but not the exception immediately below it.
- The model answers with vague summaries instead of precise facts. This can happen when chunks are broad sections with too much mixed content.
- Changing the model does not improve accuracy much. The model cannot reason over information that was separated or hidden before retrieval.
Concrete Fixes for Bad Chunking
Start with structure-aware chunking rather than purely mechanical splitting. Preserve headings, subheadings, table labels, list context, and document titles inside or alongside each chunk. If a section is long, split it at natural paragraph or subsection boundaries instead of cutting through a sentence or logical unit.
Add overlap only where it solves a real boundary problem. Overlap can help when definitions, constraints, and examples are close together, but too much overlap creates duplicate evidence and increases context noise. A useful test is to ask whether each chunk can answer a realistic user question without needing hidden neighboring text.
Use metadata to recover missing context. Store document title, section title, version, date, source type, access level, and product or topic identifiers with each chunk. This helps retrieval filter and rank results without forcing every chunk to carry a large amount of repeated text.
Finally, evaluate chunking with real queries. Create a small test set of representative user questions and check whether the correct chunk appears in the top retrieval results. If the same document performs well for some query types and poorly for others, consider adaptive chunking strategies that vary by document type or content structure.
Good chunking gives retrieval a fair chance, but it does not guarantee that the best chunks will be found. The next failure mode appears when the knowledge base contains the answer, yet the search layer retrieves the wrong evidence.
Weak Retrieval
Weak retrieval means the system fails to bring back the most useful evidence for the user query. This can happen even when the data is indexed correctly and the chunks are well designed. Retrieval depends on query wording, embedding quality, keyword coverage, metadata filters, ranking logic, and whether the user question is clear enough to search against the knowledge base.
A common mistake is relying on a single retrieval method for every query. Dense vector search is good at semantic similarity, so it can find conceptually related content even when the wording differs. Keyword search is often better for exact names, IDs, error codes, policy numbers, quoted phrases, and rare terms. Many production RAG systems need a hybrid approach because user questions mix conceptual intent with exact constraints.
Symptoms of Weak Retrieval
- Retrieved chunks are topically related but do not answer the question. The system finds content in the right neighborhood but misses the exact fact.
- Exact terms disappear from results. Product names, technical fields, IDs, dates, or uncommon phrases may be underweighted by semantic search alone.
- The top result is weaker than lower-ranked results. This points to a ranking or reranking problem rather than a pure indexing problem.
- Multi-part questions retrieve evidence for only one part. The query may need decomposition into smaller searches.
Concrete Fixes for Weak Retrieval
Use hybrid retrieval when queries contain both meaning and exact terms. Combining semantic search with keyword search can improve coverage because each method compensates for the other. Semantic search helps with paraphrases and conceptual matches, while keyword search protects exact identifiers and specialized vocabulary.
Add a reranking step when the first retrieval pass returns plausible but uneven results. A retriever can gather candidates broadly, while a reranker can compare those candidates more carefully against the original question. This is especially useful when documents are similar, when many chunks share repeated terminology, or when the most relevant evidence is not the most semantically generic result.
Rewrite or expand queries when users ask vague, conversational, or multi-turn questions. A query such as “Does this apply to contractors?” may need conversation history or a rewritten search query that includes the policy, region, or document type being discussed. For complex questions, decompose the query into subquestions, retrieve evidence for each one, and merge the results before generation.
Measure retrieval quality directly. Track recall at a chosen result count, precision of retrieved context, and whether the expected source appears in the final context. Do not judge retrieval only by the final answer, because generation can sometimes hide retrieval weakness and sometimes make retrieval look worse than it was.
Once retrieval is strong enough, the next risk is overloading the model with too much of it. More retrieved text can improve recall, but after a point it can crowd out the answer and make the model less focused.
Context Overflow
Context overflow happens when the system retrieves or assembles more information than the model can use effectively. This is not only about exceeding the model’s technical context window. A prompt can fit within the limit and still contain too much repetitive, conflicting, weakly ranked, or irrelevant material for the model to answer reliably.
Long context windows make it tempting to include every possibly relevant chunk. That approach can reduce the chance of missing evidence, but it increases noise. The model has to decide which passages matter, which passages conflict, and which instructions should dominate. If context assembly is careless, RAG becomes a pile of documents rather than a focused evidence package.
