Consistency in a vector database describes what an application can expect to see after data is written, updated, deleted, embedded, and indexed. Strong consistency gives the application a tighter guarantee that reads reflect completed writes, while eventual consistency accepts a short delay before all replicas or index segments show the latest state. For retrieval-augmented generation, the practical question is not only whether a write was saved, but whether the retriever can see the right vector, metadata, source text, and deletion state at the moment an answer is generated.
This guide explains how eventual and strong consistency apply to vector writes and index updates, why read-after-write behavior can be different from ordinary database reads, and how these guarantees affect freshness in RAG systems. By the end, you should understand how consistency choices shape user expectations, retrieval correctness, and the operational design of AI applications that depend on current knowledge.
What Consistency Means in a Vector Database
In a traditional database, consistency is often discussed around whether a read reflects the latest committed write. In a vector database, that same idea still matters, but it is only part of the story. A vector record usually includes an embedding, an object identifier, metadata, and sometimes the source text or a pointer back to a source document. The system may also maintain an approximate nearest neighbor index, replicas, shards, caches, and background compaction jobs that all need to converge on the same view of the data.
That means a write can be accepted before every part of the retrieval path has fully caught up. The record may be durably stored, but not yet visible to vector search. A metadata update may be visible in a direct lookup, but not reflected in filtered search results. A delete may remove the source object, while a stale vector entry remains searchable for a short period if index cleanup is asynchronous.
The most important distinction is between the storage layer and the search layer. The storage layer answers whether the database has accepted and retained the data. The search layer answers whether a query can retrieve it through vector similarity, keyword matching, metadata filtering, or hybrid search. Good consistency design needs to account for both layers because RAG applications usually rely on the search path, not only on direct key-value reads.
Once consistency is viewed as a retrieval-path property, the next question is how strict that property needs to be. Some applications can tolerate a short delay between ingestion and search visibility. Others need a user to upload a document, ask a question immediately, and receive an answer based on that exact document. That difference is where eventual and strong consistency become practical design choices rather than abstract database terms.
Eventual Consistency for Writes and Index Updates
Eventual consistency means the system is allowed to return reads from a state that has not fully incorporated the latest completed write, as long as replicas and indexes converge when no new updates interfere. In vector databases, this model is common because large search indexes are expensive to update synchronously across every shard and replica. The system may accept a write quickly, place it in a log or storage layer, and then update searchable index structures in the background. This keeps ingestion and query throughput high, but it creates a period where search results may be stale.
For inserts, eventual consistency can mean a newly added vector is not immediately returned by similarity search. For updates, it can mean search returns an older embedding, older metadata, or an older source-text pointer until the update propagates. For deletes, it can mean a recently removed item is still retrievable for a brief time, especially if deletion is processed as a marker that later removes or hides the item from index segments.
The delay may be very small in a healthy system, but applications should not treat it as zero unless the database explicitly guarantees that. The visible delay can also vary by workload. Bulk ingestion, high write volume, multi-region replication, index rebuilds, or asynchronous embedding pipelines can all stretch the time between “write accepted” and “search can reliably see the new state.”
Eventual consistency is not inherently bad. It is often the right tradeoff for knowledge bases, recommendation systems, semantic search over slowly changing corpora, and analytics-style workloads where a few seconds of freshness lag does not harm the user experience. The problem appears when an application behaves as if it has strong read-after-write behavior while the retrieval path is actually eventual.
Understanding eventual consistency helps explain why the same RAG system may feel reliable on static documentation and unreliable on live operational data. If the corpus changes rarely, a short indexing delay may be invisible. If users are constantly adding, editing, and deleting content, the freshness window becomes part of the product behavior, and the application needs to make that behavior explicit.
Strong Consistency for Writes and Index Updates
Strong consistency means that once a write is acknowledged, later reads see that write according to the system’s stated rules. In the strictest form, every read observes the latest completed write as if operations happened in a single global order. For vector search, a strong guarantee is harder to provide than for simple key-value access because the read may depend on distributed index structures, replica coordination, filtering state, and sometimes separate embedding generation. The more of that path the guarantee covers, the more useful it is for immediate retrieval.
A database might provide strong consistency for direct object reads but not for vector search visibility. For example, a lookup by ID may return the latest object immediately after the write, while nearest neighbor search may need a refresh before the new vector participates in ranking. This distinction matters because RAG usually asks the database to search, not just fetch a known identifier.
