Chunk size and overlap determine what an AI database stores, retrieves, and sends into a generation model. Small chunks usually improve precision because each retrieved passage is tightly focused, while large chunks preserve more surrounding context but can dilute relevance. Overlap helps protect meaning that crosses chunk boundaries, but too much overlap creates duplicate retrieval results, higher storage cost, and less useful context. The best choice depends on content type, query style, retrieval method, and measured answer quality rather than one universal token count.
This guide explains how to choose chunk size and overlap for retrieval-augmented generation systems, vector search, and AI database workloads. It covers the tradeoff between precise small chunks and context-rich large chunks, when overlap helps or hurts, how different content types should be split, and how query style changes the right setting. By the end, you should be able to choose a sensible starting point and tune it with evaluation instead of guessing.
What Chunk Size Means in an AI Database
Chunk size is the amount of source content grouped into one retrievable unit before it is embedded and stored in an AI database. A chunk might be measured in tokens, words, characters, sentences, paragraphs, table rows, code blocks, or document sections. In most modern RAG systems, token-based measurement is more useful than character-based measurement because embedding models and generation models operate on tokens, not raw characters.
The chunk is important because it becomes the basic unit of retrieval. When a user asks a question, the system does not usually retrieve the entire document. It retrieves the chunks that appear most relevant to the query. Those chunks are then passed to a language model as evidence for the answer, sometimes after filtering, reranking, deduplication, or context expansion.
This means chunking is not just a preprocessing detail. It shapes what the AI database can find. A poorly chosen chunk size can cause the right answer to be split away from the explanation that makes it meaningful, or buried inside a large passage that also contains unrelated information. A strong chunking strategy tries to keep each chunk focused enough to match a query while complete enough to support a grounded answer.
Once chunk size is understood as a retrieval unit rather than a formatting choice, the central tradeoff becomes clearer: smaller chunks tend to make matching more precise, while larger chunks tend to make retrieved context more complete. The difficult part is deciding which side matters more for a specific application.
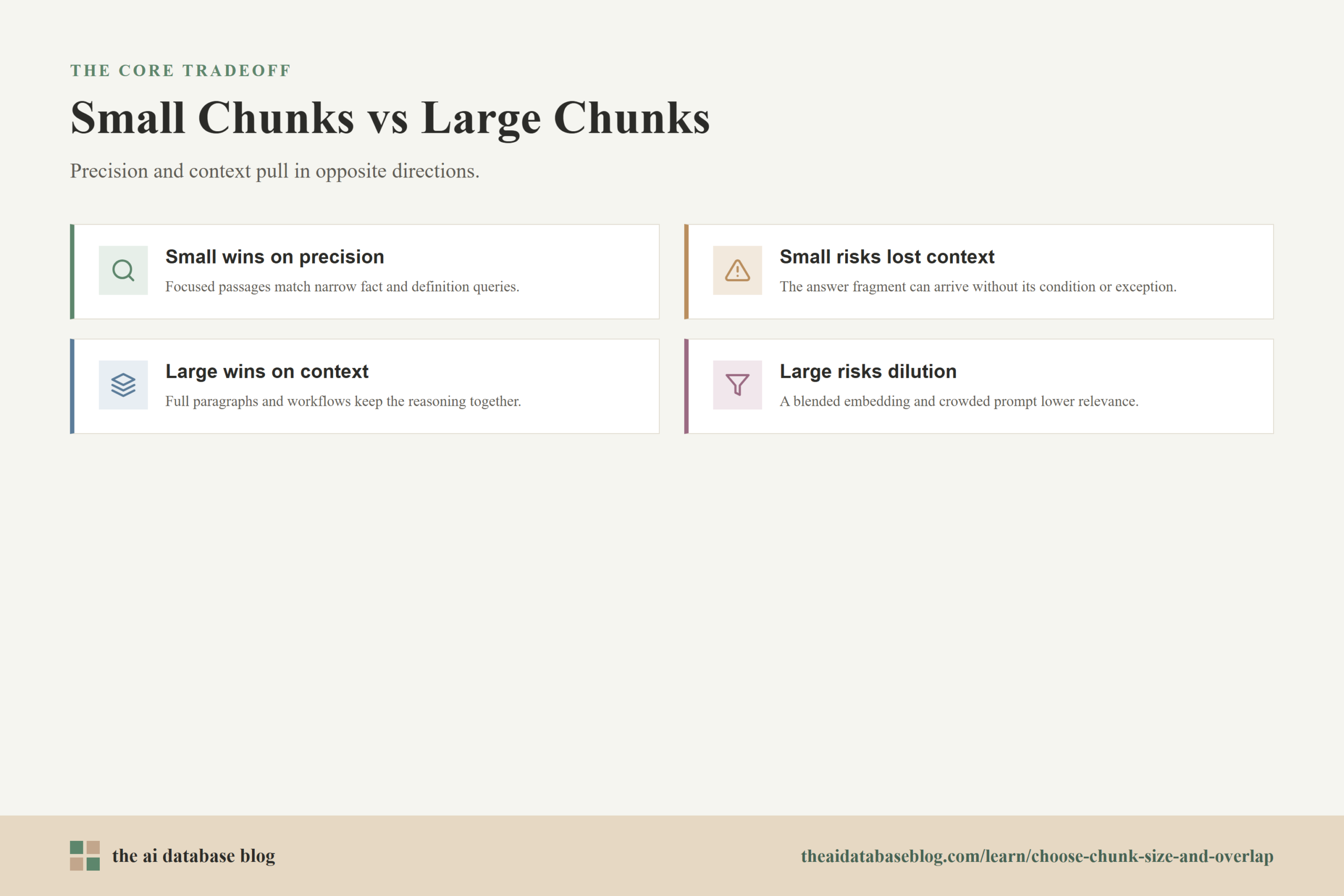
The Tradeoff Between Small Chunks and Large Chunks
Small chunks and large chunks fail in different ways. Small chunks can be excellent for finding exact facts, definitions, parameter values, policy clauses, error messages, or short procedural steps. Because each chunk contains fewer unrelated ideas, its embedding is often more specific. That can help the retriever rank it highly when the query is narrow.
