Agentic RAG is retrieval-augmented generation where an AI agent controls the retrieval process instead of relying on one fixed search step before generation. In a standard RAG pipeline, the system usually retrieves a set number of chunks, passes them to a language model, and asks the model to answer. In agentic RAG, the agent can decide whether retrieval is needed, what to search for, which source or index to use, how to break a question into smaller retrieval tasks, whether the results are good enough, and when to stop searching. This makes agentic RAG useful for complex, multi-step, ambiguous, or high-stakes questions, but it also adds latency, cost, and evaluation complexity.
This guide explains how agentic RAG works, why it differs from traditional RAG, and what it means to let an agent decide when, what, and how often to retrieve. It covers query decomposition, follow-up retrieval, evaluation loops, answer synthesis, and the practical trade-offs teams need to manage when building retrieval systems for AI applications.
What Agentic RAG Means
Agentic RAG turns retrieval from a fixed preprocessing step into an active decision inside a reasoning loop. The system still uses the same broad ingredients as RAG: a user question, a retrieval layer, a knowledge source, and a language model that generates an answer. The difference is that the retrieval layer is exposed to the model or orchestration system as a tool that can be called when needed. The agent is not simply handed context; it participates in deciding how context should be gathered.
In a traditional RAG flow, the query is often embedded or rewritten once, matched against a vector index or hybrid search system, and used to fetch the top results. That approach works well for many direct questions, especially when the user asks something that maps cleanly to a known document, policy, record, or knowledge base entry. Agentic RAG becomes more useful when the question is not cleanly answerable from one retrieval pass.
For example, a user might ask, “Why did support escalations increase after the pricing change, and which product areas were most affected?” A basic RAG pipeline may retrieve documents about pricing, support tickets, and product areas, but it may not know which part of the question to investigate first. An agentic RAG system can split the task into smaller questions, search support data, search product release notes, compare time periods, and retrieve again if the first results do not explain the change.
This shift matters because retrieval quality often determines answer quality. If the system retrieves weak evidence, the language model may produce an answer that sounds coherent but rests on incomplete or irrelevant context. Agentic RAG tries to improve that process by giving the system a way to inspect, revise, and repeat retrieval before committing to an answer.
Once retrieval becomes a decision rather than a fixed step, the next question is what the agent is actually deciding. The most important decisions are when to retrieve, what to retrieve, where to retrieve from, how many times to retrieve, and whether the retrieved evidence is strong enough to support an answer.

How an Agent Decides When to Retrieve
The first decision in agentic RAG is whether retrieval is needed at all. Not every user request requires external knowledge. Some requests are simple transformations, summaries of already provided text, or general reasoning tasks where retrieving from a database would only add cost and noise. A useful agentic system should avoid retrieval when the answer can be produced safely from the current conversation, supplied context, or known instructions.
This decision is often handled through a routing step. The agent classifies the query as answerable without retrieval, requiring retrieval, requiring multiple retrieval sources, or requiring clarification before retrieval. This routing can be implemented with prompts, rules, lightweight classifiers, or a larger planning model, depending on how much reliability and control the application needs.
The agent may choose retrieval when the question asks about private data, recent information, domain-specific facts, citations, policies, numbers, records, or anything where factual grounding matters. It may also retrieve when the user asks a follow-up question that depends on information not currently in the conversation. In that case, retrieval is not only about adding facts; it is about restoring the missing context needed to answer accurately.
Good retrieval timing reduces two common failure modes. The first is under-retrieval, where the system answers from memory even though it needs evidence. The second is over-retrieval, where the system retrieves for every request, fills the context window with unnecessary passages, and increases both cost and confusion. Agentic RAG aims for a middle path: retrieve when evidence improves the answer, and skip retrieval when it does not.
Deciding when to retrieve is only the beginning. Once the agent has decided that outside context is needed, it must determine what kind of information to search for. That is where query planning and decomposition become central.
How an Agent Decides What to Retrieve
In agentic RAG, the user’s original wording is not always the best retrieval query. Natural language questions can be vague, conversational, overloaded with multiple tasks, or missing terms that appear in the database. The agent’s job is to translate the user’s intent into one or more search actions that are more likely to retrieve useful evidence.