Symptoms of Context Overflow
- The answer gets worse when more chunks are added. This is a sign that extra context is adding noise rather than useful evidence.
- The model blends unrelated sources. It may combine facts from different products, time periods, customers, or document types.
- Important evidence is present but surrounded by distractions. The model may mention secondary details while missing the central answer.
- Latency and cost rise without a clear accuracy gain. Large context assembly can become expensive while reducing focus.
Concrete Fixes for Context Overflow
Set a context budget based on evidence quality, not just token capacity. Use retrieval scores, reranker scores, metadata filters, source freshness, and source authority to decide what enters the prompt. The goal is not to include the most text; it is to include the strongest evidence.
Deduplicate and compress context before generation. Remove near-duplicate chunks, repeated boilerplate, navigation text, stale versions, and low-information passages. When long sections are necessary, summarize them into answer-relevant notes only if the summarization step preserves source traceability and does not replace evidence with unsupported interpretation.
Use a staged retrieval pattern for broad questions. First retrieve candidates, then rerank or classify them, then assemble a smaller final context. For multi-hop questions, retrieve evidence for each subquestion instead of relying on one large undifferentiated result set.
Keep the final prompt organized. Put the user question, task instructions, and source excerpts in predictable sections. Include source names and metadata with each excerpt so the model can distinguish which evidence came from where. Clear context packaging reduces the chance that the model treats all retrieved text as equally relevant.
Even when the prompt is under budget and the right evidence is included, position can still matter. The next failure mode occurs when the answer is in the context but receives too little attention.
Lost-in-the-Middle Behavior
Lost-in-the-middle behavior occurs when the model is less likely to use information placed in the middle of a long context than information near the beginning or end. In RAG systems, this matters because the correct chunk can be retrieved and still be underused if it is buried between many other excerpts.
Recent research continues to show that document order, context size, retrieval quality, and model choice interact in complicated ways. The practical lesson is not that every model always ignores the middle. It is that context position should be treated as a design variable, especially when answers depend on a small number of high-value passages inside a large evidence set.
Symptoms of Lost-in-the-Middle Behavior
- The correct evidence is visible in the prompt but absent from the answer. This is the clearest sign that retrieval worked but context use failed.
- Moving the same passage earlier or later changes the answer. Position sensitivity suggests the model is not treating all evidence equally.
- The model uses introductory or concluding chunks more than central chunks. This can happen when context is assembled in document order rather than relevance order.
- Longer prompts reduce faithfulness. Adding more context may push critical evidence into a less attended position.
Concrete Fixes for Lost-in-the-Middle Behavior
Place the strongest evidence where the model is most likely to use it. In many RAG pipelines, that means ordering context by relevance rather than original document order, or placing the highest-confidence answer evidence near the start of the source section. If the prompt uses a final evidence summary, make sure it is grounded in cited excerpts rather than free-form rewriting.
Reduce the amount of middle context. Rerank aggressively, remove weak passages, and avoid including entire document sections when one focused excerpt is enough. The less irrelevant material surrounds the answer, the less likely the answer is to be ignored.
For complex tasks, use multiple smaller context windows instead of one large prompt. A system can answer subquestions with focused evidence, then synthesize the results in a later step. This keeps each reasoning step closer to the evidence it needs.
Test for position sensitivity. Take known question-and-answer pairs, move the supporting evidence to different positions in the prompt, and compare answer accuracy. If performance changes significantly, context ordering should become part of the evaluation suite.
Position problems are about how current evidence is used. A different class of failure appears when the system retrieves evidence confidently, but the evidence itself is no longer current.
Stale Data
Stale data is one of the most dangerous RAG failure modes because the answer can sound grounded while being operationally wrong. A RAG system may retrieve a real policy, specification, or procedure, but that source may have been replaced by a newer version. The model is then faithful to the retrieved text but unfaithful to the current truth.
This problem is especially common when knowledge bases contain drafts, archived pages, duplicated documents, old exports, outdated help articles, or multiple versions of similar records. Semantic similarity can make old and new versions look nearly identical, so the retriever may rank outdated content highly unless freshness and version metadata are part of the retrieval design.