The weakness of small chunks is that they may not contain enough surrounding information to answer the question safely. A sentence might include a requirement but not the exception in the next sentence. A code fragment might show a function call but not the function definition. A policy line might mention eligibility but not the conditions that limit it. When this happens, retrieval may look successful because the answer fragment is present, but generation quality suffers because the model lacks the context needed to interpret it.
Large chunks solve some of that problem by preserving broader context. They are useful when the answer depends on a full paragraph, a complete section, a narrative explanation, a multi-step workflow, or a table with related rows. A larger chunk gives the generation model more material to reason from and can reduce the chance that a boundary cuts through an important idea.
The weakness of large chunks is lower retrieval precision. If a chunk contains several topics, the embedding represents a blended meaning. A query might match one part of the chunk weakly, while unrelated parts take up space in the retrieved context. This can make reranking harder, reduce the number of distinct useful passages that fit into the prompt, and increase the chance that the model uses nearby but irrelevant text.
When Smaller Chunks Work Better
Smaller chunks work best when user questions are specific and the source material is already written in compact, separable units. Examples include glossary entries, API fields, product specifications, compliance requirements, troubleshooting errors, individual FAQ answers, and short knowledge base articles. In these cases, a chunk that contains one answerable idea is often better than a chunk that contains a whole page.
Small chunks also help when the system retrieves many candidates and uses a reranker. The first retrieval step can gather focused candidate passages, and the reranker can decide which ones truly answer the question. This pattern often works well for fact-seeking queries because each candidate passage is easier to compare against the query.
When Larger Chunks Work Better
Larger chunks work better when the answer depends on context that is not obvious from one sentence or small passage. They can help with conceptual explanations, legal or policy interpretation, research summaries, technical manuals, lessons, long-form documentation, and workflows where one step depends on previous steps. In these cases, a chunk that is too small may retrieve the surface fact but miss the reasoning around it.
Larger chunks are also useful when the retrieval system returns only a small number of chunks. If the top results are limited, each retrieved chunk may need to carry more context. However, this should be balanced carefully because large chunks can crowd out other relevant evidence when the generation prompt has a fixed context budget.