Strong consistency can also be scoped. A system may guarantee that reads within one partition see the latest writes, while cross-shard search has weaker behavior. It may provide strong consistency within a region but eventual replication across regions. It may offer a consistency level setting that trades latency for fresher reads. These details decide whether the guarantee supports the application’s actual query pattern.
The cost of stronger consistency is usually coordination. The system may wait for replicas to acknowledge writes, refresh index readers before search, route reads to a primary copy, or block queries until a newer snapshot is available. These choices can increase latency, reduce write throughput, or make availability more sensitive to slow nodes. In many AI database workloads, the right answer is not always maximum strictness, but a clear match between consistency guarantees and freshness requirements.
Strong consistency is most valuable when users expect immediate correctness after their own actions. A user who uploads a policy, changes a permission, deletes a sensitive document, or edits a customer record may reasonably expect the next AI answer to reflect that action. If the database or pipeline cannot guarantee that behavior, the application needs compensating controls such as waiting for indexing completion, verifying source records before generation, or separating fresh writes from the main index.
Read-After-Write Expectations
Read-after-write consistency is the expectation that after a user or application writes data, a following read by that same user or session can see the change. This is often the consistency behavior people notice first because it maps directly to product experience. If a user uploads a document and immediately asks a question about it, they expect the system to know the document exists. If a user deletes a file and asks a follow-up question, they expect the system not to cite it.
In vector databases, read-after-write can break in several places. The object may be stored but the embedding may not have been generated yet. The embedding may be stored but not yet inserted into the searchable index. The searchable index may include the vector, but metadata filters may not yet reflect updated permissions or document status. The retriever may return a stale result from a replica or cache even though a newer state exists elsewhere.
Because of those stages, applications should define read-after-write in operational terms rather than assuming it means one thing. A useful definition might be: after an upload completes, vector search over that user’s workspace returns the new chunks and does not return replaced chunks. Another definition might be: after a delete completes, no generated answer can cite the deleted source, even if the vector index has not fully compacted. These are stronger and more testable promises than simply saying the database is consistent.
There are several common ways to support read-after-write expectations. The application can wait for an indexing completion signal before telling the user the document is ready for AI search. It can use a session-level freshness token or update sequence number if the database exposes one. It can read from a newer snapshot, route the user’s next query to a fresh partition, or temporarily combine the main index with a small fresh index for recent writes. It can also perform a final source-of-truth check before sending retrieved context to the language model.
The right approach depends on how costly staleness is. For a public help center, a short delay after an article update may be acceptable. For a permissions-sensitive internal assistant, a stale read after a delete or access change can be a serious correctness and security issue. That is why read-after-write behavior should be treated as a product requirement, not just a database configuration choice.

Why Index Updates Are Different From Ordinary Writes
Vector indexes are optimized to find approximate nearest neighbors quickly across large collections. Many index structures are built around graph traversal, quantization, clustering, segment files, or other representations that are more complex than a simple row insert. Updating those structures can require background work, batching, rebuilding, or refreshing a query-visible snapshot. As a result, the write path and the search-visible index path may not complete at the same time.
This is especially important for approximate search. A new vector can be present in storage but not yet connected into the graph or segment structure that the query engine traverses. An updated vector can temporarily behave like two versions if the old one is still visible while the new one is being added. A deleted vector may need tombstone handling so queries can ignore it before the underlying index is physically cleaned up.
Metadata filtering adds another layer. A RAG query often retrieves chunks where the vector is similar and the metadata matches constraints such as tenant, document type, language, freshness date, access level, or lifecycle status. If vector updates and metadata updates are applied at different times, search can return results that are semantically relevant but no longer valid for the filter state the application expects.
Hybrid search can create similar challenges. If lexical indexes, vector indexes, and metadata filters refresh on different schedules, the combined result set may briefly mix states. A document might appear in keyword results but not vector results, or a new embedding might be searchable before a related text index has refreshed. This does not mean hybrid search is unreliable, but it does mean consistency must be considered across all retrieval signals.
Once index updates are understood as a separate stage, RAG freshness becomes easier to reason about. The application is not only waiting for a database write. It is waiting for a chain of source update, parsing, chunking, embedding, vector storage, metadata update, index refresh, cache invalidation, and retrieval visibility. A freshness guarantee is only as strong as the weakest stage in that chain.
