A data ingestion pipeline for an AI database turns source content into searchable, reliable, and up-to-date records. The core steps are loading data, cleaning and parsing it, chunking it into useful retrieval units, generating embeddings, and upserting the resulting objects into a vector or hybrid search index. At production scale, the hard part is not only moving data quickly. The pipeline also has to handle rate limits, retry transient failures, avoid duplicate writes, preserve source metadata, and expose enough observability to show where latency, cost, and quality problems begin.
This guide explains how to design ingestion pipelines that can support retrieval-augmented generation, semantic search, recommendation, and other AI database workloads. It covers the full path from source loading through chunking, embedding, and upserting, then explains the operational controls that make ingestion safe at scale: batching, backpressure, idempotency, retries, rate-limit handling, reprocessing, and monitoring. By the end, you should understand how to think about ingestion as a durable data system rather than a one-time indexing script.
Why Data Ingestion Pipelines Matter for AI Databases
AI database quality starts before the first query is ever run. If the ingestion pipeline extracts noisy text, drops metadata, splits documents poorly, embeds the wrong fields, or writes duplicate records, the search layer inherits those problems. A strong vector index cannot recover context that was removed during parsing, and a retrieval system cannot filter by permissions, source, date, or product area if those fields were never attached to each chunk.
Traditional data ingestion often focuses on moving records from one system to another while preserving structured fields. AI database ingestion has an additional responsibility: it must convert human-readable or semi-structured content into retrieval-ready representations. That usually means normalizing documents, preserving provenance, splitting content into chunks, generating vectors, storing searchable text, and attaching metadata that supports filtering, ranking, governance, and refresh logic.
The ingestion pipeline also defines how quickly the AI database reflects changes in the source systems. A chatbot over internal knowledge, for example, may need deleted pages removed quickly, updated policies re-embedded, and permission changes applied before users can retrieve restricted information. In that setting, ingestion is not a background convenience. It is part of the reliability, security, and relevance boundary of the application.