Small and large chunks both have real advantages, so the practical question is not which one is universally better. The more useful question is whether the chunk contains one coherent unit of meaning for the types of questions your users actually ask. That is where overlap becomes important, because many retrieval failures happen near the boundary between two otherwise reasonable chunks.
The Role of Overlap
Overlap means copying a small part of one chunk into the next chunk. For example, if a system creates 500-token chunks with 75 tokens of overlap, the last 75 tokens of one chunk also appear at the beginning of the next. The purpose is to protect information that spans a chunk boundary, such as a definition followed by an example, a requirement followed by an exception, or a heading followed by the first explanatory paragraph.
Overlap is helpful because documents are rarely written to fit artificial token boundaries. A sentence can refer back to the previous sentence. A paragraph can depend on a heading. A procedure can have setup information before the steps. Without overlap, the retriever may find a chunk that looks relevant but is missing the few lines that explain what the answer means.
However, overlap is not free. More overlap means more text is embedded, stored, indexed, retrieved, and potentially sent to the generation model. It can also create near-duplicate results. If the top retrieved chunks are mostly overlapping copies of the same passage, the system may waste context space and miss other useful evidence. This is especially harmful when the retriever returns only a small top-k set.
Useful Overlap Ranges
A common starting point is overlap of about 10 to 20 percent of the chunk size. For a 500-token chunk, that means roughly 50 to 100 tokens of overlap. For short, highly structured content, less overlap may be enough. For dense prose, long explanations, or procedural content, a little more overlap may protect continuity.
Overlap should usually be smaller when chunks are split on natural boundaries such as headings, paragraphs, rows, or code functions. If the split already respects meaning, heavy overlap is less necessary. Overlap should usually be larger when fixed-size splitting is used on long prose, because arbitrary boundaries are more likely to cut through an idea.
When Overlap Hurts
Overlap hurts when it causes repeated retrieval of nearly identical chunks. This can make the system look like it found many relevant passages when it really found the same passage several times. It also increases storage and indexing cost. In large systems, unnecessary overlap can become a quiet performance problem because every extra copied token must be embedded and searched.
Overlap can also hurt when the content has discrete records. For example, table rows, log events, customer tickets, and short FAQ entries often should remain separate unless there is a clear relationship between adjacent records. Blind overlap in these cases can mix unrelated items and make retrieved evidence less trustworthy.
Overlap is most useful when it solves a boundary problem, not when it is used as a substitute for thoughtful chunking. After setting a modest overlap, the next step is to choose chunking rules based on the shape of the source content itself.
Tuning Chunk Size by Content Type
Different content types carry meaning in different units. A paragraph in a guide, a row in a table, a function in code, and a clause in a policy document should not all be split with the same mechanical rule. A good AI database pipeline usually starts with document-aware splitting and then applies token limits so no chunk becomes too large for embedding or retrieval.
For many teams, the best practical improvement is to stop treating every document as plain text. Source structure often tells you where meaning begins and ends. Headings, lists, sections, rows, turns, functions, and metadata fields can all guide chunk boundaries. This is why structure-aware chunking has become important in modern RAG design: it preserves relationships that fixed-size splitting often damages.
Long-Form Articles and Documentation
For long-form prose, start by splitting on headings and paragraphs, then merge nearby paragraphs until each chunk is large enough to be meaningful but small enough to stay focused. A practical starting range is often around 300 to 800 tokens per chunk with 10 to 20 percent overlap, depending on how dense the material is. Conceptual documentation may need larger chunks, while short explanatory pages may work well with smaller ones.
The goal is to avoid chunks that begin mid-thought or end before the explanation is complete. If a retrieved chunk regularly needs the previous paragraph to make sense, the chunk boundary is probably too aggressive. If chunks contain several unrelated headings, they are probably too large.
Technical Manuals and Procedures
Manuals and procedures should preserve step order and warnings. Splitting in the middle of a procedure can cause the system to retrieve an instruction without the prerequisite or safety condition that came before it. For this content, chunk by section, subsection, or procedure block, and use overlap to carry short setup details or warnings into the following chunk when needed.
When procedures are long, it can help to store both smaller step-level chunks and a parent section reference. The small chunk improves precise retrieval, while the parent section can be pulled in during context expansion when the answer needs the full procedure.