Symptoms of Stale Data
- The answer is supported by a source but conflicts with current policy or behavior. This indicates a freshness problem rather than a hallucination in the usual sense.
- Search returns several near-identical versions of the same document. The system may not know which version is authoritative.
- Recent updates are missing from answers. The ingestion pipeline may be delayed, broken, or incomplete.
- Users report that answers are “almost right” but outdated. Version drift often looks more plausible than a completely wrong answer.
Concrete Fixes for Stale Data
Add freshness metadata at ingestion time. Store publication date, last modified date, effective date, expiration date, version number, source system, and approval status when those fields exist. Retrieval should be able to filter or boost documents based on freshness and authority, not just semantic similarity.
Build a reliable reindexing process. When source data changes, the AI database or retrieval index should update in a predictable way. Use change detection, scheduled refreshes, deletion handling, and ingestion monitoring so removed or superseded content does not remain searchable forever.
Prefer authoritative sources over convenient copies. If the same policy appears in a knowledge article, PDF export, ticket comment, and old training document, the retrieval system needs rules that identify the source of record. Metadata filters and ranking boosts should reflect that hierarchy.
Expose dates and versions to the model. Include source timestamps and version labels in the retrieved context so the model can resolve conflicts more safely. If two sources conflict and the newer authoritative source is available, the model should be instructed to prefer it and mention uncertainty when the evidence is inconsistent.
Fresh evidence still has to be obeyed. The final failure mode appears when the model has relevant context but answers from habit, prior knowledge, or unsupported assumptions instead.
Ignored Context
Ignored context happens when the model receives relevant evidence but does not use it correctly. This can occur because the prompt is ambiguous, the retrieved context conflicts with the model’s prior knowledge, the user asks for speculation, or the answer requires careful extraction from dense evidence. It is a generation failure, but it is often caused by weak context packaging or missing answer rules.
This failure mode is important because it can mislead teams into endlessly tuning retrieval. If the right chunk is present, ranked high, fresh, and readable, the next question is whether the model was clearly instructed to ground the answer in that context and whether the system checks that the final answer is actually supported.
Symptoms of Ignored Context
- The final answer contradicts the retrieved evidence. This is a direct context-faithfulness failure.
- The model gives a generic answer when the source contains a specific answer. It may be relying on prior knowledge or common patterns.
- The answer includes unsupported details. The model may be filling gaps instead of saying the source does not contain enough information.
- The answer changes when instructions are strengthened but retrieval stays the same. This suggests the generation layer needed clearer grounding constraints.
Concrete Fixes for Ignored Context
Make the grounding instruction explicit. Tell the model to answer only from the provided sources, to say when the sources do not contain enough information, and to avoid adding unsupported details. This instruction should be paired with evidence that is concise enough for the model to follow.
Use source-attribution checks. Ask the model to identify which source passage supports each important claim, or run a separate verification step that checks whether the answer is entailed by the retrieved context. This is especially useful for compliance, technical support, finance, healthcare, legal, and other high-consequence workflows.
Separate answer generation from answer validation. A second pass can compare the draft answer against the retrieved evidence and flag unsupported claims, contradictions, missing caveats, or stale-source conflicts. This does not make the system perfect, but it catches many cases where the model drifted away from the evidence.
Improve the prompt format when the model has to reason over several sources. Label sources clearly, include dates and document names, group related excerpts together, and ask for a direct answer before explanation. The easier the evidence is to inspect, the less likely the model is to default to unsupported general knowledge.
These failure modes often overlap. A stale chunk can be retrieved weakly, placed in the middle of an overcrowded prompt, and then ignored or overgeneralized by the model. That is why a useful RAG debugging process looks at the whole path from data ingestion to final answer.