What Consistency Guarantees Mean for RAG Freshness
RAG freshness means the generated answer is based on the current version of the knowledge the application is supposed to use. A vector database consistency guarantee contributes to freshness, but it does not guarantee freshness by itself. The model can only answer from what the retriever provides, and the retriever can only provide what has been correctly ingested, embedded, indexed, filtered, and validated. Freshness is therefore an end-to-end property of the RAG system.
Eventual consistency can cause a RAG system to miss new facts. A newly uploaded document may not appear in search results yet, so the model answers from older context or says it cannot find information. It can also cause the system to include old facts. If an updated procedure replaced an earlier version, stale chunks may still rank highly until the old vectors are removed or hidden.
Deletes and permissions changes are especially sensitive. If a document is deleted from the source system but still appears in vector search, the model may cite content that should no longer be used. If a user’s access changes but metadata filters lag behind, the system can retrieve context the user should not see. These cases are not only freshness issues; they can become trust, compliance, or security issues depending on the application.
Strong consistency can reduce these risks, but it still needs the right scope. A strong write to the vector database does not help if the embedding pipeline is delayed or if source documents are updated outside the ingestion process. A strongly consistent object lookup does not help if the application relies on vector search results from a stale index snapshot. For RAG, the meaningful guarantee is usually: the answer uses a coherent, allowed, current set of chunks for the relevant user and point in time.
Freshness can also be measured. Useful metrics include indexing lag, embedding lag, delete propagation time, percentage of queries served from the latest known version, stale citation rate, and the age of retrieved chunks relative to the source-of-truth update time. These metrics turn consistency from an abstract database property into something teams can observe and improve.
With RAG freshness framed as an end-to-end guarantee, the next step is choosing the consistency behavior that matches the use case. Not every application needs immediate visibility for every update, but every application should know the freshness window it is accepting. That window should be reflected in ingestion design, user messaging, evaluation, and safety checks.
Choosing the Right Consistency Model for an AI Application
The best consistency model depends on how users interact with the data and how harmful stale retrieval would be. Static or slowly changing knowledge bases can often use eventual consistency without a poor experience. Live user memory, operational records, permissions-sensitive content, and regulated documents usually need stronger guarantees or additional verification. The decision should be based on user expectations and risk, not only on database performance.
Eventual consistency is a good fit when the application values high throughput, low latency, and broad availability more than instant update visibility. Examples include semantic search over archived documents, product discovery where inventory freshness is handled elsewhere, or internal knowledge bases where article updates can take a short time to appear. In these systems, the main requirement is to keep the freshness lag small, observable, and acceptable.
Stronger consistency or explicit freshness gating is a better fit when users write and query in the same workflow. Examples include uploading a document and immediately asking questions, editing AI memory during a session, revoking access to a file, or updating policies that affect current decisions. In these cases, the application may need to wait until indexing completes, query a fresh-write buffer, or validate retrieved chunks against the source of truth before generation.
Many production systems use a mixed approach. The main vector index may be eventually consistent for scale, while recent writes are searched through a smaller fresh layer. Deletes and permission changes may be enforced through a strongly consistent source-of-truth check even if the index cleanup is asynchronous. Query responses may include only chunks whose version, timestamp, or content hash matches the current source record.
The important principle is to avoid pretending that all data has the same freshness requirement. A new marketing page, a medical instruction, a contract clause, and a user-specific permission update should not necessarily be treated with the same consistency policy. Good AI database design separates low-risk freshness lag from high-risk correctness requirements.