Once ingestion is treated as part of the production system, the next question is what the pipeline actually has to do. The work can be organized into a sequence of stages, each with a different failure mode and each requiring its own controls.
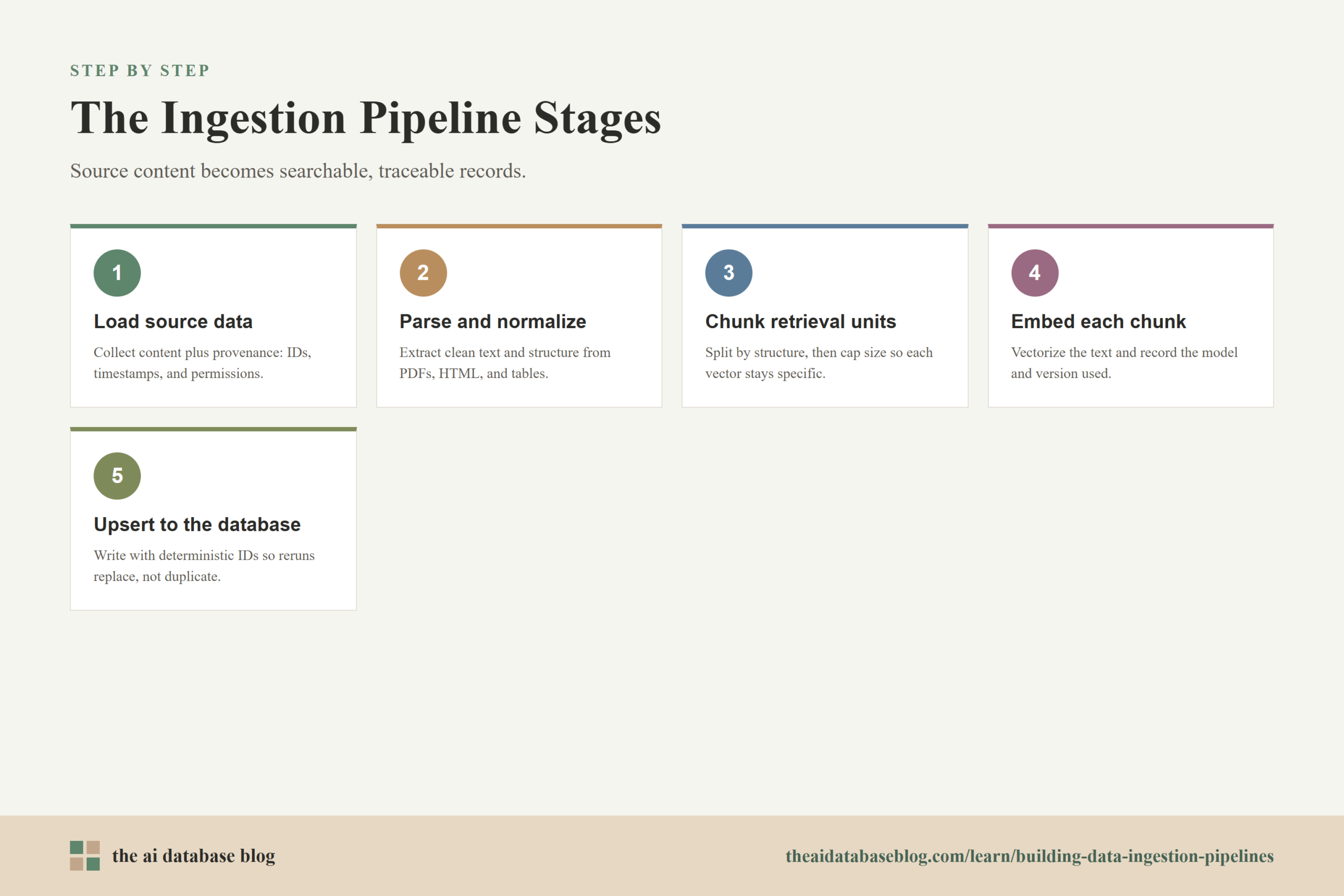
The Core Stages of an AI Database Ingestion Pipeline
A practical ingestion pipeline can be understood as a series of transformations. Source data enters the pipeline in its original form, moves through extraction and normalization, becomes smaller retrieval units, is converted into embeddings, and is finally written into the AI database. Each stage should produce a clear intermediate output so problems can be inspected without rerunning the entire job blindly.
Loading Source Data
Loading is the process of collecting content from source systems such as document repositories, websites, databases, support tickets, product catalogs, object storage, or event streams. The loader should capture both the content and the information needed to interpret it: source identifier, document path, owner, timestamps, access rules, version, language, MIME type, and any domain-specific fields that might later help retrieval.
At small scale, a loader may read a folder of files. At production scale, it usually needs pagination, checkpointing, change detection, and source-specific error handling. For example, a pipeline that reads from a documentation site should know which pages changed since the last run. A pipeline that reads from a permissioned knowledge base should record access-control metadata alongside the text, not after the fact. The earlier provenance is captured, the easier it is to maintain trust in the indexed data.
Parsing and Normalization
Parsing turns loaded files into usable text and structured fields. This step may include extracting PDF text, converting HTML to clean article text, reading tables, removing navigation boilerplate, preserving headings, and detecting document boundaries. Normalization then makes the extracted content consistent enough for downstream chunking and embedding.
This stage deserves more attention than it often receives. Poor parsing can merge unrelated sections, lose table labels, duplicate headers, or turn source documents into long strings with no structure. Those errors are hard to detect from vector search results alone because the retrieved chunk may look plausible while still being incomplete or misleading. A good ingestion pipeline stores parse artifacts or previews so teams can inspect what the database actually received.