Policies, Contracts, and Compliance Content
Policy and compliance content should be split around clauses, definitions, exceptions, and numbered sections. Small chunks can retrieve exact clauses, but they may be misleading if exceptions or definitions are nearby. In this content type, overlap should protect references between definitions and rules, but the system should also preserve section metadata so retrieved chunks can be traced back to their source context.
A useful pattern is to keep each clause or subsection as a focused chunk while attaching metadata for document title, section number, heading path, effective date, and jurisdiction or audience when relevant. Metadata filtering can then narrow retrieval before semantic search, which often improves precision more than changing chunk size alone.
Tables and Spreadsheets
Tables should usually be chunked by structure rather than by raw tokens. Rows, groups of rows, column headers, and key-value representations matter because the meaning of a cell often depends on its header and neighboring fields. If a table is flattened into arbitrary text chunks, retrieval may separate a value from the label that explains it.
For tabular content, convert rows into clear key-value blocks and group related rows only when they belong together. Overlap is often less useful than preserving headers and row relationships. In many cases, dense non-overlapping chunks are better than overlapping chunks that repeat partial rows or mix unrelated records.
Code and Developer Documentation
Code should be split around meaningful units such as functions, classes, modules, examples, and configuration blocks. A fixed token split can break syntax or separate a function from the comment or documentation that explains it. For developer documentation, examples should often stay with the explanation they demonstrate, even if that means chunks are slightly larger.
Overlap can help when a code example depends on surrounding explanatory text. It should not duplicate large blocks of code unnecessarily, because repeated code chunks can crowd search results. Metadata such as file path, symbol name, language, and version can make retrieval much more reliable.
Chats, Tickets, and Conversation Logs
Conversation content should be chunked by turn, topic, or issue rather than by a fixed token count alone. A single support ticket may include a problem, clarification, attempted fix, and resolution. Splitting without regard for that flow can retrieve the symptom without the answer, or the answer without the condition that made it correct.
For conversations, modest overlap across turns can help preserve continuity, but the better strategy is usually topic-aware grouping. Metadata such as speaker, timestamp, channel, ticket status, and resolved issue type can help the AI database retrieve the right conversation fragment without mixing unrelated exchanges.
Content type gives you the first tuning signal, but it is not the only one. The same document can need different chunking behavior depending on whether users ask narrow factual questions, broad synthesis questions, or troubleshooting questions that require several pieces of evidence.
Tuning Chunk Size by Query Style
Query style describes what users are trying to retrieve. Some users ask for a specific fact. Others ask for a comparison, explanation, summary, diagnosis, or sequence of steps. The best chunk size should reflect the answer shape, because retrieval is only successful when the chunk contains enough information to support that answer.
This is why query logs are so useful. They reveal whether users ask short keyword-like questions, natural language questions, broad exploratory questions, or follow-up questions in a conversation. Tuning chunk size without looking at query style often leads to a system that works well in demos but fails on real use.
Factoid Queries
Factoid queries ask for a specific answer, such as a definition, date, limit, value, setting, field, or requirement. These queries usually benefit from smaller chunks because the retriever needs to find a precise passage. If chunks are too large, the exact answer may be present but surrounded by unrelated text that weakens the match.
For factoid queries, start with focused chunks and modest overlap. Then measure whether the answer-bearing chunk appears in the top results. If it does not, improve boundaries, metadata, and retrieval configuration before simply increasing chunk size.
Explanatory Queries
Explanatory queries ask how or why something works. These often need larger chunks because the answer depends on relationships between concepts. A single sentence may not carry enough reasoning, so chunking by paragraph group or section often works better than very small fragments.
For explanatory queries, it is often useful to retrieve focused chunks first and then expand context around the best matches. This allows the AI database to keep retrieval precise while still giving the generation model enough surrounding material to produce a coherent explanation.
Comparative Queries
Comparative queries ask about differences, tradeoffs, or choices. They often require multiple chunks from different sections or documents. Large chunks can help if each chunk covers one side of the comparison, but oversized chunks may reduce diversity in the retrieved set.
For comparison-heavy applications, chunk size should be paired with retrieval diversity. The system should avoid returning five overlapping chunks about one option when the answer needs evidence about several options. Reranking, deduplication, and metadata filtering can matter as much as chunk size here.