This often starts with query rewriting. If a user asks, “What changed after the rollout?” the agent may rewrite the query into a more specific search, such as “documents mentioning the rollout date, release notes, incident reports, adoption metrics, and post-launch support issues.” The rewritten query is not meant to replace the user’s question; it is a retrieval aid that helps the database surface better context.
The agent may also choose among retrieval strategies. A semantic vector search can find conceptually related passages even when the wording differs. Keyword or sparse search can be better for exact names, codes, error messages, and identifiers. Hybrid search combines semantic and lexical signals. Metadata filtering can restrict retrieval to a time period, tenant, product area, document type, permission group, or other structured field. In many AI database systems, strong agentic retrieval depends on exposing these choices clearly so the agent can use the right retrieval path for the task.
The most important principle is that the retrieval query should match the information need, not just the surface form of the user prompt. A user may ask one question that actually requires definitions, evidence, comparisons, dates, and exceptions. Agentic RAG gives the system room to search for each of those pieces instead of hoping one top-k result set covers everything.
When the information need has multiple parts, a single rewritten query may still be too broad. The next step is decomposition: breaking the original question into smaller retrieval tasks that can be answered, checked, and combined.
Query Decomposition in Agentic RAG
Query decomposition is the process of splitting a complex user request into smaller sub-questions. This is one of the clearest reasons to use agentic RAG instead of a simple retrieve-and-generate pipeline. Many real questions are multi-hop: the answer depends on several pieces of evidence that may live in different documents, tables, chunks, or systems.
Consider the question, “Which customer segments are most likely to be affected by the new data retention policy, and what should our support team prepare for?” An agent might decompose this into several retrieval tasks:
- Find the new data retention policy and identify the actual policy changes.
- Retrieve customer segments or account types affected by those changes.
- Search support history for questions related to retention, deletion, compliance, or account access.
- Look for internal guidance, exceptions, or escalation paths.
- Synthesize likely support needs based on the retrieved evidence.
Each sub-question can be searched separately, and each result can be evaluated before the system moves forward. This improves coverage because the retriever is no longer trying to satisfy every part of the original prompt with one query. It also improves reasoning because the answer can be built from intermediate findings rather than from a large, mixed bundle of retrieved text.
Decomposition can happen sequentially or in parallel. Sequential decomposition works well when each step depends on the previous step. Parallel decomposition works well when the agent can search several independent parts of the question at once, then merge the results. In production systems, parallel retrieval can reduce latency, but it may increase total retrieval volume and make result ranking more complex.
Decomposition is powerful, but it can also go wrong. If the agent creates the wrong sub-questions, it may retrieve confidently from the wrong evidence. If it creates too many sub-questions, it may spend unnecessary tokens and retrieval calls. The best systems constrain decomposition with clear task boundaries, useful metadata filters, and evaluation checks that ask whether each sub-result actually helps answer the original user question.
Once the agent has decomposed the question and retrieved initial evidence, it still needs a way to decide whether the search was successful. This is where follow-up queries and evaluation loops turn agentic RAG from a planner into an iterative retrieval system.
Follow-Up Queries and Retrieval Loops
Follow-up retrieval is one of the defining behaviors of agentic RAG. Instead of retrieving once and answering immediately, the agent reviews the retrieved context and decides whether more information is needed. This loop can improve answer quality when the first retrieval is incomplete, contradictory, stale, too general, or focused on the wrong part of the question.
A typical loop looks like this: the agent plans a retrieval query, retrieves documents or records, evaluates the results, revises the query if needed, retrieves again, and stops when the evidence is sufficient. The stop condition is important. Without a clear stopping rule, an agent can keep searching even when additional retrieval is unlikely to improve the answer.
Follow-up queries usually fall into several patterns:
- Refinement queries: The agent narrows a broad query after seeing initial results. For example, it may move from “billing errors” to “billing errors after invoice migration in enterprise accounts.”