Chunking Retrieval Units
Chunking splits normalized content into units that can be embedded and retrieved. A chunk should usually be large enough to carry a meaningful idea, but small enough that its embedding is specific. If a chunk is too broad, the vector may represent several topics at once and match queries imprecisely. If a chunk is too small, it may retrieve a fragment that lacks the surrounding context needed to answer a question.
There is no single best chunk size for every corpus. A practical baseline is to split by document structure first, such as headings, sections, paragraphs, rows, or records, and then apply token-based limits inside oversized sections. Some pipelines add overlap to protect information that spans boundaries, while others prefer cleaner section-aware chunks with little or no overlap. The right choice depends on document type, retrieval task, embedding model, query patterns, and cost constraints.
Embedding Chunks
Embedding converts each chunk into a vector representation that captures semantic meaning. The embedding request usually includes the chunk text and sometimes selected context such as title, section heading, product name, or short source description. The pipeline should record the embedding model name, model version if available, vector dimension, embedding timestamp, and any preprocessing rules used to create the text that was embedded.
This metadata matters because embeddings are not universal facts about text. They are outputs of a specific model and preprocessing process. If the model changes, the chunking rules change, or the embedded text format changes, older vectors may no longer be comparable to newer ones. Production ingestion systems therefore need a way to identify which records should be re-embedded and which records are already current.
Upserting into the AI Database
Upserting writes each chunk into the AI database in a way that either creates a new object or replaces the previous version of the same object. A typical record includes the chunk text, vector, source metadata, retrieval metadata, timestamps, and a deterministic identifier. Deterministic identifiers are important because they let the pipeline safely rerun without creating duplicates.
Upsert design should also account for deletions and document updates. If a source document is removed, the chunks derived from it should be deleted or marked inactive. If a document changes, the pipeline should replace only affected chunks when possible, while preserving enough lineage to know which source version produced which indexed objects.
These stages describe the shape of the work, but the order alone does not make the pipeline scalable. Once ingestion volume grows, throughput becomes a system design problem involving batching, concurrency, provider limits, database capacity, and backpressure.
Loading, Chunking, Embedding, and Upserting at Scale
Scaling ingestion means increasing throughput without overwhelming the source systems, embedding providers, workers, queues, or AI database. The safest approach is to treat ingestion as a controlled flow of work rather than a single loop that reads everything and writes as fast as possible. Every stage should have a bounded queue, measurable throughput, and a clear policy for what happens when the next stage slows down.
Use Batches Without Losing Control
Batching improves throughput because it reduces per-request overhead and allows workers to process multiple records together. Loaders can read pages of source data, parsers can process files in groups, embedding calls can send multiple chunks per request when supported, and database clients can write batches instead of one object at a time. For large offline jobs, asynchronous batch processing can also be useful when results do not need to be available immediately.
Batch size should be tuned around the narrowest constraint in the pipeline. A batch that is efficient for database writes may be too large for an embedding provider’s token limit. A batch that is efficient for embeddings may create memory pressure during parsing. A good pipeline tracks both item counts and token counts, because embedding throughput is often constrained by tokens as much as by request volume.
Apply Backpressure Between Stages
Backpressure is the mechanism that slows earlier stages when later stages are saturated. Without it, a fast loader can fill memory, produce an unmanageable retry backlog, or send bursts that trigger rate limits. With backpressure, each stage only accepts work at a pace the downstream system can handle.
In practice, backpressure can be implemented with bounded queues, worker pools, adaptive batch sizes, token buckets, or database-aware batching. The important idea is that the pipeline should respond to live conditions. If embedding latency rises, reduce concurrency. If database write errors increase, pause or shrink batch writes. If the source API starts returning throttling responses, slow the loader instead of letting retries multiply.
Separate Online and Offline Ingestion Paths
Not all ingestion needs the same latency. A user-uploaded document may need to become searchable within seconds or minutes, while a historical backfill can run over many hours. Mixing these workloads in the same queue can cause urgent updates to wait behind bulk imports.