Troubleshooting and Diagnostic Queries
Troubleshooting queries often include symptoms, constraints, and attempted actions. The right answer may depend on a chain of conditions. If chunks are too small, retrieval may find a symptom match but miss the diagnostic path. If chunks are too large, the retriever may return broad pages that mention the symptom but not the actual fix.
For troubleshooting content, chunk by issue, cause, resolution, and procedure. Preserve headings and step sequences. Use overlap where setup conditions or warnings cross boundaries, but rely on structure and metadata to keep each retrieved passage tied to a specific problem.
Query style helps explain why the same chunk size can feel excellent in one application and poor in another. To move from a reasonable starting point to a reliable production setting, you need an evaluation loop that measures retrieval and answer quality directly.
A Practical Tuning Workflow
The safest way to choose chunk size and overlap is to start with a defensible baseline, then test it against representative documents and real or realistic queries. Chunking choices should be treated as configuration that can be evaluated, not as a one-time implementation detail. A small evaluation set is often enough to reveal whether chunks are too small, too large, or poorly aligned with document structure.
Begin with a baseline such as structure-aware splitting, 300 to 800 token chunks for prose, and 10 to 20 percent overlap where boundaries are not naturally clean. For highly structured records, use the record or field group as the chunk instead of forcing a prose-style token size. Then compare alternatives using the same corpus, queries, embedding model, retrieval method, and top-k setting.
1. Build a Small Evaluation Set
Create a set of representative questions and identify the source passages that should support the answers. Include easy fact questions, harder context questions, comparison questions, and queries that are likely to fail. The evaluation set should reflect the real mix of user needs, not only the questions that are easiest for the system.
For each chunking configuration, measure whether the correct evidence appears in the top retrieved results. Useful metrics include recall at k, precision at k, mean reciprocal rank, answer groundedness, and human review of retrieved context. Even simple manual inspection can be valuable: look at the top results and ask whether they are specific, complete, non-duplicative, and sufficient for the answer.
2. Test Size Before Over-Optimizing Strategy
Try a few chunk sizes before adopting a more complex chunking method. For example, compare 300, 500, and 800 token chunks for long-form prose, with similar overlap percentages. If a simple structure-aware splitter performs well, extra complexity may not be necessary.
If fixed or recursive chunking consistently fails because it cuts through meaning, then test semantic or query-adaptive approaches. These approaches can improve coherence, but they should earn their place through measured gains because they may add processing cost and operational complexity.
3. Watch for Common Failure Signals
If retrieved chunks often contain the exact answer but not enough context to explain it, chunks may be too small or overlap may be too low. If retrieved chunks are broad, noisy, and only partially related to the query, chunks may be too large. If top results are mostly repeated versions of the same passage, overlap may be too high or deduplication may be missing.
If failures cluster around specific document types, do not solve them with one global setting. Tables, code, policies, manuals, and conversations often need separate chunking rules. A mixed corpus usually benefits from routing documents through different chunkers before storing them in the AI database.
4. Consider Parent-Child Retrieval
Parent-child retrieval is a useful pattern when small chunks retrieve accurately but larger context is needed for generation. The system embeds and retrieves smaller child chunks, then expands to a larger parent section before sending context to the model. This keeps matching precise while giving the model enough surrounding material to answer well.
This approach can reduce the pressure to choose one perfect chunk size. The child chunk can be optimized for retrieval, and the parent chunk can be optimized for context. It is especially useful for manuals, long documentation, policies, and technical guides where local facts depend on section-level context.
A tuning workflow should produce a setting that is good enough, measurable, and maintainable. The final decision should balance quality with cost, latency, storage, and operational simplicity.