- Expansion queries: The agent searches adjacent terms or related concepts when the first query returns too little. This is useful when documents use different language than the user.
- Verification queries: The agent searches for supporting or conflicting evidence before making a claim. This helps when retrieved passages disagree or when the answer affects an important decision.
- Source-switching queries: The agent moves from one source to another, such as from policy documents to support tickets or from product docs to usage records.
These loops are especially useful for research-style tasks, analytical questions, troubleshooting, compliance review, and questions that span multiple knowledge sources. They are less useful for simple lookup tasks where one accurate retrieval is enough. In those cases, repeated retrieval may add cost without improving the answer.
Retrieval loops are only as useful as the evaluation step that controls them. The agent needs some way to judge whether the retrieved material is relevant, complete, and trustworthy enough to support generation.
Evaluation Loops: How the Agent Judges Retrieved Context
An evaluation loop asks whether the retrieved evidence is good enough before the final answer is generated. This is a major difference between basic RAG and more agentic retrieval patterns. In a basic pipeline, the model may receive whatever the retriever returns. In an agentic pipeline, the system can grade, rerank, filter, or retry retrieval based on the quality of the results.
Evaluation can happen at several levels. At the document level, the system checks whether each retrieved passage is relevant to the query. At the set level, it checks whether the collection of retrieved passages covers the full question. At the answer level, it checks whether the draft answer is supported by the retrieved evidence. At the trajectory level, it reviews the sequence of agent decisions: which queries were run, which sources were searched, which results were accepted, and why the loop stopped.
Research patterns such as Self-RAG and Corrective RAG helped popularize the idea that retrieval should be adaptive rather than blindly fixed. Self-RAG focuses on retrieval and self-reflection, allowing a model to decide when retrieval is useful and critique retrieved passages. Corrective RAG introduces the idea of evaluating retrieval quality and taking corrective actions when the retrieved context is weak. In practical systems, the same ideas often appear as retrieval grading, result filtering, query rewriting, fallback search, and answer verification.
Evaluation does not have to rely only on the language model’s self-judgment. Stronger systems often combine several signals, including retrieval scores, reranker scores, metadata constraints, freshness checks, source authority, citation coverage, and human-labeled evaluation sets. For sensitive applications, teams may also log each retrieval step and review failures to understand whether the problem came from chunking, indexing, query rewriting, routing, generation, or the agent’s stopping decision.
The goal is not to make the agent endlessly skeptical. The goal is to give the system enough evidence awareness to avoid answering from poor context. That balance leads directly to one of the hardest practical questions in agentic RAG: how much retrieval is worth the cost?
Cost and Latency Trade-Offs
Agentic RAG can improve answer quality, but it is not free. Every additional retrieval step may add database calls, reranking work, model tokens, orchestration overhead, and waiting time for the user. If the agent decomposes one prompt into five sub-queries, evaluates each result set, and performs two follow-up searches, the answer may be much better than a one-shot RAG answer. It may also be slower and more expensive.
The main cost trade-off is between retrieval depth and efficiency. More retrieval can improve recall, especially for multi-hop questions, but it can also add irrelevant context and increase the chance that the model sees conflicting or low-value evidence. Less retrieval is faster and cheaper, but it may miss the key document or fail to cover one part of the question. Agentic RAG makes this trade-off explicit because the system can choose different retrieval depth for different query types.