A scalable design often separates ingestion into online and offline paths. The online path handles small, freshness-sensitive changes with tighter latency targets. The offline path handles large migrations, re-embedding jobs, and full corpus rebuilds with larger batches and lower urgency. Both paths can share parsing, chunking, and validation logic, but they should not always share the same concurrency limits or queue priority.
Keep Source and Index State in Sync
At scale, ingestion is not just about adding records. It is also about updating and removing records correctly. The pipeline needs a source-of-truth inventory that says which documents exist, which versions have been processed, which chunks were produced, and which database records correspond to them.
This inventory allows the system to detect changed documents, skip unchanged ones, delete stale chunks, and recover from partial failures. It also makes reprocessing more predictable because the pipeline can decide whether a chunk needs parsing, embedding, upserting, or no action at all.
Once throughput is under control, reliability becomes the next concern. Large ingestion jobs will encounter timeouts, throttling, partial writes, malformed files, duplicate events, and worker restarts. The difference between a fragile script and a production pipeline is how calmly it handles those failures.
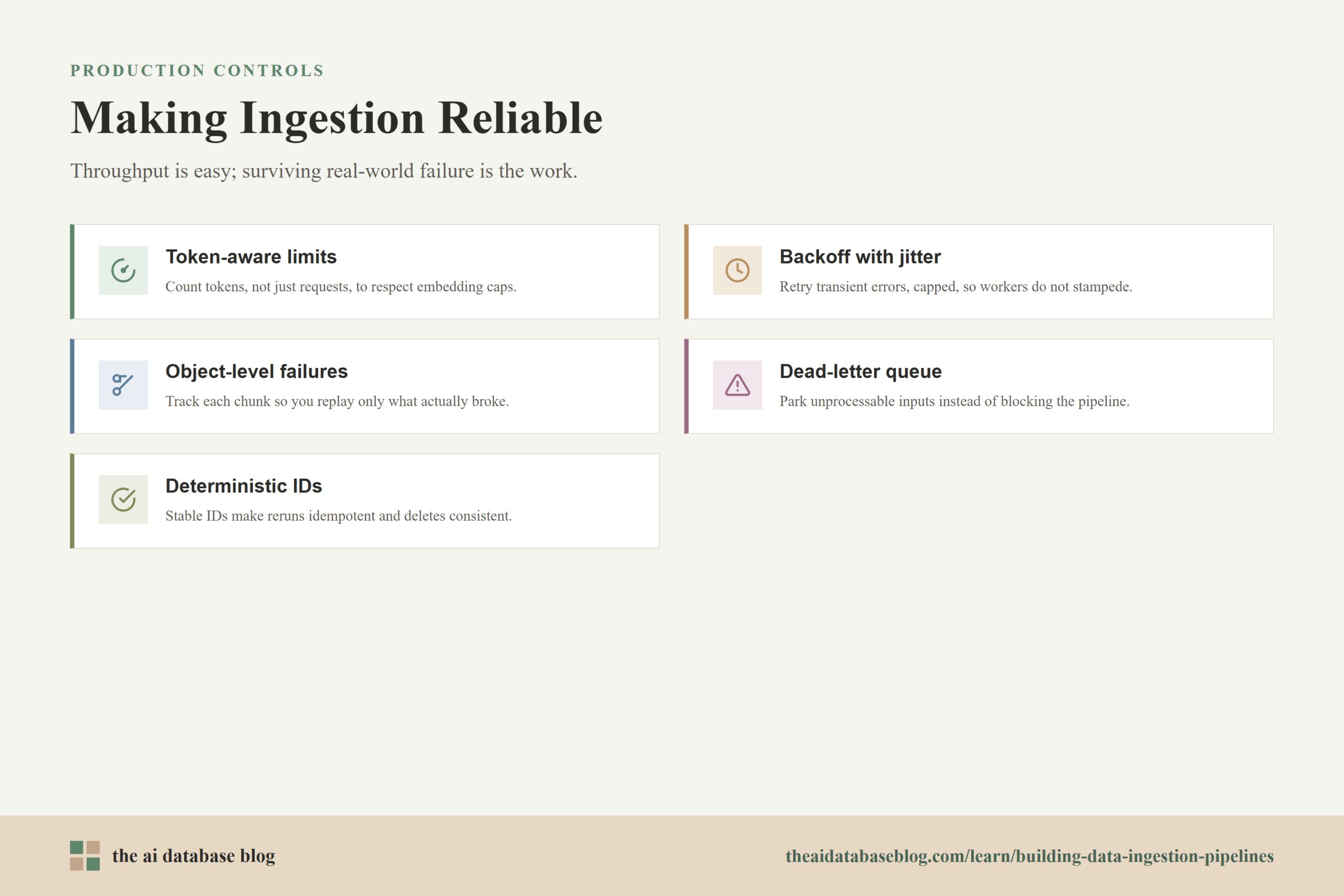
Handling Rate Limits, Retries, and Partial Failures
Rate limits and transient failures are normal in ingestion pipelines. Embedding providers may limit requests per minute, tokens per minute, or batch size. Source systems may throttle exports. AI databases may reject oversized batches, experience temporary write pressure, or return object-level validation errors inside a larger batch. A production pipeline assumes these conditions will happen and makes them recoverable.
Design Around Request and Token Limits
Embedding stages should track both how many requests they send and how many tokens they submit. A pipeline that only counts records can still exceed token limits when documents contain long sections. Token-aware scheduling lets the system build batches that stay within model limits and smooth out work over time.
For high-volume offline embedding, asynchronous batch processing can reduce pressure on synchronous rate limits when the use case allows delayed completion. For freshness-sensitive updates, a synchronous path may still be necessary, but it should be guarded by concurrency limits and queue prioritization. The goal is not to avoid limits completely; it is to make limit behavior predictable enough that ingestion continues without corrupting state.