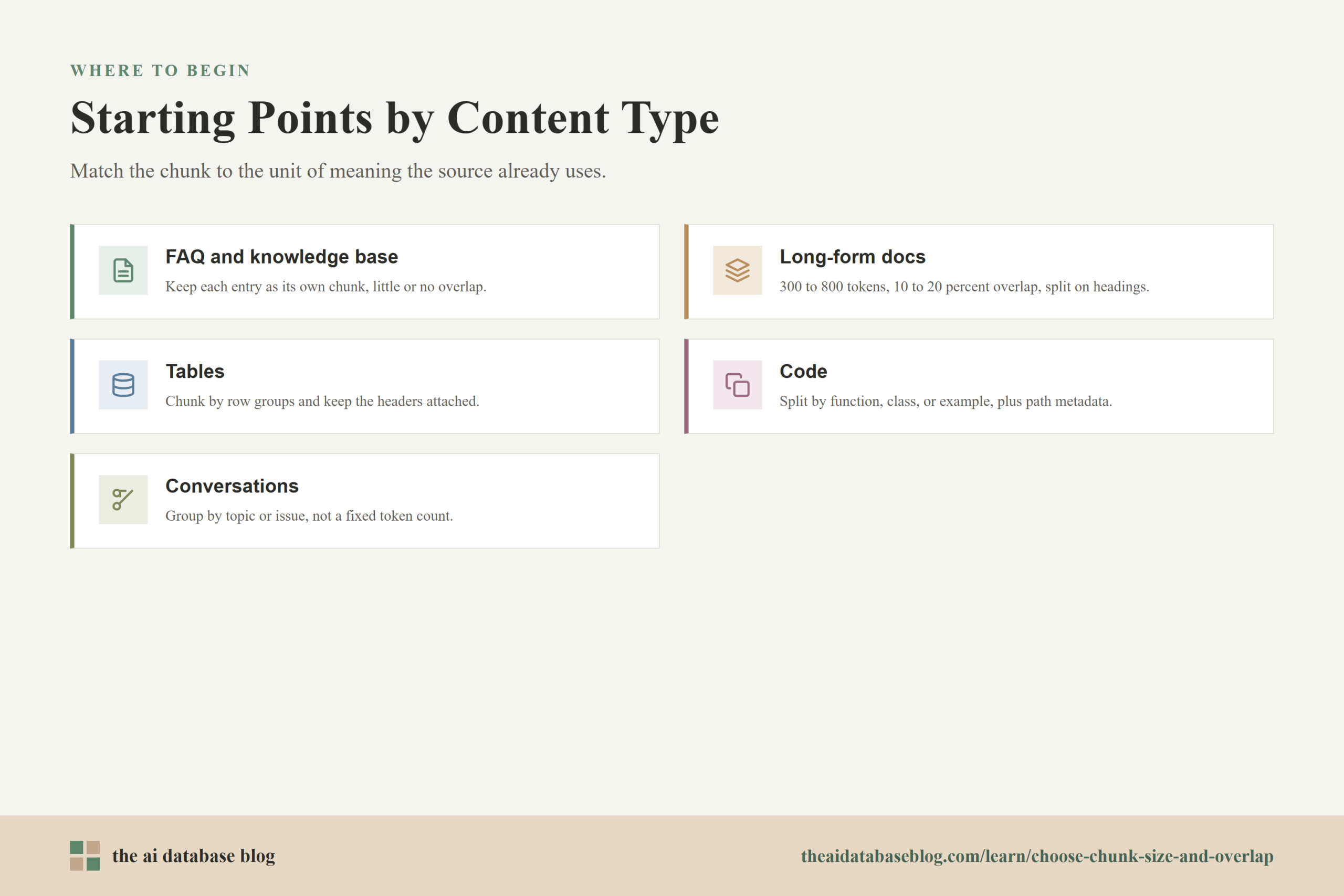
Recommended Starting Points
There is no universal best chunk size, but starting points are still useful. The numbers below should be treated as initial settings to test, not permanent rules. They assume text is measured in tokens and that chunks are split on natural boundaries whenever possible.
- Short FAQ or knowledge base entries: Keep each entry or answer as its own chunk when possible. Use little or no overlap unless entries refer to surrounding content.
- Long-form documentation: Start around 300 to 800 tokens with 10 to 20 percent overlap. Split by headings and paragraphs before applying token limits.
- Technical manuals: Chunk by section, procedure, warning, or step group. Use overlap to preserve setup conditions and warnings near boundaries.
- Policy and compliance documents: Chunk by clause or subsection, preserve heading paths and definitions, and use metadata filters for audience, date, region, or document type.