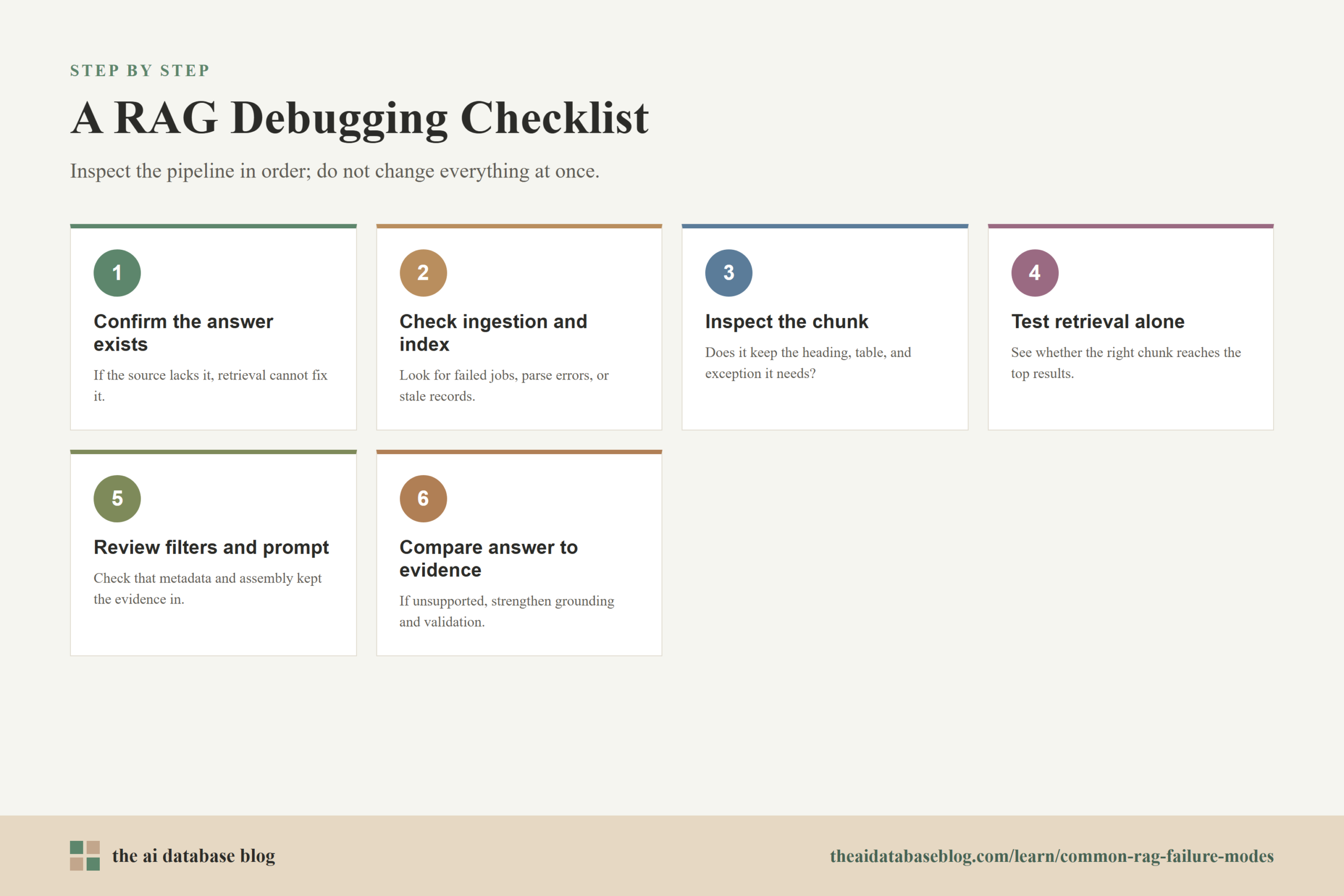
A Practical Debugging Checklist for RAG Failures
When a RAG answer fails, inspect the pipeline in order rather than changing everything at once. A disciplined debugging sequence makes the root cause easier to find and prevents teams from blaming the model for problems created earlier in the retrieval flow.
- Confirm the answer exists in the source data. If the knowledge base does not contain the answer, retrieval cannot fix the problem.
- Check whether the source was ingested and indexed. Look for failed ingestion jobs, parsing errors, missing file types, access restrictions, or deleted records that still appear in the index.
- Inspect the chunk that should answer the question. Confirm that it preserves the needed heading, definitions, table labels, exceptions, and neighboring context.
- Run retrieval tests without generation. Check whether the expected chunk appears in the top results and whether irrelevant chunks outrank it.