Use Retries with Exponential Backoff and Jitter
Retries are useful for temporary problems such as network failures, timeouts, server errors, and rate-limit responses. They should not be unlimited. A safe retry policy uses exponential backoff, random jitter, and a maximum attempt count. Backoff prevents the pipeline from hammering a stressed service, while jitter keeps many workers from retrying at exactly the same moment.
The pipeline should classify errors before retrying. A transient timeout may be retried. A malformed document may need to be quarantined. A validation error caused by missing required metadata should fail fast and be reported. Retrying permanent errors wastes capacity and can hide data quality issues.
Capture Object-Level Failures
Batch operations often produce mixed results. Some objects may succeed while others fail because of invalid fields, oversized text, bad vectors, missing tenants, or schema mismatches. The pipeline should record failures at the smallest meaningful unit, usually the chunk or source document, rather than marking the entire job as simply failed.
Object-level failure tracking enables targeted repair. Instead of rerunning a million-record import, the team can inspect the failed objects, fix the source or transformation rule, and replay only the affected items. This approach also improves operational confidence because a large job can finish with a clear accounting of completed, failed, skipped, and retried work.
Use Dead-Letter Queues for Bad Inputs
A dead-letter queue stores items that cannot be processed after the allowed retries. In AI database ingestion, these items might include unreadable files, unsupported formats, chunks that exceed size limits, records with invalid metadata, or source objects that repeatedly fail embedding. Moving them to a dead-letter queue prevents one bad item from blocking the entire pipeline.
The dead-letter queue should include enough context to debug the problem: source identifier, pipeline stage, error type, error message, attempt count, timestamps, and a pointer to the input artifact when safe. It should also support replay after the issue is fixed.
Retries keep the pipeline moving through temporary failure, but retries alone do not make repeated processing safe. To safely rerun jobs, recover from crashes, and process duplicate source events, the pipeline needs idempotency.