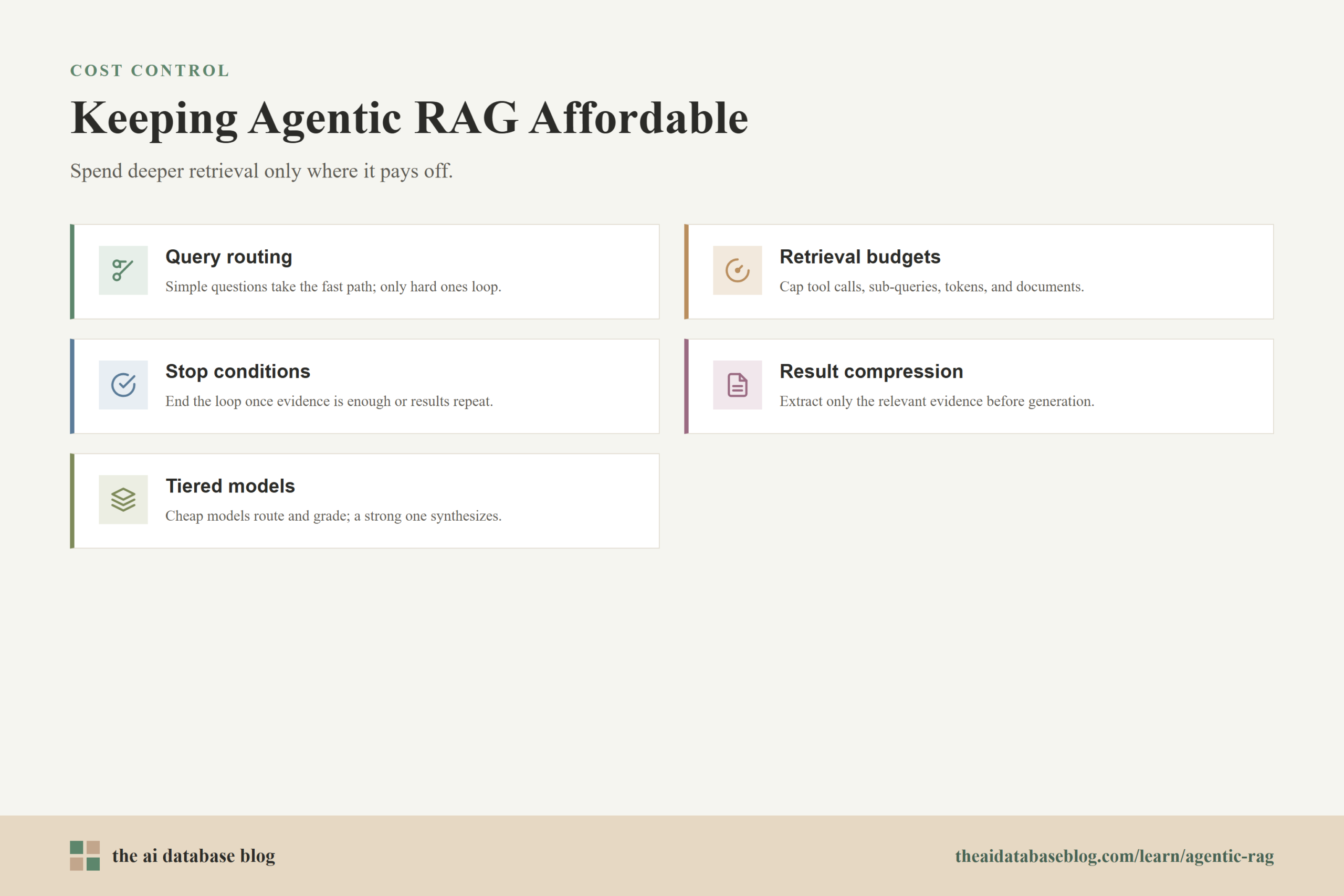
Common cost controls include:
- Query routing: Use simple retrieval for simple questions and deeper agentic loops only for complex questions.
- Retrieval budgets: Limit the number of tool calls, sub-queries, tokens, or documents the agent can use.
- Stop conditions: End the loop when the agent has enough evidence, when additional results repeat what is already known, or when confidence remains low after a fixed number of attempts.
- Result compression: Summarize or extract only relevant evidence before sending context to the final generation step.
- Tiered models: Use smaller or cheaper models for routing, query rewriting, or grading, and reserve stronger models for final synthesis or difficult judgments.
Latency also affects user experience. A deep agentic retrieval loop may be acceptable for a research report, compliance investigation, or complex troubleshooting session. It may be frustrating for a simple customer support answer or an interactive chat where users expect near-instant responses. Production systems often need modes: a fast path for direct questions and a deeper path for questions that justify more retrieval work.