- Review filters and metadata. Make sure tenant, permission, date, version, product, region, and document-type filters are not excluding the right evidence or including the wrong evidence.
- Inspect the final prompt context. The retrieved chunk may have been dropped, truncated, deduplicated incorrectly, or placed where it receives little attention.
- Compare the final answer to the evidence. If the answer is unsupported despite good evidence, strengthen grounding, attribution, and validation.
This checklist also creates a foundation for evaluation. Instead of measuring only whether the final answer sounds good, teams can measure retrieval recall, context precision, freshness, source faithfulness, and user-rated answer quality as separate signals.
How to Prevent RAG Failures Before They Reach Users
The best RAG systems are not fixed once and trusted forever. They are maintained like search and data infrastructure. Documents change, user questions evolve, models change, embedding behavior shifts, and new edge cases appear as the system moves from demo use to real workflows.
Start with a representative evaluation set. Include common questions, rare questions, ambiguous questions, multi-hop questions, recent-update questions, and questions that should produce “not enough information” answers. For each question, record the expected source, expected answer, and the conditions that make the answer correct.
Track pipeline-level metrics. Retrieval recall shows whether the right evidence is found. Context precision shows whether the prompt is packed with useful information rather than noise. Freshness checks show whether outdated sources are being retrieved. Faithfulness checks show whether the model’s answer is supported by the context.
Use production feedback to improve the test set. Failed answers, user corrections, escalations, and unanswered queries are valuable because they show where the system meets real language, messy data, and changing requirements. Each serious failure should become a regression test so the same issue does not return silently.
Prevention does not mean removing every error. It means making failures visible, diagnosable, and fixable. A RAG system improves fastest when teams can tell whether a bad answer came from missing data, poor chunking, weak retrieval, noisy context, stale evidence, or generation that ignored the source.
FAQs
1. What is the most common reason a RAG system gives wrong answers?
The most common reason is that the system does not provide the model with the right evidence in a usable form. The source may be missing, poorly chunked, weakly retrieved, ranked too low, dropped from the final context, or mixed with too much irrelevant information. The model may look like the problem, but the root cause is often earlier in the retrieval pipeline.
2. How can I tell whether the problem is retrieval or generation?
Inspect the final context sent to the model. If the correct evidence is absent, incomplete, outdated, or buried under irrelevant material, the main problem is retrieval or context assembly. If the correct evidence is present, fresh, clear, and highly ranked but the answer still contradicts it, the problem is more likely generation, prompting, or answer validation.
3. Does a larger context window solve RAG failures?
A larger context window can help when the system genuinely needs more evidence, but it does not automatically solve RAG failures. More context can also introduce noise, contradictions, stale documents, and lost-in-the-middle behavior. Strong retrieval, reranking, filtering, and context organization still matter even when the model can accept long prompts.
4. Is semantic search enough for production RAG?
Semantic search is useful because it can find conceptually related content even when the wording differs. However, many production queries also depend on exact terms such as names, IDs, dates, codes, or policy labels. A hybrid retrieval approach that combines semantic and keyword signals is often more reliable than using semantic search alone.
5. How often should a RAG knowledge base be refreshed?
The refresh schedule should match how quickly the underlying information changes. A policy assistant may need updates whenever an approved policy changes, while a documentation assistant may need frequent reindexing as pages are edited. The important point is to define freshness requirements, monitor ingestion, remove superseded content, and store metadata that helps retrieval prefer current authoritative sources.
6. What should I measure when improving a RAG system?
Measure more than final answer quality. Track whether the correct source is retrieved, whether it appears in the final context, whether irrelevant chunks are included, whether sources are current, and whether the generated answer is supported by the evidence. These separate metrics make it much easier to identify the exact part of the pipeline that needs improvement.
Takeaway
RAG failures are usually fixable when they are diagnosed at the right layer. Bad chunking breaks evidence into unusable pieces, weak retrieval misses or misranks the answer, context overflow adds distracting material, lost-in-the-middle behavior hides important passages, stale data makes grounded answers outdated, and ignored context lets the model drift away from the evidence. This guidance is most useful for teams building AI assistants, enterprise search, support tools, documentation copilots, and knowledge retrieval systems where answers need to be accurate, current, and traceable to reliable sources.