Idempotency: Making Ingestion Safe to Rerun
Idempotency means that running the same operation more than once produces the same final state. In an AI database pipeline, this property is essential because ingestion jobs are often restarted, retried, replayed, or run incrementally. Without idempotency, duplicate events can create duplicate chunks, retries can overwrite newer data with older data, and partial failures can leave the index in an uncertain state.
Use Deterministic IDs
A deterministic ID is generated from stable information such as source system, document ID, document version, chunk path, and chunk index or content hash. When the same chunk is processed again, it receives the same ID. That allows the database upsert to replace the existing object rather than creating a duplicate.
The ID design should be stable enough to support reruns but specific enough to reflect meaningful changes. If the ID includes only the document ID, every chunk from the document may collide. If it includes only a raw chunk number, small edits near the top of a document may shift all later chunk numbers and create unnecessary churn. Many systems combine document identity, structural location, and content hash to balance stability and correctness.
Track Processing State Explicitly
A pipeline should know which stage each item has reached. For example, a document may be loaded, parsed, chunked, embedded, upserted, deleted, or failed. This state can live in a metadata store, job table, workflow engine, or event log. The important requirement is that recovery logic can inspect the state and resume from the right point.
Explicit state prevents expensive and risky guessing. If a worker crashes after embedding but before upserting, the system can decide whether to reuse the embedding result or regenerate it. If an upsert succeeds but the acknowledgement is lost, the deterministic ID lets the retry safely write the same object again.
Version Chunking and Embedding Rules
Chunking rules and embedding models change over time. A team may switch from fixed-size chunks to section-aware chunks, add metadata to embedded text, or move to a newer embedding model. Those changes should be versioned because they affect the meaning and comparability of stored vectors.
Versioning makes reprocessing intentional. Records can carry fields such as chunking_version, embedding_model, embedding_version, and preprocessing_version. When any of those values change, the pipeline can identify which records need re-embedding or re-indexing rather than rebuilding everything by hand.
Handle Deletes as First-Class Events
Deletes are part of idempotency. If a source document disappears or a user loses access to it, the AI database should not keep returning old chunks. The pipeline needs a way to map each source object to all derived chunks so it can delete or deactivate them consistently.
Some systems use hard deletes, while others use soft deletes with an active flag and timestamp. The right choice depends on audit requirements, storage constraints, and recovery needs. What matters most is that retrieval queries do not return records that should no longer be visible.
With idempotency in place, the pipeline can survive reruns and retries. The final piece is observability: the ability to see what the pipeline is doing, why it is slow or failing, and how ingestion choices affect retrieval quality.
Keeping Ingestion Observable
Observable ingestion pipelines expose their health, performance, cost, and data quality. This matters because ingestion failures are often subtle. A job may complete successfully while producing chunks that are too large, omitting important metadata, embedding stale content, or leaving a small but important set of documents unindexed. Metrics, logs, traces, and validation checks help teams catch those issues before users experience poor retrieval.
Track Throughput and Latency by Stage
At minimum, the pipeline should report how many documents, chunks, tokens, embeddings, and upserts it processes over time. It should also measure stage-level latency for loading, parsing, chunking, embedding, and database writes. Stage-level metrics reveal bottlenecks that aggregate job duration hides.
For example, an ingestion slowdown may be caused by a source API, a parser, an embedding provider, a saturated queue, or the database write path. If each stage reports queue depth, processing time, success count, and failure count, the team can quickly identify where the slowdown begins.
Measure Error Rates and Retry Behavior
Error metrics should separate transient failures from permanent failures. Useful counters include rate-limit responses, timeouts, validation errors, parse failures, retry attempts, dead-lettered items, and partial batch failures. Retry metrics are especially important because a pipeline can appear healthy while quietly spending most of its time retrying the same failing work.