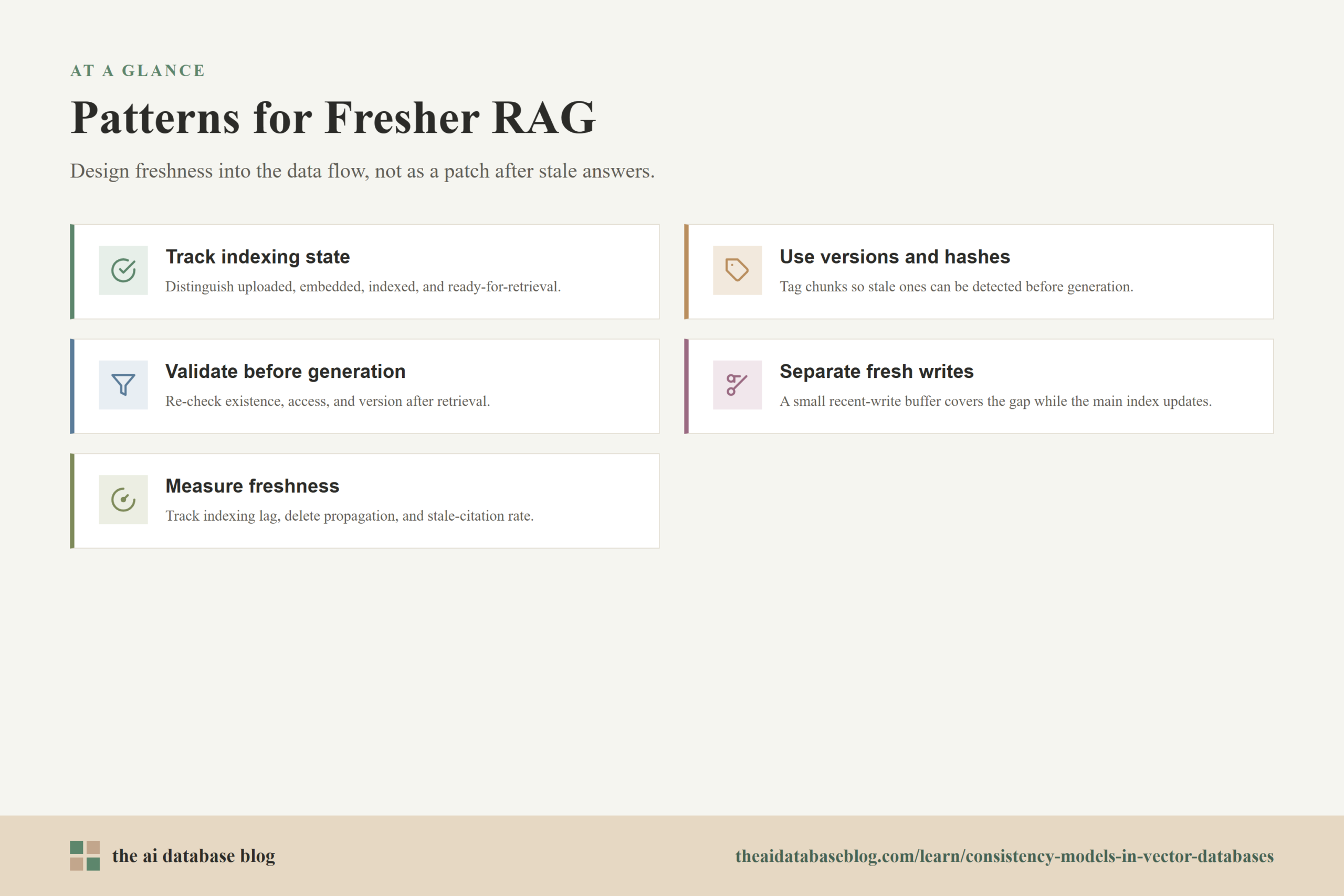
Practical Design Patterns for Fresher RAG
RAG systems become more reliable when freshness is designed into the data flow instead of patched after stale answers appear. The vector database is one component, but the application also needs versioning, ingestion tracking, and retrieval validation. These patterns help teams make consistency expectations visible and enforceable. They are useful whether the underlying database provides eventual consistency, strong consistency, or configurable consistency levels.
Track indexing state explicitly
Applications should distinguish between “uploaded,” “embedded,” “indexed,” and “ready for retrieval.” A document should not be presented as ready for AI search until the relevant chunks and metadata are query-visible. This avoids the common situation where a user sees a successful upload message but the retriever still cannot find the document.
Use versions, timestamps, and content hashes
Each chunk should carry enough information to identify the source document version it came from. Version numbers, update timestamps, and content hashes help the application detect stale chunks before they are passed to the model. They also make debugging easier because teams can reconstruct which version of the knowledge base produced an answer.
Validate retrieved chunks before generation
For sensitive systems, retrieval should not be the final authority. After vector search returns candidate chunks, the application can re-check that each source still exists, the user still has access, and the chunk version still matches the current source. This pattern is especially valuable for deletes, permissions, and frequently updated documents.