- Tables and spreadsheets: Chunk by row groups or key-value records. Preserve headers and relationships. Avoid blind overlap that breaks or duplicates rows.
- Code and developer docs: Chunk by function, class, module, example, or configuration block. Attach metadata for file path, symbol, language, and version.
- Conversation logs and tickets: Chunk by topic, issue, or resolution flow. Use turn-level overlap only when it preserves necessary continuity.
These starting points work best when combined with evaluation. If the system retrieves incomplete snippets, increase chunk size, improve boundary rules, or use parent-child expansion. If it retrieves noisy passages, reduce chunk size, improve metadata filtering, or add reranking. If it retrieves duplicates, reduce overlap or add deduplication.
Common Mistakes to Avoid
Many chunking problems come from treating all documents and all questions the same way. A single global setting may be simple, but it often performs poorly across mixed content. The goal is not to make chunking complicated; it is to preserve the units of meaning that already exist in the source material.
- Using character counts as the main control: Characters do not map cleanly to model limits. Token-based limits are usually more predictable.
- Splitting through natural boundaries: Avoid cutting through sentences, tables, code blocks, procedures, or clauses when those units carry meaning.
- Adding too much overlap: Heavy overlap can create duplicate-heavy retrieval and waste context space.
- Ignoring metadata: Metadata can narrow the search space before vector retrieval and often improves relevance more than minor chunk-size changes.
- Evaluating only final answers: Inspect retrieval results directly so you can tell whether failures come from chunking, retrieval, reranking, or generation.
- Optimizing for one query type: A setting that works for fact lookup may fail for synthesis, comparison, or troubleshooting.
Avoiding these mistakes makes chunking easier to reason about. Instead of chasing a perfect number, you can ask a more concrete question: does each retrieved chunk contain a coherent, useful piece of evidence for the question being asked?
FAQs
1. What is the best chunk size for RAG?
There is no single best chunk size for every RAG system. A useful starting point for long-form text is often a few hundred tokens per chunk, commonly in the 300 to 800 token range, with structure-aware splitting. The right size depends on the content, query style, retrieval method, and context budget. The best answer is the chunk size that retrieves complete, relevant, non-duplicative evidence in evaluation.
2. Is it better to use small chunks or large chunks?
Small chunks are usually better for precise fact lookup because they contain less unrelated text. Large chunks are usually better when answers need surrounding context, explanation, or multi-step reasoning. Many production systems combine both ideas by retrieving small chunks and expanding to a larger parent section before generation.
3. How much overlap should chunks have?
A practical starting point is about 10 to 20 percent overlap. For example, a 500-token chunk might use 50 to 100 tokens of overlap. Use less overlap when chunks already follow clean boundaries, and more overlap when fixed-size splitting might cut through connected ideas. Reduce overlap if retrieval results become repetitive.
4. Can too much overlap hurt retrieval quality?
Yes. Too much overlap can cause the retriever to return several near-duplicate chunks instead of a diverse set of useful evidence. It also increases embedding, storage, indexing, and context costs. Overlap should solve boundary problems, not compensate for poor chunk boundaries everywhere.
5. Should tables and code use the same chunk size as normal text?
No. Tables and code need structure-aware chunking. Tables should preserve headers, rows, and key-value relationships. Code should preserve functions, classes, examples, and configuration blocks. A plain token split can separate information that only makes sense together.
6. How do I know when to change chunk size?
Change chunk size when retrieval inspection shows a consistent failure pattern. If answers are split across neighboring chunks, increase chunk size, add modest overlap, or use parent-child retrieval. If chunks are noisy and broad, reduce chunk size or improve structure-aware splitting. If results repeat the same text, reduce overlap or add deduplication.
Takeaway
Choosing chunk size and overlap is about matching retrieval units to the way meaning appears in your content and the way users ask questions. Small chunks improve precision, large chunks preserve context, and overlap protects boundary-crossing ideas, but each choice has tradeoffs in relevance, duplication, cost, and prompt space. This guidance is most useful for teams building AI databases, vector search systems, and RAG applications where documents include mixed content such as documentation, policies, tables, code, and support conversations. A strong practical use case is a technical knowledge assistant that retrieves exact troubleshooting steps while still preserving enough surrounding context for safe, grounded answers.
Watch this video to learn more