Dashboards should show both current rates and trends over time. A sudden increase in parse failures may indicate a source format change. A rise in embedding retries may indicate rate-limit pressure or provider latency. A growing dead-letter queue means the pipeline needs attention even if most records are still flowing.
Log Lineage and Provenance
Every indexed chunk should be traceable back to its source. A useful lineage record includes source system, source ID, source version, document title, section path, chunk ID, chunking version, embedding model, ingestion job ID, and timestamps. This information helps debug retrieval results and supports reprocessing when source content or embedding rules change.
Lineage also helps human reviewers understand why a record exists. If a user reports an outdated answer, the team should be able to find the retrieved chunk, inspect the source version, determine when it was embedded, and decide whether the issue came from source freshness, parsing, chunking, retrieval, or generation.
Validate Retrieval Quality After Ingestion
Operational metrics show whether records moved through the pipeline. They do not prove that retrieval works well. A production ingestion process should include quality checks such as sample queries, known-answer tests, metadata filter tests, duplicate detection, chunk length distributions, empty-content checks, and source coverage reports.
These checks connect ingestion to user-facing outcomes. If retrieval quality drops after a chunking change, the team can catch the problem before it reaches production. If a corpus suddenly has many tiny chunks or unusually large chunks, the pipeline can flag the anomaly. In AI databases, ingestion quality and retrieval quality are tightly connected, so both need to be measured.
Observability makes the pipeline easier to operate, but design choices still need to be made before implementation begins. A small set of practical principles can keep those choices grounded.
Practical Design Principles for Production Ingestion
A production ingestion pipeline should be simple enough to reason about and robust enough to survive real-world data. The best designs usually start with a clear contract for each stage: what it receives, what it emits, how it records state, and how it handles failure. From there, the pipeline can evolve without becoming a fragile chain of hidden assumptions.
Preserve Raw and Processed Representations
When possible, keep a pointer to the raw source and store processed artifacts such as extracted text, parsed structure, and generated chunks. This makes debugging much easier. If a retrieved answer is wrong, the team can compare the original source, parsed text, chunk, embedding input, and stored database object.
Preserving intermediate representations also supports reprocessing. If only the embedding model changes, the pipeline may be able to reuse parsed text and chunks. If only chunking changes, it may be able to reuse normalized text. This reduces cost and shortens rebuild time.
Keep Metadata Close to the Chunk
Metadata should travel with the content through the pipeline. Important fields include source ID, title, section heading, URL or path, timestamps, permissions, tenant, language, document type, and version. Metadata should also include pipeline fields such as chunk ID, chunk index, content hash, and embedding model.
This metadata supports filtering, access control, freshness checks, evaluation, and debugging. It also gives retrieval systems more ways to combine semantic similarity with structured constraints. For many applications, metadata quality is as important as embedding quality.
Design for Rebuilds Before You Need Them
Every AI database eventually needs some form of rebuild. The source corpus changes, the chunking strategy improves, the embedding model changes, or the schema needs new metadata. A pipeline that was designed only for the first import will make these changes painful.
Rebuild-friendly ingestion uses deterministic IDs, versioned transformations, source inventories, and separate offline processing capacity. It can run a new index in parallel, compare results, and switch traffic when the new representation is ready. This approach reduces the risk of major ingestion changes.
Make Freshness and Completeness Visible
Freshness measures how current the AI database is compared with the source systems. Completeness measures whether all expected source content is represented. Both should be visible. A search experience can be technically fast and still be wrong if it relies on stale or missing records.
Useful signals include last successful ingestion time by source, number of expected documents, number of indexed documents, number of active chunks, number of deleted chunks, and lag between source update time and database update time. These signals help teams decide whether retrieval results can be trusted.
These principles do not remove the need for engineering judgment, but they make the pipeline easier to adapt. The most common mistakes usually come from treating ingestion as a one-time transformation rather than a living part of the AI application.