Separate fresh writes from the main index
A small fresh index or recent-write buffer can cover the gap while the main index updates asynchronously. The query layer can search both the fresh layer and the main index, then merge and rank results. This gives users faster read-after-write behavior without forcing the entire large index to refresh synchronously for every update.
Measure freshness as a reliability metric
Freshness should be monitored like latency or error rate. Teams can track how long it takes for new chunks to become searchable, how long deleted chunks remain retrievable, and how often answers cite outdated content. Without measurement, eventual consistency becomes an invisible source of retrieval errors.
These patterns do not eliminate the need to understand the database’s consistency model. They make that model usable in an application that has real user expectations. The goal is not always to force strict consistency everywhere, but to make sure the application knows when data is fresh enough to trust.
Common Mistakes to Avoid
The most common mistake is assuming that a successful write means immediate search visibility. In many vector systems, those are different events. A write acknowledgment may mean the record was accepted, while query visibility depends on index refresh, replica propagation, or background processing. Applications that ignore this distinction often produce confusing first-run experiences after uploads and updates.
Another mistake is treating the vector index as the source of truth. The index should usually be viewed as a retrieval structure derived from canonical data. Source documents, permissions, lifecycle state, and version history should live in a reliable system that the application can check. This makes it possible to reject stale or unauthorized retrieved chunks before they reach the model.
A third mistake is handling deletes as an afterthought. In RAG systems, stale deleted content can be more damaging than missing new content. Missing a new document may produce an incomplete answer, but citing a deleted or access-revoked document can violate user expectations and governance rules. Deletes and permission changes should have stricter handling than ordinary content updates when the risk is higher.
Teams also sometimes evaluate RAG quality only on stable test sets. That misses freshness failures that appear during live updates. A more useful evaluation includes update-sensitive tests: add a document, query immediately, update it, query again, delete it, and confirm that retrieval and generation follow the expected state at each step.
Avoiding these mistakes brings the discussion back to the core idea: consistency is not only a database label. It is a promise that must line up with user workflows, retrieval behavior, and the freshness of generated answers. The clearer that promise is, the easier it becomes to design a RAG system that users can trust.
FAQs
1. What is eventual consistency in a vector database?
Eventual consistency means a write, update, or delete may not be visible to every query immediately after it is accepted. The system is expected to converge so later reads reflect the latest state, but there can be a short period where vector search, metadata filtering, or replicas still show older data.
2. What is strong consistency in a vector database?
Strong consistency means reads reflect completed writes according to the database’s stated guarantee. In vector databases, it is important to check whether that guarantee applies only to direct object reads or also to vector search, hybrid search, metadata filters, and replicated indexes.
3. Why might a new vector not appear in search immediately?
A new vector may be stored before it is fully inserted into the searchable index. The database may batch index updates, refresh query-visible snapshots on an interval, propagate changes across replicas, or wait for background processes. This delay is normal in many eventually consistent retrieval systems.
4. Does read-after-write consistency matter for RAG?
Yes. Read-after-write consistency matters when users expect new, changed, or deleted content to affect the next AI answer. Without it, a RAG system may miss a newly uploaded document, cite an outdated version, or retrieve content that should no longer be used.
5. Can RAG be fresh if the vector database is eventually consistent?
Yes, but the application needs to manage the freshness window. It can wait for indexing completion, search a fresh-write buffer, track chunk versions, validate sources before generation, and monitor indexing lag. Eventual consistency is workable when the delay is understood and controlled.
6. What consistency guarantee is best for sensitive RAG applications?
Sensitive RAG applications usually need stronger guarantees around deletes, permissions, and user-visible updates. This does not always require strict consistency for every query, but it does require source-of-truth validation, version checks, and clear rules that prevent stale or unauthorized chunks from reaching the model.
Takeaway
Consistency models in vector databases define how quickly writes, updates, deletes, and index changes become visible to retrieval. Eventual consistency can support scalable, fast search when a short freshness delay is acceptable, while stronger consistency or freshness gating is better for workflows where users expect immediate correctness after an upload, edit, delete, or permission change. This guidance is most useful for teams building RAG systems, AI search, and live knowledge retrieval applications where the practical use case is not just finding similar content, but generating answers from the right version of the right content at the right time.