Cost control does not mean avoiding agentic RAG. It means applying it where the added reasoning and retrieval control are likely to pay off. To do that well, teams need to understand where agentic RAG is strongest and where simpler RAG remains the better design.
When Agentic RAG Is Useful
Agentic RAG is most useful when the user’s question requires planning, evidence gathering, and iteration. It is a good fit for questions that span multiple documents, require multi-hop reasoning, involve ambiguous wording, depend on different data sources, or need verification before the system answers. These are the situations where a fixed top-k retrieval step often fails quietly.
Strong use cases include internal research assistants, technical support agents, compliance review tools, policy question answering, financial document analysis, scientific literature exploration, and enterprise knowledge retrieval. In these settings, the system often needs to search across document types, compare evidence, resolve terminology, and explain how the answer was grounded.
Agentic RAG can also help when the user’s question changes over the course of a conversation. A user might start with a broad question, ask a narrowing follow-up, then ask for a comparison against a different policy or time period. An agent that can retrieve on demand is better suited to this kind of evolving context than a pipeline that retrieves once at the start.
However, agentic RAG is not automatically better for every application. If most questions are simple, repetitive, and answerable from one source, a well-designed standard RAG system may be faster, cheaper, and easier to evaluate. The best architecture is the simplest one that reliably answers the user’s actual questions.
Choosing agentic RAG becomes easier when the system design is grounded in the data layer. Retrieval tools, metadata, indexing strategy, and evaluation data all shape whether the agent can make useful decisions or simply loop around weak retrieval.
What This Means for AI Database Design
Agentic RAG places new demands on the AI database layer because the agent needs more than a single vector search endpoint. It needs retrieval tools that are expressive, controllable, and observable. The database should make it possible to search semantically, filter by metadata, combine keyword and vector signals, retrieve by document structure, and return enough evidence for the agent to judge relevance.
Metadata quality becomes especially important. If the agent can filter by date, source type, customer segment, permission group, product area, version, or document status, it can ask sharper questions and avoid irrelevant results. Without reliable metadata, the agent may compensate by running more searches, which increases cost and still may not improve relevance.
Chunking and indexing also matter. If chunks are too small, the agent may retrieve fragments that lack enough context. If chunks are too large, the model may receive irrelevant text and waste context window space. Some systems benefit from hierarchical retrieval, where the agent first finds a document, section, entity, or topic cluster, then drills down into the most relevant passages. This can help with long documents and complex knowledge bases.
Observability is another requirement. Teams should be able to inspect the retrieval path: the original question, rewritten queries, filters used, sources searched, documents retrieved, evaluation scores, follow-up queries, and final evidence used in the answer. Without this trace, it is difficult to debug failures or understand why cost increased.
An agentic RAG system is only as strong as the retrieval environment it can act on. The agent may make better decisions than a static pipeline, but it still depends on accurate indexes, useful metadata, permission-aware retrieval, and evaluation signals that reveal whether the evidence is actually good.
Practical Design Pattern for Agentic RAG
A practical agentic RAG workflow usually starts simple and adds complexity only where it improves outcomes. The goal is not to give the agent unlimited freedom. The goal is to give it structured choices that match the retrieval problems users actually have.
A common design pattern looks like this:
- Classify the question. Decide whether the user needs no retrieval, simple retrieval, multi-source retrieval, or a deeper agentic loop.
- Plan the retrieval task. Rewrite the query, identify constraints, choose sources, and decide whether decomposition is needed.
- Retrieve evidence. Use vector search, keyword search, hybrid search, metadata filters, or structured lookups as appropriate.
- Evaluate the results. Grade relevance, completeness, freshness, and source fit before answering.
- Run follow-up retrieval if needed. Refine, expand, verify, or switch sources when the first retrieval is not enough.
- Synthesize the answer. Generate a response grounded in the accepted evidence and avoid claims that the retrieved context does not support.
- Log the trajectory. Store the retrieval path and evaluation signals so the system can be tested, debugged, and improved.
This pattern keeps the agent’s autonomy bounded. The agent can make useful decisions, but the system still controls available tools, budgets, filters, permissions, and stopping rules. That structure is what makes agentic RAG practical rather than unpredictable.