Common Mistakes to Avoid
Many ingestion problems look small during a prototype because the corpus is limited and the team can manually inspect the results. At production scale, the same shortcuts can create duplicate records, stale search results, uncontrolled costs, and hard-to-debug relevance issues. Avoiding these mistakes early makes the system easier to operate later.
- Embedding entire documents without chunking. Large documents often contain many topics, so a single vector can become too broad to retrieve precise answers.
- Chunking without preserving structure. Splitting only by character count can cut through headings, tables, procedures, or code examples in ways that reduce retrieval usefulness.
- Dropping source metadata. Without provenance, timestamps, permissions, and document identifiers, the system becomes harder to filter, debug, and refresh.
- Using random IDs for chunks. Random IDs make reruns create duplicates unless the pipeline has another deduplication layer.
- Retrying every error the same way. Permanent data errors should be fixed or quarantined, not retried endlessly.
- Monitoring only job completion. A job can finish while producing poor chunks, stale embeddings, or partial coverage. Stage-level metrics and quality checks are necessary.
These mistakes are avoidable when the pipeline is built around source lineage, controlled throughput, safe replay, and measurable quality. The remaining questions usually involve how to choose defaults and how much complexity is justified for a given workload.
FAQs
1. What is a data ingestion pipeline for an AI database?
A data ingestion pipeline for an AI database is the process that moves source content into a searchable AI-ready store. It usually loads documents or records, extracts clean text, splits content into chunks, generates embeddings, attaches metadata, and upserts the result into a vector or hybrid search database. In production, it also tracks state, handles failures, and keeps the index synchronized with source changes.
2. Why is chunking important before embedding?
Chunking controls what each vector represents. If chunks are too large, each embedding may blend several topics and retrieve imprecise matches. If chunks are too small, they may lack enough context to answer a question. Good chunking creates retrieval units that are focused, meaningful, and connected to useful metadata such as headings, source location, and permissions.
3. How should an ingestion pipeline handle embedding rate limits?
The pipeline should track request volume, token volume, batch size, and concurrency. It should use bounded queues, token-aware batching, backoff, jitter, and maximum retry counts. For large offline jobs, asynchronous batch processing can help when immediate results are not required. The main goal is to keep embedding throughput steady without creating bursts that trigger repeated throttling.
4. What does idempotency mean in AI database ingestion?
Idempotency means the same ingestion work can run more than once without creating duplicate or inconsistent records. This is usually achieved with deterministic chunk IDs, source version tracking, upserts, explicit processing state, and safe delete handling. Idempotency is essential because production ingestion jobs are often retried, restarted, replayed, or rerun after transformation changes.
5. What metrics should be monitored during ingestion?
Useful metrics include documents loaded, chunks created, tokens embedded, batches written, stage-level latency, queue depth, retry counts, rate-limit responses, parse failures, validation errors, dead-lettered items, and source-to-index freshness lag. Quality checks should also track chunk length distribution, empty chunks, duplicate chunks, metadata completeness, and retrieval test results.
6. When should a team rebuild an AI database index?
A rebuild may be needed when the embedding model changes, chunking rules change, source content is heavily updated, metadata requirements change, or retrieval quality falls below expectations. A well-designed pipeline makes rebuilds safer by versioning transformations, preserving source inventories, using deterministic IDs, and allowing a new index to be built and evaluated before replacing the old one.
Takeaway
Building data ingestion pipelines for AI databases means designing a reliable flow from source content to retrieval-ready records. Loading, parsing, chunking, embedding, and upserting are the foundation, but production success depends on the controls around those stages: batching, backpressure, rate-limit handling, retries, idempotency, lineage, and observability. This guidance is most useful for teams building RAG systems, semantic search, knowledge assistants, or recommendation features where source data changes over time and retrieval quality matters. A well-designed ingestion pipeline makes the AI database easier to trust because every chunk can be traced, refreshed, retried, measured, and safely rebuilt when the system evolves.
Watch this video to learn more