With the design pattern in place, the final question is how teams should measure whether agentic RAG is actually better than simpler retrieval. The answer depends on evaluating both final answers and the retrieval process that produced them.
How to Evaluate Agentic RAG
Agentic RAG should be evaluated at more than one layer. It is not enough to ask whether the final answer sounds good. The system may produce a fluent answer while using weak evidence, skipping an important source, or spending too much on unnecessary retrieval. Evaluation needs to measure the answer, the retrieved context, and the agent’s decision path.
Useful evaluation questions include:
- Did the system retrieve when retrieval was actually needed?
- Did it avoid retrieval when retrieval was unnecessary?
- Did query decomposition cover the important parts of the question?
- Were the retrieved passages relevant, complete, current, and permission-appropriate?
- Did follow-up queries improve the evidence or just add cost?
- Was the final answer supported by the retrieved material?
- Did the system stop at the right time?
Teams often need test sets that include simple questions, ambiguous questions, multi-hop questions, questions with conflicting evidence, questions requiring different sources, and questions where the correct behavior is to say that the available evidence is insufficient. This matters because an agentic RAG system can fail in more ways than a standard RAG system. It can retrieve the wrong context, plan the wrong sub-questions, loop too long, stop too early, or synthesize beyond the evidence.
Good evaluation should also include cost and latency metrics. A system that improves answer quality by a small amount but triples response time may not be worthwhile for interactive use. A system that spends more only on complex queries may be a better trade-off. The most useful comparison is not agentic RAG versus standard RAG in the abstract; it is whether the agentic path improves the specific question types that matter to the application.
Evaluation brings the whole design back to the central idea: agentic RAG is about controlled retrieval decisions. The system should be judged not only by what it answers, but by whether it retrieved the right evidence in a reasonable number of steps.
FAQs
1. What is agentic RAG in simple terms?
Agentic RAG is RAG where an AI agent helps control retrieval. Instead of retrieving once before answering, the agent can decide whether to search, what to search for, which source to use, whether the results are good enough, and whether another search is needed.
2. How is agentic RAG different from traditional RAG?
Traditional RAG usually follows a fixed pattern: retrieve relevant context, then generate an answer. Agentic RAG adds a decision loop. The system can plan retrieval, break the question into sub-questions, run follow-up searches, evaluate results, and adapt its retrieval strategy before answering.
3. When should an agent decide not to retrieve?
An agent should skip retrieval when the user is asking for a simple transformation, a response based entirely on provided context, or a general task where external evidence is not needed. Skipping unnecessary retrieval reduces cost, latency, and the risk of adding irrelevant context.
4. Why is query decomposition important in agentic RAG?
Query decomposition helps when one user question contains several smaller information needs. By splitting a complex question into sub-queries, the system can retrieve more targeted evidence for each part and then synthesize a more complete answer.
5. What are evaluation loops in agentic RAG?
Evaluation loops are checks that happen before the final answer is produced. The agent or supporting system reviews whether retrieved documents are relevant, whether the evidence covers the question, and whether another retrieval step is needed. This helps prevent answers based on weak or incomplete context.
6. What is the main downside of agentic RAG?
The main downside is added complexity. Agentic RAG can require more model calls, more retrieval calls, more logging, more evaluation, and more careful cost control. It is often worth it for complex questions, but it may be unnecessary for simple lookup use cases.
Takeaway
Agentic RAG gives retrieval systems more flexibility by letting an agent decide when to retrieve, what to search for, how to decompose complex questions, when to run follow-up queries, and when the evidence is strong enough to answer. This is most useful for teams building AI applications that need reliable knowledge retrieval across complex documents, private data, or multi-step workflows, such as internal research, support, policy review, and technical troubleshooting. The practical lesson is that agentic RAG should be used deliberately: it can improve relevance and reasoning when standard RAG is too rigid, but it needs retrieval budgets, evaluation loops, strong metadata, and clear stopping rules to keep cost and latency under control.
Watch this video to learn more